阅读笔记联邦学习实战——用FATE从零实现纵向线性回归
Posted HERODING23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阅读笔记联邦学习实战——用FATE从零实现纵向线性回归相关的知识,希望对你有一定的参考价值。
联邦学习实战——用FATE从零实现纵向线性回归
前言
FATE是微众银行开发的联邦学习平台,是全球首个工业级的联邦学习开源框架,在github上拥有近4000stars,可谓是相当有名气的,该平台为联邦学习提供了完整的生态和社区支持,为联邦学习初学者提供了很好的环境,否则利用python从零开发,那将会是一件非常痛苦的事情。本篇博客内容涉及《联邦学习实战》第六章内容,使用的fate版本为1.6.0,fate的安装已经在这篇博客中介绍,有需要的朋友可以点击查阅。下面就让我们开始吧。
1. 数据集的获取
本次实战使用的数据集为波士顿房价预测数据集,并且已经内置在sklearn库中,可以直接加载查看。前五组数据查看如下:

其中y表示房屋的均值价格。
2. 纵向数据集切分
从数据集中抽取前460条数据作为训练数据,将后面100条作为评估测试数据。
- 训练数据集切分:从460条训练数据中随机抽取360条数据和前8个特征作为公司A的本地数据,文件保存为
housing_1_train.csv。同样,从这406条训练数据中抽取380条数据和后5个特征,以及标签y,作为公司B的本地数据,文件保存为housing_2_train.csv。 - 测试数据集切分:从100条评估测试数据中随机抽取80条数据和前前8个特征作为公司A的本地测试数据,文件保存为
housing_1_eval.csv。再从这100条测试数据中抽取85条数据和后5个特征,以及标签y,作为公司B的本地测试数据,文件保存为housing_2_eval.csv。
切分代码如下:
from sklearn.datasets import load_boston
import pandas as pd
# 导入并查看数据
boston_dataset = load_boston()
boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names)
boston.head()
# z-score标准化
boston = (boston - boston.mean()) / (boston.std())
# 处理属性名
col_names = boston.columns.values.tolist()
columns =
for idx, n in enumerate(col_names):
columns[n] = "x%d"%idx
boston = boston.rename(columns=columns)
# 插入每行序号和y
boston['y'] = boston_dataset.target
idx = range(boston.shape[0])
boston.insert(0, 'idx', idx)
# 打乱数据生成csv
boston = boston.sample(frac=1)
train = boston.iloc[:406]
eval = boston.iloc[406:]
housing_1_train = train.iloc[:360,:9]
# 再次打乱训练数据
train = train.sample(frac=1)
housing_2_train = train.iloc[:380,[0,9, 10, 11, 12, 13, 14]]
housing_1_eval = eval.iloc[:80,:9]
# 再次打乱测试数据
eval = eval.sample(frac=1)
housing_2_eval = eval.iloc[:85,[0,9, 10, 11, 12, 13, 14]]
housing_1_train.to_csv('housing_1_train.csv', index=False, header=True)
housing_2_train.to_csv('housing_2_train.csv', index=False, header=True)
housing_1_eval.to_csv('housing_1_eval.csv', index=False, header=True)
housing_2_eval.to_csv('housing_2_eval.csv', index=False, header=True)
按照上述方案切分后,最终两家公司的用户数据交集为85%左右,而测试集的用户交集大约为68%。这里要注意FATE中的数据一定要插入标签,否则第一列会被当作标签,并且在纵向联邦学习寻找标签交集的时候会因为第一列不是标签而是数据无法对齐,出现Count of data_instance is 0的错误。
3. 纵向联邦训练
纵向联邦训练通常涉及以下四项工作:
- 数据输入:将文件转换为FATE支持的DTable格式。
- 样本对齐:纵向联邦学习特有的工作。找出用户交集,才能进行模型训练。
- 模型训练:求取交集数据,进行纵向联邦模型训练。
- 模型评估:模型评估数据分布在两个参与方中,所以模型评估需要联合双方才能进行。
3.1 数据输入
在xshell中进入到fate的docker环境,输入
$ rz -be
将本地生成的csv文件上传到example/data中。
定义上传数据配置文件,将其命名为upload_data.json,以处理housing_1_train.json文件为例,配置文件如下:
"file": "/fate/example/data/housing_1_train.csv",
"head": 1,
"partition": 8,
"work_mode": 0,
"table_name": "homo_housing_1_train",
"namespace": "homo_host_housing_train"
在/fate位置下输入:
python python/fate_flow/fate_flow_client.py -f upload -c upload_data.json
输出如下即上传成功:
"data":
"board_url": "http://127.0.0.1:8080/index.html#/dashboard?job_id=202203150220403776101&role=local&party_id=0",
"job_dsl_path": "/fate/jobs/202203150220403776101/job_dsl.json",
"job_id": "202203150220403776101",
"job_runtime_conf_on_party_path": "/fate/jobs/202203150220403776101/local/job_runtime_on_party_conf.json",
"job_runtime_conf_path": "/fate/jobs/202203150220403776101/job_runtime_conf.json",
"logs_directory": "/fate/logs/202203150220403776101",
"model_info":
"model_id": "local-0#model",
"model_version": "202203150220403776101"
,
"namespace": "homo_host_housing_eval",
"pipeline_dsl_path": "/fate/jobs/202203150220403776101/pipeline_dsl.json",
"table_name": "homo_housing_1_eval",
"train_runtime_conf_path": "/fate/jobs/202203150220403776101/train_runtime_conf.json"
,
"jobId": "202203150220403776101",
"retcode": 0,
"retmsg": "success"
重复上述操作将另外三个csv文件上传即可。其余三个配置文件如下:
"file": "/fate/example/data/housing_2_train.csv",
"head": 1,
"partition": 8,
"work_mode": 0,
"table_name": "homo_housing_2_train",
"namespace": "homo_guest_housing_train"
"file": "/fate/example/data/housing_1_eval.csv",
"head": 1,
"partition": 8,
"work_mode": 0,
"table_name": "homo_housing_1_eval",
"namespace": "homo_host_housing_eval"
"file": "/fate/example/data/housing_2_eval.csv",
"head": 1,
"partition": 8,
"work_mode": 0,
"table_name": "homo_housing_2_eval",
"namespace": "homo_guest_housing_eval"
3.2 样本对齐
样本对齐旨在不泄露双方数据的前提下,求取双方用户的交集,从而确定模型训练的训练数据集。
FATE提供多方安全的样本对齐算法,算法基于RSA加密算和散列函数,利用FATE建模时,不需要自己实现样本对齐算法,FATE为模型训练提供了样本对齐的接口。具体的实现将在以后的博客中阐述。
3.3 模型训练
在FATE框架下,模型训练的本质就是修改dsl.json和conf.json两个文件,进入$fate_dir/examples/dsl/v1/hetero_linear_regression目录中,该目录下已经有很多定义好的dsl和conf配置文件,修改下面两个文件。
- test_hetero_linr_train_job_dsl.json:用来描述任务模块,将任务模块以有向无环图形式组合到一起。
- test_hetero_linr_train_job_conf.json:用来设置各个组件的参数,比如输入模块的数据表名,算法模块的学习率、batch大小、迭代次数等。
首先查看dsl配置文件,定义了四个组件模块:
- dataio_0:数据I/O组件,用于将本地数据转换为DTable。
- intersection_0:样本对齐组件、用于求取双方的数据交集。
- hetero_linr_0:纵向线性回归模型组件。
- evaluation_0:模型评估组件。如果没有提供测试数据集,则将自动使用训练数据集作为测试数据集。

查看conf文件,需要修改两处地方。
-
role_parameters字段:修改name和namespace,以及label_name,表示的是标签页对应的属性名。
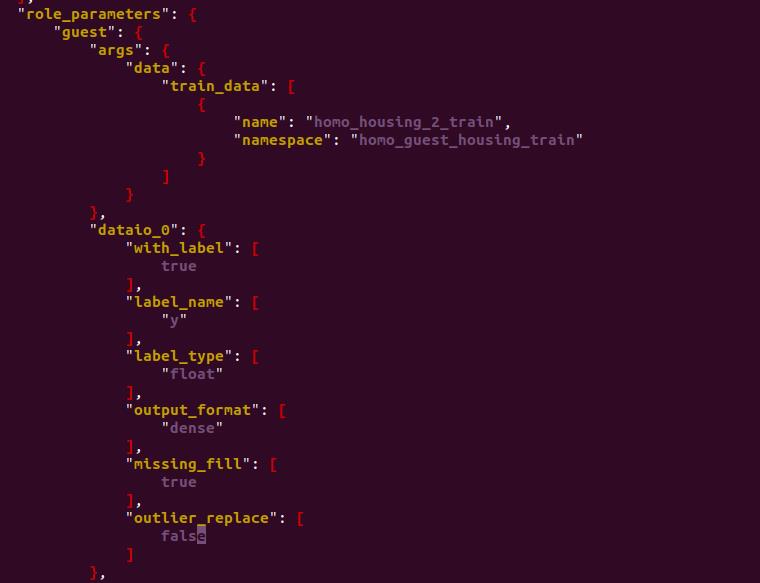
-
algorithm_parameters字段:设置模型训练的超参数信息。

运行后在FATEboard上的结果如下:


3.4 模型评估
在FATE中,如果仅仅提供了模型训练的数据信息,模型评估使用的是训练数据。如果用独立的测试数据,需要添加新的数据模块。
-
修改dsl文件,需要在dsl中增加新的测试数据输入模块dataio_1和测试数据样本对齐模块intersection_1。


此外还有模型训练和评估模块:


注意模块都是相互对应的,上一个模块的输出会是下一个模块的输入,千万别弄错了。 -
接下来是修改conf配置文件,添加品古测试数据集表明和命名空间。

 此外,还要注意评估模块
此外,还要注意评估模块evaluation_1,确定评估类型和pos_label,否则会报错Only one class present in y_true. ROC AUC score is not defined in that case。
任务模块之间的有向无环图组合如下:
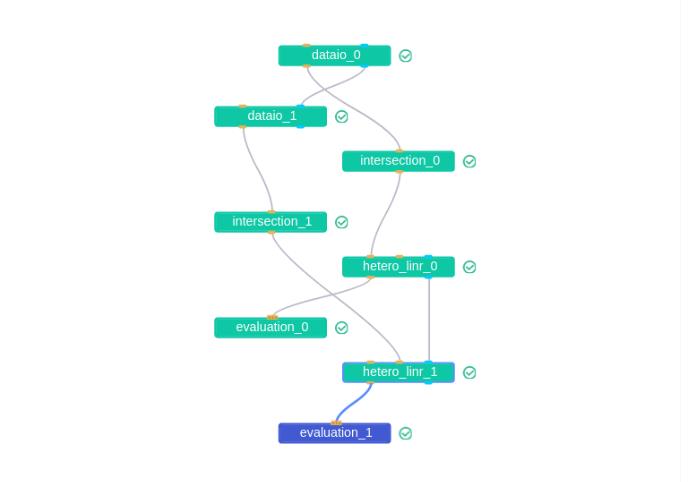
评估结果如下:

阅读总结
花了一天时间,总算是把这一章的代码复现出来,这可能是CSDN上第一篇《联邦学习实战》第六章内容的复现,在没有任何参考的情况下,以及书籍中部分内容描述不清,在复现的时候遇到了许多坑,比如数据标签不插入就没法数据对齐(原书跳过了该步骤),原书中部分name和namespace不对应需要自己注意,原书中评估模块缺少了后面的hetero_linr_1和evaluation_1两部分,需要自己添加,以及原书中评估部分的conf.json中,不加上evaluation_1的参数配置是跑不通代码的。所有这些都让我对FATE有了进一步的理解与认识,希望这篇博客能对部分读者有一定的帮助吧。
以上是关于阅读笔记联邦学习实战——用FATE从零实现纵向线性回归的主要内容,如果未能解决你的问题,请参考以下文章