干货本周AI领域优秀开源项目和优秀论文分享!
Posted 七月在线实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货本周AI领域优秀开源项目和优秀论文分享!相关的知识,希望对你有一定的参考价值。
项目一:使用Cityscapes进行语义分割的PyTorch代码库
项目二:PaddleX 『飞桨』深度学习全流程开发工
项目三:用于以向量化方式进行时间序列平滑和离群值检测的python库
项目四:RecBole 统一,全面,高效的推荐库
项目五:Hub TensorFlow / PyTorch最快的非结构化数据集管理
semantic-segmentation-tutorial-pytorch 使用Cityscapes进行语义分割的PyTorch代码库
使用PyTorch的语义分割教程。基于2020 ECCV VIPriors Challange起始代码,实现了语义分段代码库并添加了一些技巧。
下载数据集(来自CityScapes的MiniCity):
我们将使用Cityscapes的MiniCity数据集。此数据集用于2020 ECCV VIPriors挑战。
数据集下载(Google驱动器)
https://drive.google.com/file/d/1YjkiaLqU1l9jVCVslrZpip4YsCHHlbNA/view?usp=sharing 将数据集移动到minicity文件夹中。
训练基线模型:
使用来自torchvision的DeepLabV3。
ResNet-50骨干网,ResNet-101骨干网
使用4个RTX 2080 Ti GPU。(11GB x 4)
损失函数:
尝试了3种损失函数。
交叉熵损失
类加权交叉熵损失
焦点损失
可以使用--loss参数选择损失函数。
归一化层:
尝试了4归一化层。
批次归一化(BN)
实例规范化(IN)
组归一化(GN)
不断发展的标准化(EvoNorm) 可以使用--norm参数选择归一化层。
增强技巧:
提出2种数据增强技术(CutMix,copyblob)
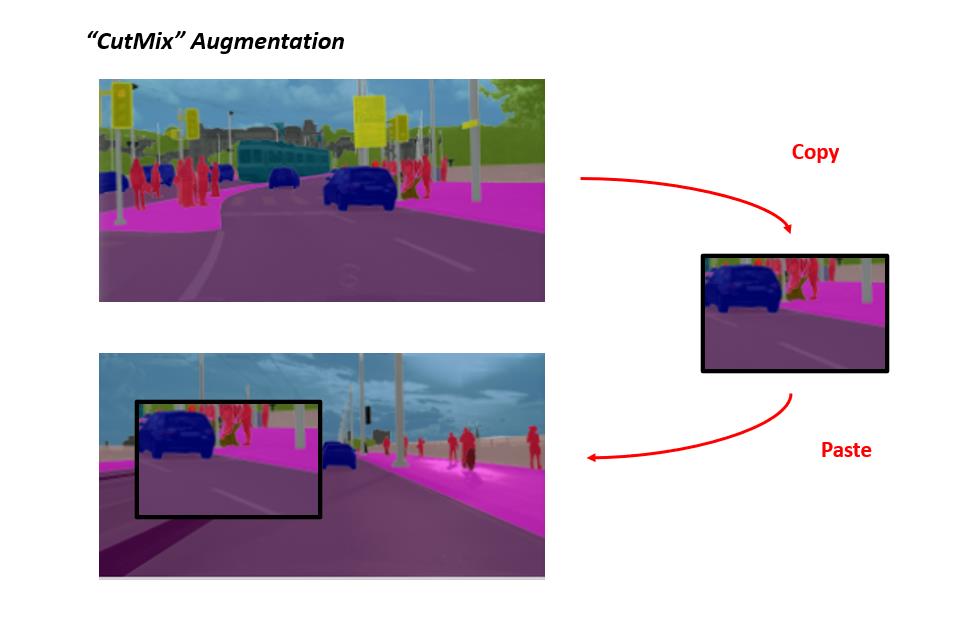
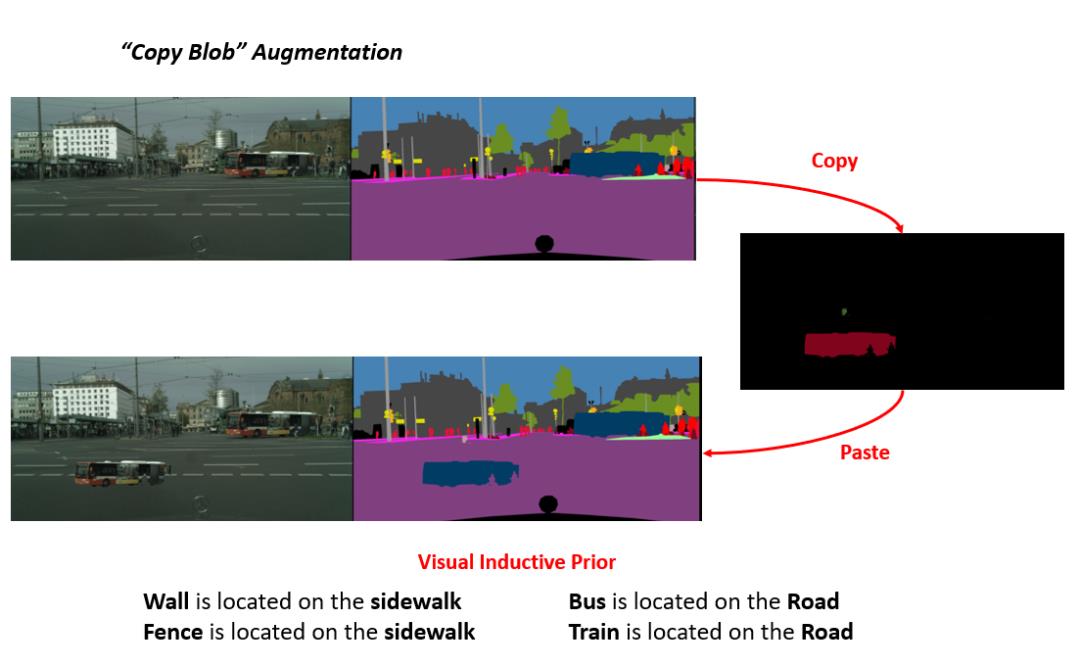
模型效果:
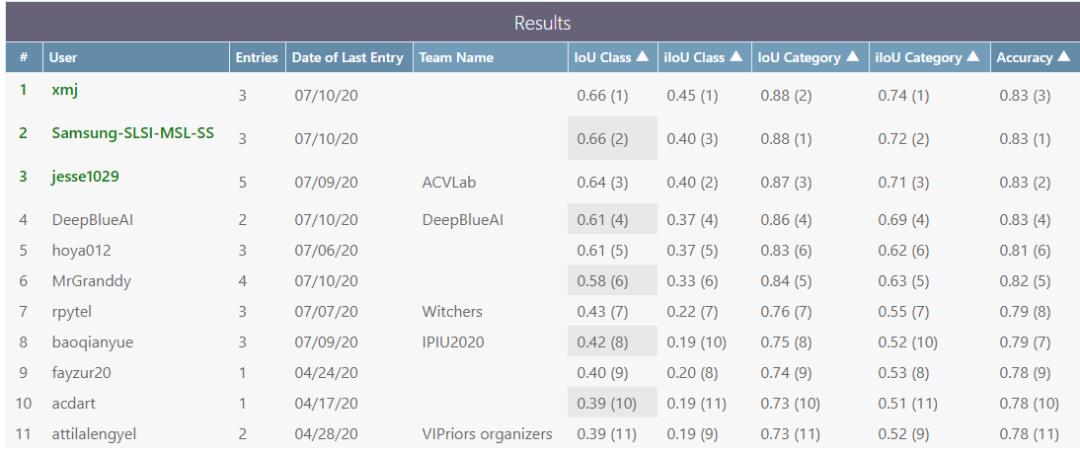
最终的单一模型结果是0.6069831962012341。在排行榜上排名第五。
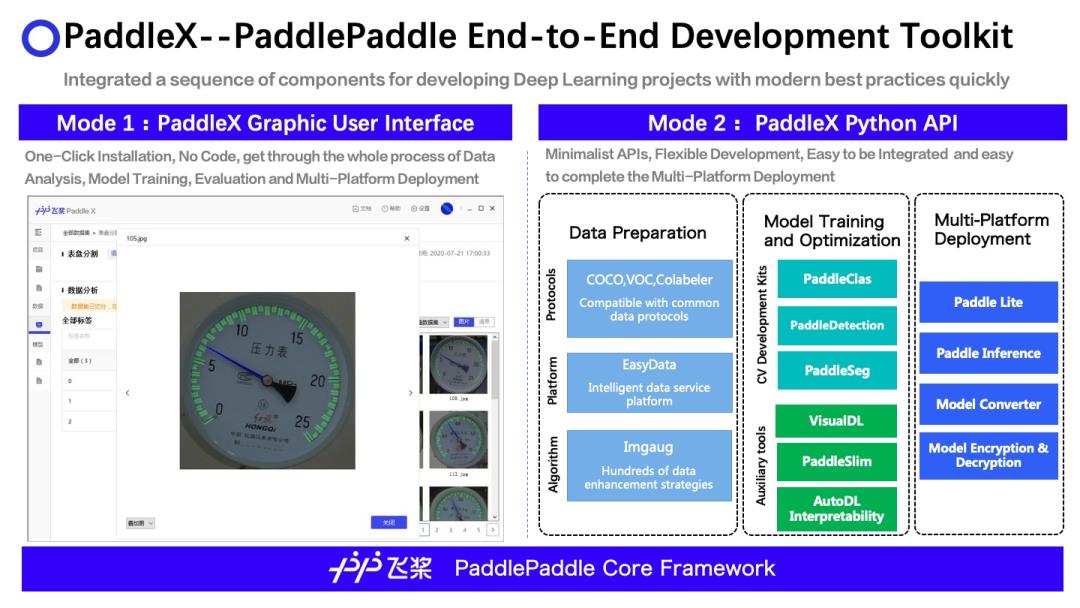
PaddleX 『飞桨』深度学习全流程开发工
PaddleX 集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。
addleX 经过质检、安防、巡检、遥感、零售、医疗等十多个行业实际应用场景验证,沉淀产业实际经验,并提供丰富的案例实践教程,全程助力开发者产业实践落地。
PaddleX提供三种开发模式,满足用户的不同需求:
Python开发模式:通过简洁易懂的Python API,在兼顾功能全面性、开发灵活性、集成方便性的基础上,给开发者最流畅的深度学习开发体验。
前置依赖
paddlepaddle >= 1.8.4
python >= 3.6
cython
pycocotools
Padlde GUI模式:无代码开发的可视化客户端,应用Paddle API实现,使开发者快速进行产业项目验证,并为用户开发自有深度学习软件/应用提供参照。
PaddleX Restful:使用基于RESTful API开发的GUI与Web Demo实现远程的深度学习全流程开发;同时开发者也可以基于RESTful API开发个性化的可视化界面
模块说明:
数据准备:兼容ImageNet、VOC、COCO等常用数据协议,同时与Labelme、精灵标注助手、EasyData智能数据服务平台等无缝衔接,全方位助力开发者更快完成数据准备工作。
数据预处理及增强:提供极简的图像预处理和增强方法--Transforms,适配imgaug图像增强库,支持上百种数据增强策略,是开发者快速缓解小样本数据训练的问题。
模型训练:集成PaddleClas, PaddleDetection, PaddleSeg视觉开发套件,提供大量精选的、经过产业实践的高质量预训练模型,使开发者更快实现工业级模型效果。
模型调优:内置模型可解释性模块、VisualDL可视化分析工具。使开发者可以更直观的理解模型的特征提取区域、训练过程参数变化,从而快速优化模型。
多端安全部署:内置PaddleSlim模型压缩工具和模型加密部署模块,与飞桨原生预测库Paddle Inference及高性能端侧推理引擎Paddle Lite 无缝打通,使开发者快速实现模型的多端、高性能、安全部署。
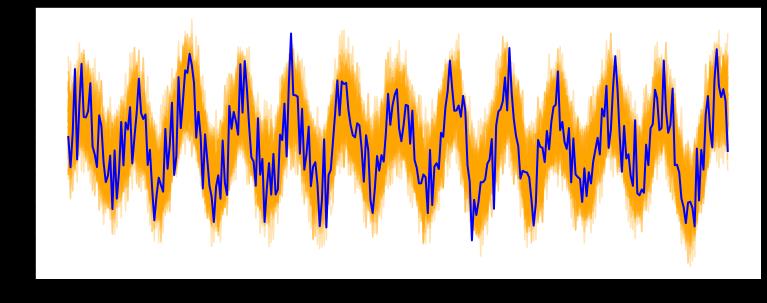
tsmoothie 用于以向量化方式进行时间序列平滑和离群值检测的python库
tsmoothie以快速有效的方式计算单个或多个时间序列的平滑度。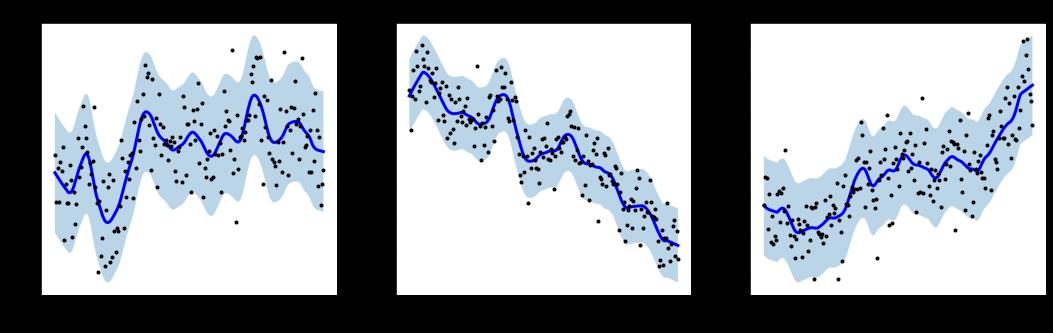
可用的平滑技术是:
指数平滑
具有各种窗口类型(常量,hanning,hamming,bartlett,blackman)的卷积平滑
使用傅立叶变换进行频谱平滑
多项式平滑
各种样条平滑(线性,三次,自然三次)
高斯平滑
Binner平滑
LOWESS
各种季节性分解平滑(卷积,最低,自然三次样条)
带有可自定义组件(水平,趋势,季节性,长期季节性)的卡尔曼平滑
tsmoothie提供了平滑处理结果的间隔计算。这对于识别时间序列中的异常值和异常可能很有用。
关于使用的平滑方法,可用的间隔类型为:
sigma间隔
置信区间
预测间隔
卡尔曼区间
tsmoothie可以执行滑动平滑方法来模拟在线使用。可以将时间序列分成相等大小的片段,并分别对其进行平滑处理。与往常一样,此功能是通过WindowWrapper类以向量化的方式实现的。tsmoothie可以通过BootstrappingWrapper类来操作时间序列引导程序。
支持的引导程序算法为:
没有重叠的块引导程序
移动块引导程序
圆块引导程序
固定式引导
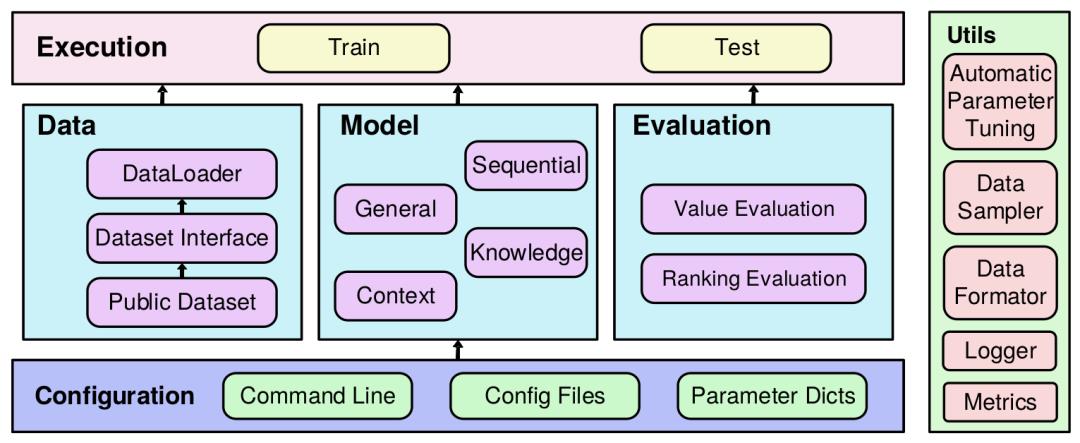
RecBole 统一,全面,高效的推荐库
RecBole 是一个基于 PyTorch 实现的,面向研究者的,易于开发与复现的,统一、全面、高效的推荐系统代码库。我们实现了72个推荐系统模型,包含常见的推荐系统类别,如:
General Recommendation
Sequential Recommendation
Context-aware Recommendation
Knowledge-based Recommendation
我们约定了一个统一、易用的数据文件格式,并已支持 28 个 benchmark dataset。用户可以选择使用我们的数据集预处理脚本,或直接下载已被处理好的数据集文件。
特色:
通用和可扩展的数据结构 我们设计了通用和可扩展的数据结构来支持各种推荐数据集统一化格式和使用。
全面的基准模型和数据集 我们实现了72个常用的推荐算法,并提供了28个推荐数据集的格式化副本。
高效的 GPU 加速实现 我们针对GPU环境使用了一系列的优化技术来提升代码库的效率。
大规模的标准评测 我们支持一系列被广泛认可的评估方式来测试和比较不同的推荐算法。
RecBole可以在以下几种系统上运行:
Linux
Windows 10
macOS X
RecBole需要在python 3.6或更高的环境下运行。
RecBole要求torch版本在1.6.0及以上,如果你想在GPU上运行RecBole,请确保你的CUDA版本或CUDAToolkit版本在9.2及以上。这需要你的NVIDIA驱动版本为396.26或以上(在linux系统上)或者为397.44或以上(在Windows10系统上)。
Hub TensorFlow / PyTorch最快的非结构化数据集管理
新时代的的软件需要新时代的数据,而 Hub 提供这些数据。数据科学家与机器学习研究者常常花费大量时间管理与预处理数据,因而牺牲了训练模型的时间。为了改进这一现状,我们创造了 Hub 。我们将您可达PB量级的数据转换为单个类numpy数组,将其存储在云端,使您可以无缝地从任何设备访问您的数据。Hub 使任何储存在云端的数据类型(图像、文本、音频或视频)像在本地服务器一样能被快速使用。通过使用一致的数据集,您的小组可以一直保持同步。
特点:
通过版本控制工具储存和获取大型数据集
像 Google Docs 一样协作: 多个数据科学家不间断地同时处理一组数据
同时从多个设备访问
部署在任何地方 - 本地、Google Cloud、S3、Azure或是Activeloop (默认——并且免费!)
与您的机器学习工具整合, 比如 Numpy、Dask、Ray、PyTorch或TensorFlow
随心所欲地创建任意大小的数组. 您甚至可以储存 100k x 100k 大小的图片!
样本的形状是动态的. 因此您可以把不同大小的数组储存在一个数组内
无需冗长的操作,用几秒种即可可视化数据中的片段
访问公共数据:
用 Hub 访问公共数据集仅仅需要几行约定俗成的简单代码。运行这个片段就可以 numpy 数组的形式取得MNIST 数据集前1000张图片。
训练模型:
加载数据并直接训练您的模型。Hub 已经与 PyTorch 和 TensorFlow 整合,能以通俗的方式进行格式转换。
教程笔记本:
examples 目录下包含许多示例和笔记本,它们可以让你对 Hub 有一个大致的了解。
notebook |
描述 |
图片上传 |
关于向 Hub 中上传和储存图片的概述 |
数据帧上传 |
关于向 Hub 上上传和储存数据帧的概述 |
音频上传 |
解释了在 Hub 中处理音频数据的方法 |
获取远程数据 |
解释了如何获取数据 |
数据变换 |
简要地描述了如何使用 Hub 进行数据变换 |
动态张量 |
处理拥有可变形状与大小的数据 |
使用 Hub 进行自然语言处理(NLP) |
针对 CoLA 的 Fine Tuning Bert |
应用场景:
卫星和无人机成像: 利用可扩展的航空数据流建造智能农场, 绘制印度的经济状况, 与红十字一起在肯尼亚抗击沙漠蝗虫
医学图像: 体积图像:MRI, Xray
自动驾驶汽车: 雷达, 3D LIDAR, 点云, 语义分割, 视频对象
零售: 自行结账数据集
媒体: 图像,视频,音频储存
有许多数据集管理库提供与 Hub 类似的功能。实际上,很多用户都将 PyTorch 或 Tensorflow 的数据集迁移到了 Hub。以下是你在开始使用 Hub 后就会发现的一些惊人的不同点:
数据是划分为数据块提供的,你可以从远程位置流传输这些数据,而不是一次性将它全部下载下来
由于只需要评估必要部分的数据集,你可以立刻开始处理数据
你能够保存那些无法整个被存储在内存里的数据
你可以在不同机器上,与数个其他用户一起,在版本管理工具下合作管理数据集
你将能获得那些能在数秒内提升你对数据理解的工具,比如我们的可视化工具
你可以轻松地为几个不同的训练库准备数据(例如,你可以为 PyTorch 和 Tensorflow 使用同一个数据集)
精品福利课程
回顾精品内容
推荐系统
机器学习
自然语言处理(NLP)
计算机视觉(CV)
GitHub开源项目:
每周推荐:
七月在线学员面经分享:
以上是关于干货本周AI领域优秀开源项目和优秀论文分享!的主要内容,如果未能解决你的问题,请参考以下文章