2022年深圳杯A题破除“尖叫效应”与“回声室效应”走出“信息茧房”
Posted 数模竞赛Paid answer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2022年深圳杯A题破除“尖叫效应”与“回声室效应”走出“信息茧房”相关的知识,希望对你有一定的参考价值。
2022年深圳杯A题破除“尖叫效应”与“回声室效应”走出“信息茧房”
一.背景与意义
“尖叫效应”是心理学中的一个著名效应。例如在一个人潮涌动的公众场合,如果有人突然歇斯底里地尖叫,往往能快速吸引人们的注意力并博取眼球。在网络信息传播中,“尖叫效应”也无处不在。一些网络平台利用大数据和人工智能,获取并分析用户浏览记录和兴趣爱好等信息,大量推送段子、恶搞、色情等低俗内容。无论是从满足人们的猎奇心理,还是引发人们的指责批评,传播者都能从中获取高额的流量和点击率。
“回声室效应”指的是在一个相对封闭的媒体环境中,一些意见相近的声音不断重复,甚至夸张扭曲,令处于其中的大多数人认为这些声音就是事实的全部, 不知不觉中窄化自己的眼界和理解,走向故步自封甚至偏执极化。在现代社会中,由于互联网以及社交媒体的发展,在网络信息传播中“回声室效应”愈发明显。部分商业网站会分析记录用户的搜寻结果以及使用习惯,持续地将一位用户所喜欢的内容提供给该用户,导致一个人在同一网站中接受到的资讯被局限于某个范围内。
“尖叫效应”与“回声室效应”容易导致“信息茧房”的形成。所谓“信息茧房”指的是,在信息传播中人们自身的信息需求并非全方位的,只会选择自己想要的或能使自己愉悦的信息,久而久之接触的信息就越来越局限,最终将自己桎梏于像蚕茧一般的“茧房”中,失去对其他不同信息的了解能力和接触机会。
二.需回答的问题
在全新的信息传播格局下,如何破除“尖叫效应”与“回声室效应”,走出“信息茧房”,是当前迫切需要解决的现实问题,即如何从信息传输的顶层设计、推荐算法的公平性和广大网络用户的责任担当等方面,帮助公众对新闻事件乃至社会现实有一个相对准确、清晰的认识和判断,并在主流意识和个性化信息之间找到平衡点,使得网络舆论环境更具理性和建设性。请回答以下问题:
1. 针对某些话题,在微信、微博、Facebook 和 Twitter 等社交媒体上下载相关数据,定量描述该话题(或信息)的传播过程,并分析其影响因素。该数据分析需至少针对两种不同的话题展开讨论,其中一个话题最终观点趋于相同(中立共识),另一话题最终观点趋于两极分化(观点极化)。
2. 建立数学模型刻画中立共识和观点极化的产生机制,探索“尖叫效应”、“回声室效应”与“信息茧房”的形成机制,并讨论话题的吸引度、用户的活跃度、用户心理、不同用户间的相互影响、平台推荐算法等因素对形成这些现象的影响。
3. 根据问题 2 建立的数学模型,制定破除“尖叫效应”和“回声室效应”、规避“信息茧房”的策略。
4. 基于上述数据分析与数学模型,针对如何破除“信息茧房”撰写 1~2 页报告,分别对政府的顶层设计、主流媒体的引领和广大网络用户的责任担当提出相应的解决方案或建议。
三.数据来源
1. 参考数据: 爬取的数据是在社交网站 reddits 上话题中含有关于堕胎(abortion)和枪支管控(gun control)部分话题(submissions)的内容以及评论(comments)。(也可自己爬取相应的数据 ,如 2 ,3)
2. 微信、微博、Facebook 和 Twitter 等社交媒体的原始数据
3. 新闻媒体的标签数据库(MBFC)(https://mediabiasfactcheck.com)

图1 尖叫效应示例图

图2 回声室效应示例图

图3 信息茧房示例图
问题分析及模型的建立与求解
问题一分析:
我在此处举两个例子:
例子1
比如说一首音乐,有的人觉得好听,有的人觉得真难听好土,还有的人说还可以但是某些方面需要加强;
1) 使用调查问卷来获取评论者们是否为具有音乐专业知识的人员;
2) 使用调查问卷来获取评论者们的喜好音乐的风格;
3) 使用调查问卷来获取评论者们是否为该音乐发布者的粉丝,是黑粉还是真的粉丝;
4) 评论内容信息是否有关于该音乐的真实有效信息。(比如说演奏音乐这相貌美丽性感出奇,而评论者内容与音乐本身不符的情况)。
从这四个角度出发进行,得到褒奖、贬低、中立的占比情况(环形图)及影响关系拟合曲线图,这四个因素权重占比最大的是哪个?会得出哪些具体结论?比如说这个演奏者本身不是音乐爱好者或非专业音乐人,只是通过该音乐获取流量博人眼球则贬低和中立评论占比较大;如果该演奏者具有专业音乐知识及爱好音乐,目的为让大家欣赏音乐,则褒奖和中立评论占比较大。
例子2
男子跪地求复合 这种社会客观存在事实
评论区依然是三边说 一男生是舔狗 男生好极端 男生好不要脸 人在舔中不知舔 回首已是犬中犬
二 女生好绝情 为该女生不值得
三 男生没必要 好聚好散 女生和好吧
1) 使用调查问卷来获取评论者们的年龄;
2) 使用调查问卷来获取评论者们的感情经历是否经历过爱情;
这就是一个二分类数据:是 否
3) 使用调查问卷来获取评论者们的学历水平;
比如说小学 初中 高中 本科 大学 硕士 博士
4) 使用调查问卷来获取评论者们的性别;
5) 使用调查问卷来获取评论者们的经济水平。
比如说分层次: 4k以下 4k到6k 6k到8k 8k以上
从这5个角度出发进行,得到支持男方、女方、中立的占比情况(环形图)及影响关系拟合曲线图,这5个因素权重占比最大的是哪个?会得出哪些具体结论?比如说针对男青年,可能支持男方和中立评论占比较大;针对高学历经济水平高的人群,则中立评论占比较大。
数据可视化 该怎么做你们应该都知道
#导入必要的库
import wordcloud as wc
import random
import jieba
from PIL import Image
import numpy as np
#打开文本文件text.txt
with open("text.txt",mode="r",encoding="utf-8") as fp:
content = fp.read()
res = jieba.lcut(content)
text = " ".join(res)
#设置背景形状图片
mask = np.array(Image.open("fivestar.png"))
#设置停用词
stopwords = set()
content = [line.strip() for line in open('stopwords.txt','r').readlines()]
stopwords.update(content)
#画图
word_cloud = wc.WordCloud(font_path="C:WindowsFontsmsyh.ttc",mask=mask,stopwords = stopwords)#字体、背景形状
word_cloud.generate(text)
word_cloud.to_file("a.png")#绘制到一个图片里
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from matplotlib import rcParams
config =
"font.family": 'STSong',
"font.size": 12,
"mathtext.fontset": 'stix',
"font.serif": ['STSong'],
rcParams.update(config)
fig=plt.figure(figsize=(8,4))#调整画布大小
N = 7
y1 = (15,17.22,19.63,30.24,34.49,40.84,70.5)
y2 = (17.14,14.26,15.71,25.08,22.85,23.61,23.5)
d = []
for i in range(0, len(y2)):
sum = y1[i] + y2[i]
d.append(sum)
y3 = (30.3,39.8,32.97,22.9,20,20.45,6)
d2 = []
for i in range(0, len(y2)):
sum = y1[i] + y2[i] +y3[i]
d2.append(sum)
y4=(28.36,19.82,24.49,12.98,12.94,10,0)
d3 = []
for i in range(0, len(y2)):
sum = y1[i] + y2[i] +y3[i] +y4[i]
d3.append(sum)
y5=(9.2,8.9,7.2,8.8,9.72,5.1,0)
# menStd = (2, 3, 4, 1, 2)
# womenStd = (3, 5, 2, 3, 3)
x = (1,2,3,4,5,6,7) # the x locations for the groups
width = 0.35 # the width of the bars: can also be len(x) sequence
p1 = plt.barh(x, y1, width, color='#d62728') # , yerr=menStd)
p2 = plt.barh(x, y2, width, left=y1) # , yerr=womenStd)
p3 = plt.barh(x, y3, width, left=d)
p4= plt.barh(x, y4, width, left=d2)
p5= plt.barh(x, y5, width, left=d3,color='#7B7B7B')
plt.xlabel('位置精度区间分布(%)')
plt.ylabel('定位方式')
#plt.title('Scores by group and gender')
plt.yticks(x, ('百度 _G','腾讯 _G','高德 _G','百度 _S','腾讯 _S','高德 _S','所提方法'))
plt.xticks(np.arange(0, 110, 10))
plt.grid(which='major',axis='x',linestyle='dotted')
#plt.legend((p1[0], p2[0], p3[0],p4[0], p5[0]), ('[0,50 m]', '(50 m, 200 m]', '(200 m, 500 m]','(500 m, 1000 m]','(1000 m, ∞)'))
plt.legend((p1[0], p2[0], p3[0],p4[0], p5[0]), ('[0,50 m]', '(50 m, 200 m]', '(200 m, 500 m]','(500 m, 1000 m]','(1000 m, ∞)'),ncol=5,bbox_to_anchor=(0.5, -0.1), loc=8, borderaxespad=-3,frameon=False,handlelength=0.7)
plt.show()
fig.savefig('jingdu81.jpg',bbox_inches='tight')
通过调查问卷,我们收集的部分数据如附件.xlsx所示
由于数据没有归类,且男性数据普遍较少,我们先进行女性数据的划分
我们将28岁以下,有感情经历的女性定义为有感情经历的女青年
将32岁以上,有感情经历的女性定义为中年女性。同时为了有所区分,我们多增加了一项指标婚姻状况来划分,从所得数据中可以看出中年未婚女性与已婚女性看法近似一致
将28岁以下,没有感情经历的女性定义为无感情经历的女青年
我们将数据分别提取出来,分别以年龄与经济收入绘制拟合曲线图,同时绘制各学历占比环形统计图
年龄和收入曲线图给我们一种更直观地去分析经济独立与看法的关系,同时环形图与饼状图可以更好给出,不同年龄段女性的学历水平,从而可以站在一个更好的角度去分析知识水平对此现象看法的影响
数学公式在这里不给出了
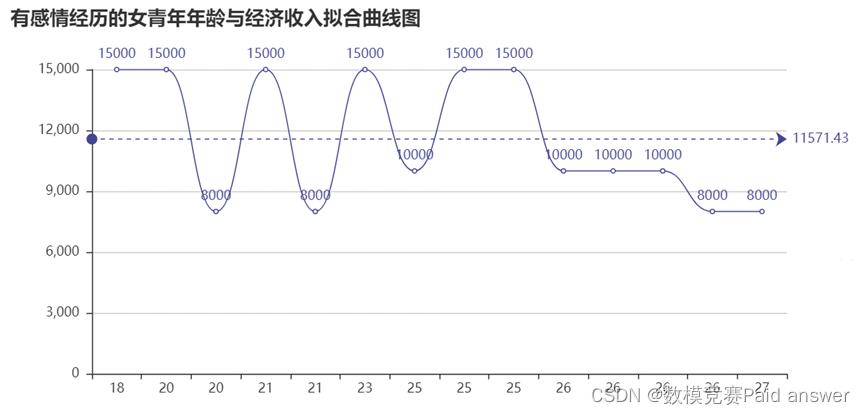

没感情经历的女生反而更容易恋爱脑,我们收集的数据中,这类女生的工资收入还可以,但年龄较低。在这样的条件下,她们不会轻易去更换自己的伴侣,希望通过调解去缓和这段关系,并且也不愿意过多伤害男方,通过分析可知有60%的人选择支持(同情男方)。
由于经济收入数据相对较少,且差距不算大,分析效果不是很明显。所以我们又分别绘制了她们各自的圆环、饼状图,更好地看出占比关系,从而得到更加精确的结论。


针对男青年,支持男方和中立评论占比较大;针对高学历经济水平高的人群,则中立评论占比较大;针对中年有感情经历女性,则支持女方评论占比较大。
针对于该感情纠纷话题,支持不同方的影响因素主要为年龄、是否有感情经历、性别、学历、经济收入,对于不同的人群,他们的观点见解也不一致。
问题二怎么处理呢?
“信息茧房”的形成是平台通过推荐算法不断地从用户中数据挖掘相似的阅读规律导致的,并以“朋友圈”进行推荐,致使每个“圈”内的用户彼此志趣相投。
理想化准则:
(1)算法中的所有信息传递者都不分性别、年龄及其他因素,即信息传递者之间的吸引只基于信息内容,不考虑性别的影响。
(2)信息与信息被吸引者之间的吸引力和信息热度成正比,信息热度越大,吸引力越强。且两者都将随着时间的推逝而减小。因此对于任意信息传递者,不了解该信息的信息读者会向热度大的信息移动,热度最大的信息将随机移动。
(3)信息的热度与待优化目标函数的值有关。
由于信息传递范围的增加和读者对信息的吸收,信息i的热度会随着距离r的增加而增大而非减小。为了对信息与读者之间的相互吸引力进行建模,这里首先给出信息绝对热度和相对热度的定义。
假设目前有M个信息读者,共有N条信息。信息读者与信息的关系如下图所示:


问题三四模型的建立与求解:
制定破除“尖叫效应”和“回声室效应”、规避“信息茧房”的策略。
针对破除“尖叫效应”和“回声室效应”的策略:
(1) 在某一信息点击量或访问量达到一定的条件时,应加入信息审核算法,判别该信息是否符合正确的社会价值观引导;
(2) 使用关键词库判别发布的信息是否含有夸大虚拟词汇,与现实不符;
(3) 使用文本分类算法,如段子、色情、恶搞等低俗内容将尖叫效应下获得的流量信息标签,限制其发布;
(4) 对于非原创作者发布的相同类似信息进行限制流量处理。
还写了好多的策略 这里就不一一写了 大家都会写 篇幅我这里就不写太长了

A题的解题过程就全部写完了 接下来看看C题的难度如何
以上是关于2022年深圳杯A题破除“尖叫效应”与“回声室效应”走出“信息茧房”的主要内容,如果未能解决你的问题,请参考以下文章