本周AI领域优秀开源项目分享,Transformer推理工具医疗影像AI工具包等 6大开源项目
Posted 七月在线实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了本周AI领域优秀开源项目分享,Transformer推理工具医疗影像AI工具包等 6大开源项目相关的知识,希望对你有一定的参考价值。
turbo_transformers: 面向CPU/GPU高效易用的Transformer推理工具
Transformer是近年来NLP领域最重要的模型创新,带来更高的模型精度的同时也引入了更多的计算量,线上Transformer服务的高效部署面临着巨大挑战。
面对丰富的Transformer的线上服务场景,微信模式识别中心开源了名为TurboTransformers的Transformer推理加速引擎。
Turbo具有如下特性:
1、优异的CPU/GPU性能表现。面向Intel多核CPU和NVIDIA GPU硬件平台,TurboTransformers可以充发挥硬件的各层级计算能力。
在多种CPU和GPU硬件上获得了超过pytorch/tensorflow和目前主流优化引擎(如onnxruntime-mkldnn/onnxruntime-gpu, torch JIT, NVIDIA faster transformers)的性能表现。详细benchmark结果见下文。
2、为NLP推理任务特点量身定制。和CV任务不同,NLP推理任务输入尺寸多个维度会存在变化。传统做法是补零或者截断成固定长度,这样引入了额外补零计算开销。
另外有些框架如onnxruntime、tensorRT、torchlib需要预先对计算图根据输入尺寸进行预处理,这对尺寸变化的NLP任务并不适用。TurboTransformers可以支持变长输入序列处理,且不需要预处理过程。
3、更简单的使用方式。TurboTransformers支持python和C++接口进行调用。
它可以作为pytorch的加速插件,在Transformer任务上,通过加入几行python代码获得的端对端加速效果。
TurboTransformers架构:
算子层优化:
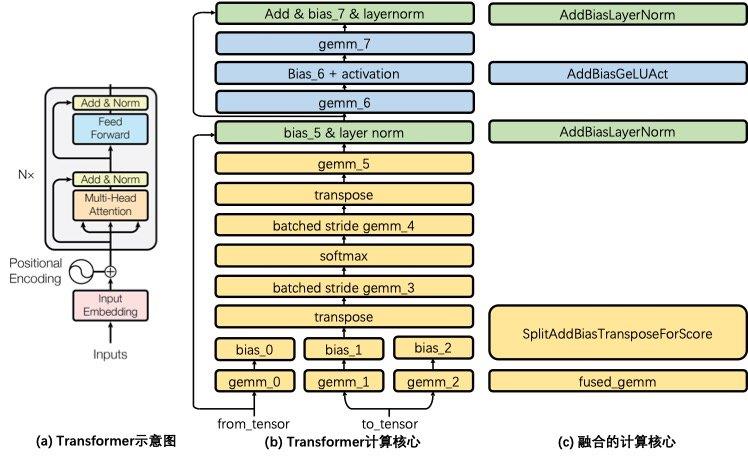
Transformer 架构中的 Transformer Cell 计算包含了 8 个 GEMM(通用矩阵乘法,General Matrix Multiplication)运算。
其中,(a) 中灰色方框内的结构为一个 Transformer Cell,BERT encoder 堆叠了 Nx 个这样的 Transformer Cell;(b) 将一个 Cell 的细节加以展开,每一个矩形都是一个独立的计算核心。
TurboTransformers 通过调优 Intel MKL 和 cuBLAS 的 GEMM 调用方式获得最佳 GEMM 性能。
通过调整了预训练矩阵存储方式,并且在硬件允许条件下,在 GPU 上使用 tensor core 方式进行 GEMM 运算。
https://github.com/Tencent/TurboTransformers
MONAI 用于医疗影像的AI工具包

MONAI是基于PyTorch的开源框架,用于医疗影像的深度学习,它是PyTorch生态系统的一部分。
其目标是:
建立一个在共同基础上合作的学术,工业和临床研究人员社区;
创建最新的,端到端的培训流程以进行医疗成像;
为研究人员提供优化和标准化的方式来创建和评估深度学习模型。
项目特点:
灵活的多维医学成像数据预处理;
组合和可移植的API,可轻松集成到现有工作流程中;
网络,损耗,评估指标等领域特定的实现;
可定制的设计,以适应不同的用户专业知识;
多GPU数据并行性支持。
https://github.com/Project-MONAI/MONAI
Yet-Another-EfficientDet-Pytorch 具有SOTA实时性能和预先训练的权重的官方有效数据的Pytorch重实现


速度测试:比官方Tensorflow版本快2倍,没有任何技巧。
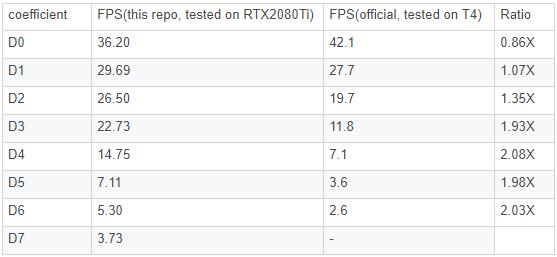
在2080Ti,Ubuntu 19.10 x64上运行此测试。
准备一个具有相同内容,大小(1,3,512,512)-pytorch的图像张量。
通过推断一次来启动所有操作。
以batchsize 1运行10次,并计算平均时间,包括后处理和可视化,以使测试更加实用。


https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
dstlr是一个开放源代码平台,用于从非结构化文本构建可伸缩的端到端知识图。
该平台收集文档,提取提及和关系以填充原始知识图,将提及链接链接到Wikidata中的实体,然后使用来自Wikidata的事实丰富知识图。
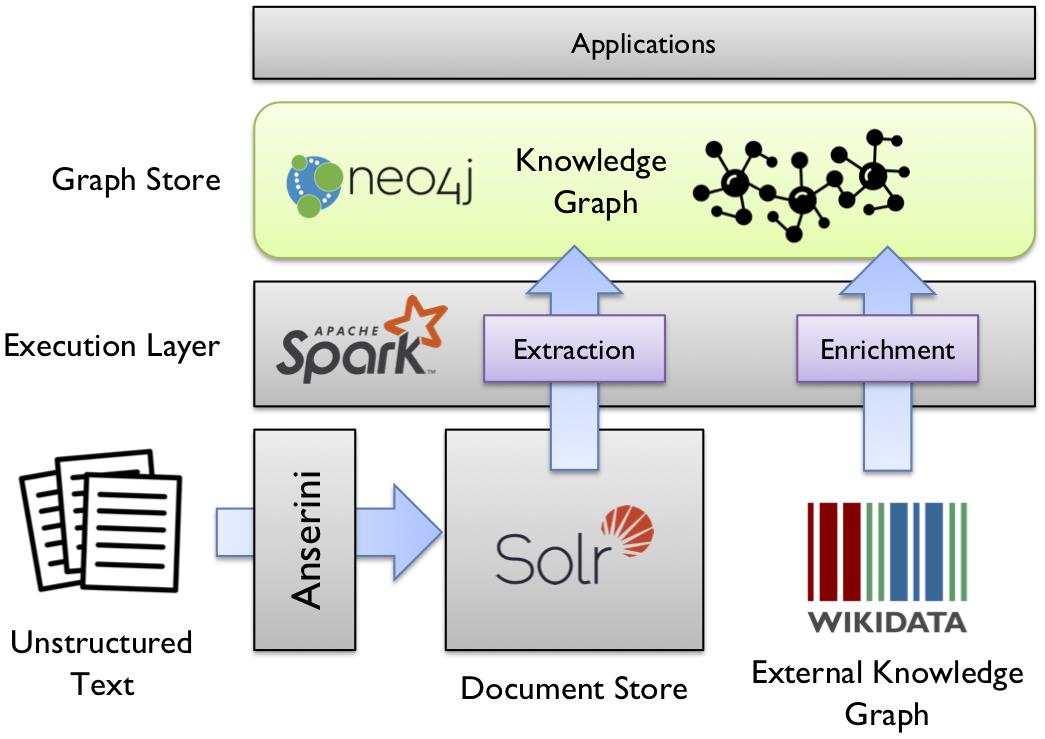
当前的dstlr演示将包含大约60万个文档的TREC华盛顿邮报语料库“提取”为一个原始知识图,该图由大约9700万个三元组组成,并丰富了来自维基数据的事实,从而发现了该语料库中的324K个不同实体。
在此知识图的顶部,我们已实现了子图匹配方法,以使用声明性Cypher查询语言将提取的关系与Wikidata中的事实对齐。
这个简单的演示显示了事实验证,找到已断言事实的文本支持,检测不一致和遗漏的事实以及提取远程监督的训练数据都可以在同一框架内执行。
在我们的平台上,可以构建许多应用程序,例如,以支持商业智能,知识发现和语义搜索。
作为一个非常简单的演示应用程序,我们已经实现了一种子图匹配方法,以使用声明性Cypher查询语言将提取的关系与Wikidata中的事实对齐。
这个简单的演示显示了事实验证,找到已断言事实的文本支持,检测不一致和遗漏的事实以及提取远程监督的训练数据都可以在同一框架内执行。
https://dstlry.github.io/
footprints 从单色图像估计可见和隐藏的可遍历空间– CVPR 2020
我们介绍了“足迹”,一种从单个RGB图像估计可见和隐藏可遍历空间的方法。

从单色图像了解场景的形状是一项艰巨的计算机视觉任务。大多数方法旨在预测相机可见的表面的几何形状,这在规划机器人或增强现实智能体的路径时用途有限。
超出视线范围预测的模型通常使用体素或网格参数化场景,这在机器学习框架中使用可能会很昂贵。
我们的方法从单个图像预测隐藏的地面几何形状和范围:
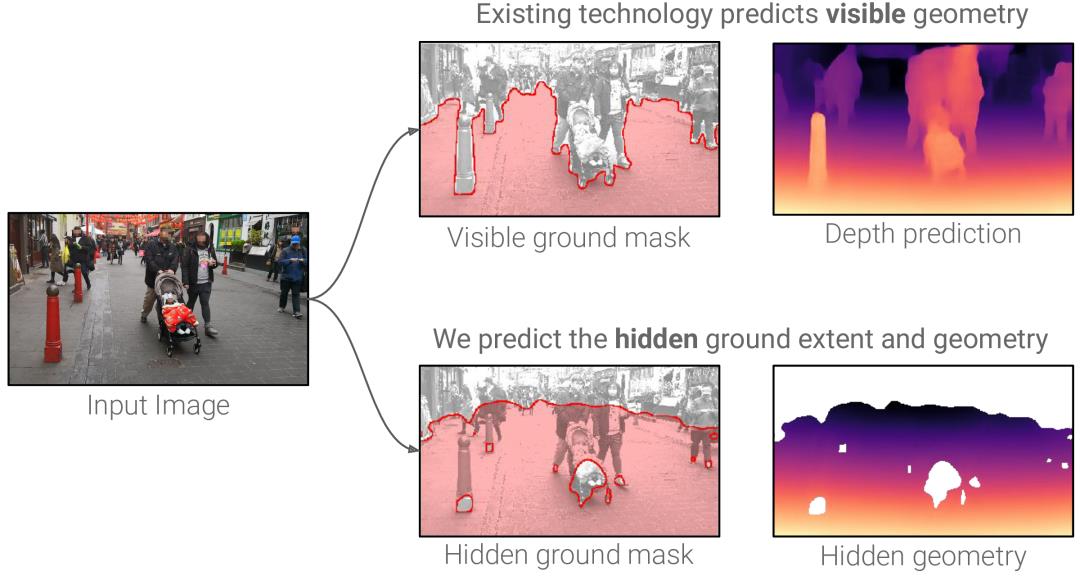
我们从立体视频序列中学习,使用相机姿势,每帧深度和语义分段来形成训练数据,该训练数据用于监督图像到图像网络。
https://github.com/nianticlabs/footprints
detecto 使用PyTorch构建功能全面的计算机视觉模型
Detecto是一个Python软件包,可让您仅用5行代码即可构建功能全面的计算机视觉和对象检测模型。
静态图像和视频的推断,自定义数据集的学习转移以及模型到文件的序列化只是Detecto的一些功能。
Detecto也是建立在PyTorch之上的,可以在两个库之间轻松地转移模型。


完整的API文档可在detecto.readthedocs.io中找到。这些文档分为三个部分,每个部分对应于Detecto的模块之一:
detecto.core模块包含该软件包的中心类:Dataset,DataLoader和Model。这些用于读取标记的数据集并训练功能正常的对象检测模型。
detecto.core模块包含该软件包的中心类:Dataset,DataLoader和Model。这些用于读取标记的数据集并训练功能正常的对象检测模型。
detecto.visualize模块用于显示带标签的图像,绘制预测并在视频上运行对象检测。
https://github.com/alankbi/detecto
(今日福利)
9.9元秒杀【Transformer与Bert实战】特训课程,两大博士联合授课,在售价119.9元,限时9.9秒!
扫码抢占名额 以上是关于本周AI领域优秀开源项目分享,Transformer推理工具医疗影像AI工具包等 6大开源项目的主要内容,如果未能解决你的问题,请参考以下文章