本周优秀开源项目分享:基于yolov3的轻量级人脸检测增值税发票OCR识别 等8大项目
Posted 七月在线实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了本周优秀开源项目分享:基于yolov3的轻量级人脸检测增值税发票OCR识别 等8大项目相关的知识,希望对你有一定的参考价值。
yolo-face-with-landmark 使用pytroch实现的基于yolov3的轻量级人脸检测

实现的功能:
添加关键点检测分支,使用wing loss。
安装和使用:
git clone https://github.com/ouyanghuiyu/yolo-face-with-landmark
使用src/retinaface2yololandmark.py脚本将retinaface的标记文件转为yolo的格式使用
使用src/create_train.py 创建训练样本
测试:
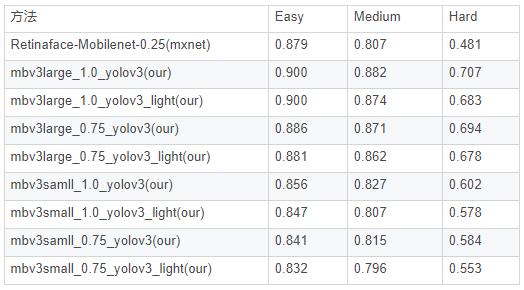
在wider face val精度(单尺度输入分辨率:320*240)
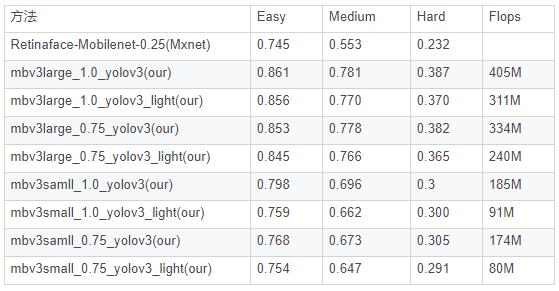
在wider face val精度(单尺度输入分辨率:640*480)
https://github.com/ouyanghuiyu/yolo-face-with-landmark
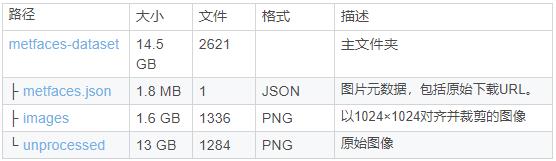
metfaces-dataset 从艺术品中提取的人脸图像数据集

MetFaces是从艺术品中提取的人脸图像数据集,最初是我们在以下方面的工作之一:
用有限的数据训练生成对抗网络
该数据集包含1336个分辨率为1024×1024的高质量PNG图像。这些图像是通过大都会艺术博物馆收藏的API下载的,并使用dlib自动对齐和裁剪。各种自动过滤器用于修剪设备。
所有数据都托管在Google云端硬盘上:
https://github.com/NVlabs/metfaces-dataset
invoice 增值税发票OCR识别
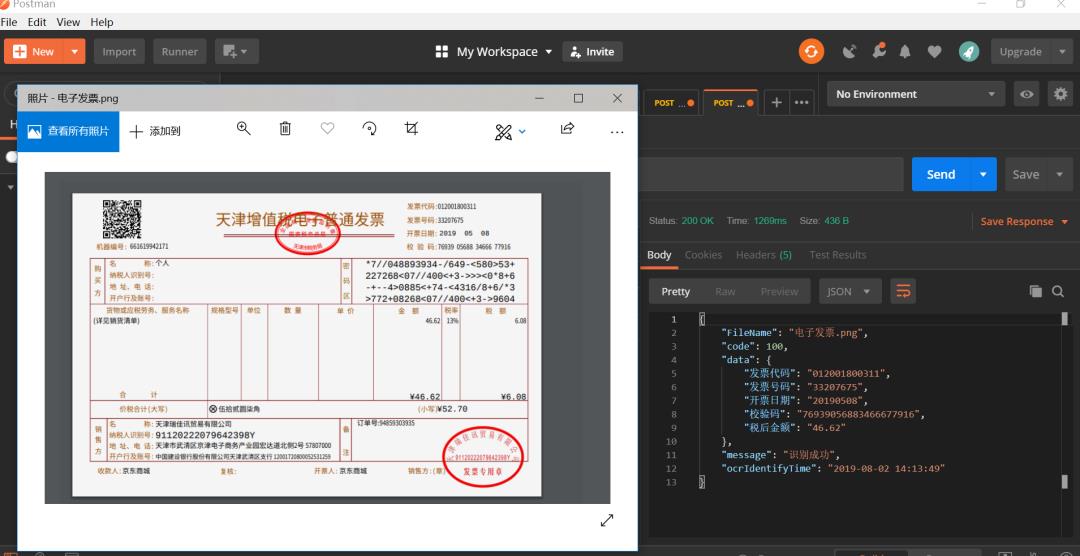
增值税发票OCR识别,使用flask微服务架构,识别type:增值税电子普通发票,增值税普通发票,增值税专用发票;识别字段为:发票代码、发票号码、开票日期、校验码、税后金额等。
环境:
python3.5/3.6
依赖项安装:
pip install -r requirements.txt -i
https://pypi.tuna.tsinghua.edu.cn/simple
模型架构:
Y0L0v3+CRNN+CTC
模型:
https://pan.baidu.com/s/1bjtd3ueiUj3rt16p2_YQ2w
将下载完毕的模型文件夹models放置于项目根目录下。
服务启动:
python3 app.py
http://...: [端口号]/invoice-ocr,例:http://127.0.0.1:11111/invoice-ocr
https://github.com/guanshuicheng/invoice
以下是无监督学习,自监督学习和表象学习之间的关系。此项目专注于阴影区域,即无监督的表示学习。自监督的表示学习是它的主要分支。
由于在很多情况下,我们不会严格区分自监督表示学习和无监督表示学习,因此我们仍将此项目称为OpenSelfSup。
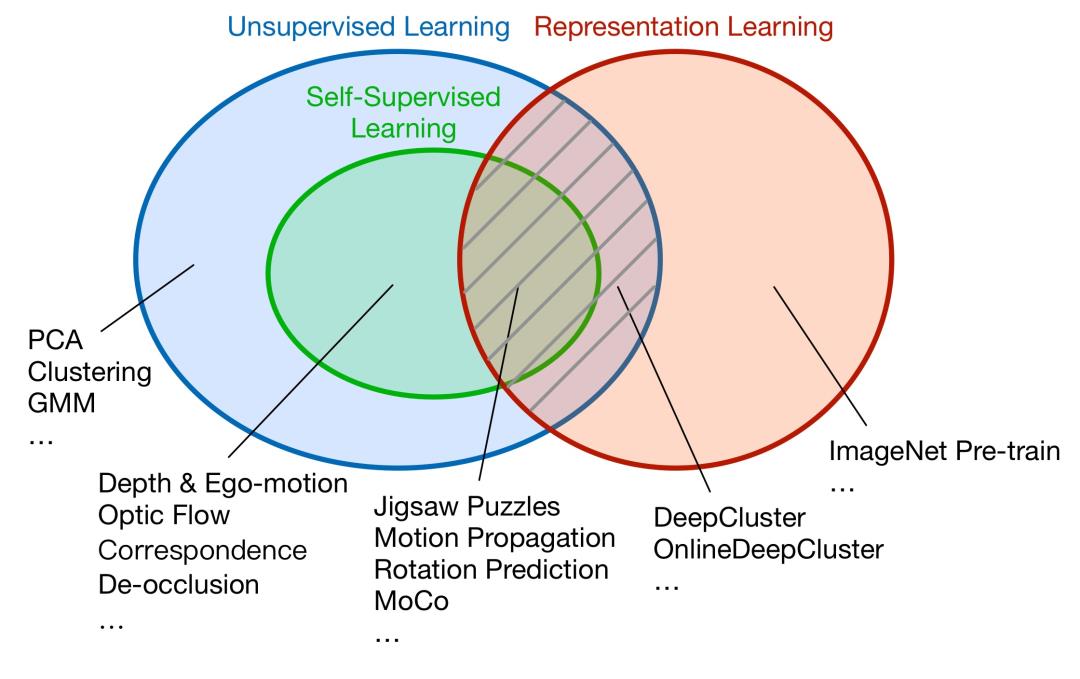
主要特征:
所有方法都在一个存储库中
灵活性和可扩展性 OpenSelfSup遵循MMDetection的类似代码体系结构,但比MMDetection更加灵活,因为OpenSelfSup集成了各种自我监督的任务,包括分类,联合聚类和特征学习,对比学习,带有存储库的任务等。
效率 所有方法都支持多机多GPU分布式训练。
标准化基准 对基准进行了标准化,包括逻辑回归,线性探测特征的SVM /低速SVM,半监督分类和对象检测。
https://github.com/open-mmlab/OpenSelfSup
detectron2 对象检测和分割平台
Detectron2是Facebook AI Research的下一代软件系统,可实现最新的对象检测算法。它是对先前版本Detectron的完全重写,它源自maskrcnn-benchmark。

特性:
由PyTorch深度学习框架提供支持。
包括更多功能,例如全景分割,密集姿势,Cascade R-CNN,旋转边界框等。
可用作库来支持基于它的不同项目。我们将以这种方式开源更多的研究项目。
训练得更快。
通常会根据对ImageNet分类任务进行预训练的骨干模型进行初始化。提供以下主干模型:
R-50.pkl:MSRA原始ResNet-50模型的转换副本。
R-101.pkl:MSRA原始ResNet-101模型的转换副本。
X-101-32x8d.pkl:在FB用Caffe2训练的ResNeXt-101-32x8d模型。
R-50.pkl(torchvision):Torchvision的ResNet-50模型的转换副本。
https://github.com/facebookresearch/detectron2
person-reid-3d 3D空间中的人员重新识别
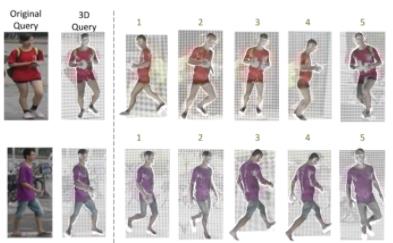
系统需求:
Python 3.6 or 3.7
GPU Memory >= 4G (e.g., GTX1080)
Pytorch = 1.4.0
dgl
效果:

https://github.com/layumi/person-reid-3d
neoml 深度学习和传统算法的机器学习框架
NeoML是一个端到端的机器学习框架,可让您构建,训练和部署ML模型。ABBYY工程师将该框架用于计算机视觉和自然语言处理任务,包括图像预处理,分类,文档布局分析,OCR以及从结构化和非结构化文档中提取数据。
关键特性:
支持100多种图层类型的神经网络
传统机器学习:20多种算法(分类,回归,聚类等)
CPU和GPU支持,快速推断
ONNX支持
语言:C++,Java,Objective-C
支持平台:
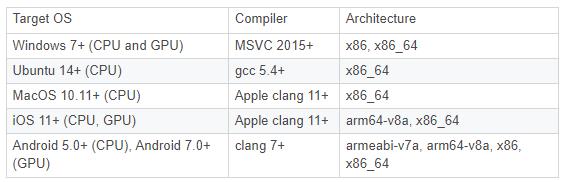
https://github.com/neoml-lib/neoml
AlphaVideo 用于视频相关任务的视觉工具箱,包括动作识别,多对象跟踪
AlphaVideo是基于PyTorch的开源视频理解工具箱,涵盖多对象跟踪和动作检测。
在AlphaVideo中,我们发布了第一个单阶段多目标跟踪(MOT)系统TubeTK,该系统可以在MOT-16数据集上实现66.9 MOTA,在MOT-17数据集上实现63 MOTA。
对于动作检测,我们发布了一个有效的模型AlphAction,这是第一个开源项目,在AVA数据集上使用单个模型即可达到30+ mAP(32.4 mAP)。

特性与功能:
多目标追踪 提供了TubeTK模型,该模型是论文“ TubeTK:在一步式训练模型(CVPR2020,口头)中采用管来跟踪多目标”的正式实现。
精确的端到端多对象跟踪。
不需要任何现成的图像级对象检测模型。
行人跟踪的预训练模型。
输入:帧列表;视频。
输出:用彩色边框装饰的视频;Btube列表。
动作识别 提供AlphAction模型作为论文“用于动作检测的异步交互聚合”的实现。
准确而有效的动作检测。
针对AVA中定义的80种原子作用类别的预训练模型。
输入:视频;相机。
输出:由人为盒子装饰的视频,并附有相应的动作预测。
https://github.com/Alpha-Video/AlphaVideo
七月在线【AI攻城狮超车季】,集训营、就业小班 课程 限时免费开放,还有 VIP会员年卡、机械键盘、技术书免费送!
8大重磅课程免费学,先送你几节课,扫码免费领(无转发、无套路扫码直接领一节):
扫码免费学 以上是关于本周优秀开源项目分享:基于yolov3的轻量级人脸检测增值税发票OCR识别 等8大项目的主要内容,如果未能解决你的问题,请参考以下文章 本周AI领域优秀开源项目分享,Transformer推理工具医疗影像AI工具包等 6大开源项目