R语言与点估计学习笔记(EM算法与Bootstrap法)
Posted 大数据挖掘DT数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言与点估计学习笔记(EM算法与Bootstrap法)相关的知识,希望对你有一定的参考价值。
众所周知,R语言是个不错的统计软件。今天分享一下利用R语言做点估计的内容。主要有:矩估计、极大似然估计、EM算法、最小二乘估计、刀切法(Jackknife)、自助法(Bootstrap)的相关内容。
点估计是参数估计的一个组成部分。有许多的估计方法与估计理论,具体内容可以参见lehmann的《点估计理论》(推荐第一版,第二版直接从UMVU估计开始的)
一、矩估计
对于随机变量来说,矩是其最广泛,最常用的数字特征,母体的各阶矩一般与的分布中所含的未知参数有关,有的甚至就等于未知参数。由辛钦大数定律知,简单随机子样的子样原点矩依概率收敛到相应的母体原点矩。这就启发我们想到用子样矩替换母体矩,进而找出未知参数的估计,基于这种思想求估计量的方法称为矩法。用矩法求得的估计称为矩法估计,简称矩估计。它是由英国统计学家皮尔逊Pearson于1894年提出的。
因为不同的分布有着不同的参数,所以在R的基本包中并没有给出现成的函数,我们通常使用人机交互的办法处理矩估计的问题,当然也可以自己编写一些函数。
首先,来看看R中给出的一些基本分布,如下表:
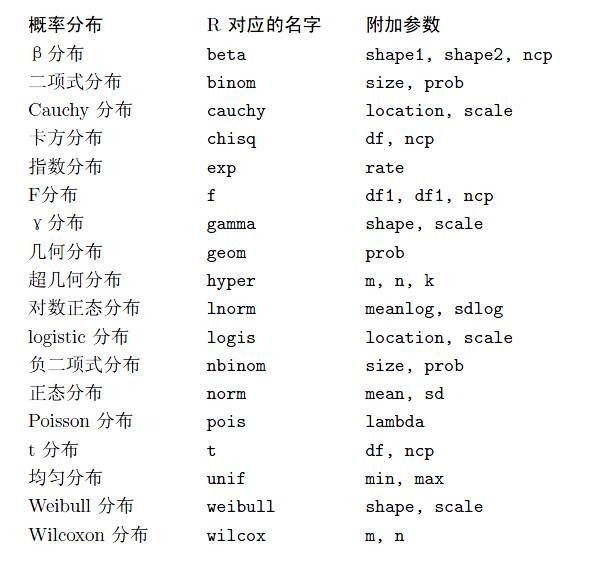
虽然R中基本包中没有现成求各阶矩的函数,但是对于给出的样本,R可以求出其平均值(函数:mean),方差(var),标准差(sd),在fBasics包中还提供了计算偏度的函数skewness(),以及计算峰度的kurtosis()。这样我们也可以间接地得到分布一到四阶矩的数据。由于低阶矩包含信息较为丰富,矩估计也一般采用低阶矩去处理。
注:在actuar包中,函数emm()可以计算样本的任意阶原点矩。但在参数估计时需要注意到原点矩的存在性
例如我们来看看正态分布N(0,1)的矩估计效果。
> x<-rnorm(100) #产生N(0,1)的100个随机数
> mu<-mean(x) #对N(mu,sigma)中的mu做矩估计
> sigma<-var(x) #这里的var并不是样本方差的计算函数,而是修正的样本方差,其实也就是x的总体方差
> mu
[1] -0.1595923
> sigma
[1] 1.092255
可以看出,矩估计的效果还是可以的。
我们再来看一个矩估计的例子:设总体X服从二项分布B(k,p),X1,X2,…,Xn,是总体的一个样本。K,p为未知参数。那么k,p的矩估计满足方程:kp – M1 = 0, kp(1 p) M2 = 0.
我们可以编写函数:
moment <-function(p){
f<-c(p[1]*p[2]-M1,p[1]*p[2]-p[1]*p[2]^2-M2)
J<-matrix(c(p[2],p[1],p[2]-p[2]^2,p[1]-2*p[1]*p[2]),nrow=2,byrow=T)#jicobi矩阵
list(f=f,J=J)
}# p[2]=p, p[1]=k,
检验程序
x<-rbinom(100, 20, 0.7); n<-length(x)
M1<-mean(x);M2<-(n-1)/n*var(x)
p<-c(10,0.5)
Newtons(moment, p)$root #是用牛顿法解方程的程序,见附件1
运行结果为:
[1]22.973841 0.605036
可以得到k,p的数值解
二、极大似然估计(MLE)
极大似然估计的基本思想是:基于样本的信息参数的合理估计量是产生获得样本的最大概率的参数值。值得一提的是:极大似然估计具有不变性,这也为我们求一些奇怪的参数提供了便利。
在单参数场合,我们可以使用函数optimize()来求极大似然估计值,函数的介绍如下:
optimize(f = , interval = , ..., lower = min(interval),
upper = max(interval), maximum = FALSE,
tol = .Machine$double.eps^0.25)
例如我们来处理Poisson分布参数lambda的MLE。
设X1,X2,…,X100为来自P(lambda)的独立同分布样本,那么似然函数为:
L(lambda,x)=lambda^(x1+x2+…+x100)*exp(10*lambda)/(gamma(x1+1)…gamma(x100+1))
这里涉及到的就是一个似然函数的选择问题:是直接使用似然函数还是使用对数似然函数,为了说明这个问题,我们可以看这样一段R程序:
> x<-rpois(100,2)
> sum(x)
[1] 215
> ga(x)#这是一个求解gamma(x1+1)…gamma(x100+1)的函数,用gamma函数求阶乘是为了提高计算效率(源代码见附1)
[1] 1.580298e+51
> f<-function(lambda)lambda^(215)*exp(10*lambda)/(1.580298*10^51)
#这里有一些magic number + hard code 的嫌疑,其实用ga(x)带入,在函数参数中多加一个x就好
> optimize(f,c(1,3),maximum=T)
$maximum
[1] 2.999959
$objective
[1] 2.568691e+64
> fun<-function(lambda)-100*lambda+215*log(lambda)-log(1.580298*10^51)
> optimize(fun,c(1,3),maximum=T)
$maximum
[1] 2.149984 #MLE
$objective
[1] -168.3139
为什么会有这样的差别?这个源于函数optimize,这个函数本质上就是求一个函数的最大值以及取最大值时的自变量。但是这里对函数的稳定性是有要求的,取对数无疑增加了函数的稳定性,求极值才会合理。这也就是当你扩大了MLE存在区间时warning会出现的原因。当然,限定范围时,MLE会在边界取到,但是,出现边界时,我们需要更多的信息去判断它。这个例子也说明多数情况下利用对数似然估计要优于似然函数。
在多元ML估计时,你能用的函数将变为optim,nlm,nlminb它们的调用格式分别为:
optim(par, fn, gr = NULL, ...,
method = c("Nelder-Mead", "BFGS", "CG", "L-BFGS-B", "SANN", "Brent"),
lower = -Inf, upper = Inf,
control = list(), hessian = FALSE)
nlm(f, p, ..., hessian = FALSE, typsize = rep(1, length(p)),
fscale = 1, print.level = 0, ndigit = 12, gradtol = 1e-6,
stepmax = max(1000 * sqrt(sum((p/typsize)^2)), 1000),
steptol = 1e-6, iterlim = 100, check.analyticals = TRUE)
nlminb(start, objective, gradient = NULL, hessian = NULL, ...,
scale = 1, control = list(), lower = -Inf, upper = Inf)
> x<-rnorm(1000,2,6) #6是标准差,而我们估计的是方差
> ll<-function(theta,data){
+ n<-length(data)
+ ll<--0.5*n*log(2*pi)-0.5*n*log(theta[2])-1/2/theta[2]*sum((data-theta[1])^2)
+ return(-ll)
+ }
>nlminb(c(0.5,2),ll,data=x,lower=c(-100,0),upper=c(100,100)) $par
[1] 1.984345 38.926692
看看结果估计的还是不错的,可以利用函数mean,var验证对正态分布而言,矩估计与MLE是一致.
然而这里还有一些没有解决的问题,比如使用nlminb初始值的选取。希望阅读到这的朋友给出些建议。
最后指出在stata4,maxLik等扩展包中有更多关于mle的东西,你可以通过查看帮助文档来学习它。
附1:辅助程序代码
Newtons<-function (fun, x, ep=1e-5,it_max=100){
index<-0; k<-1
while (k<=it_max){
x1 <- x; obj <- fun(x);
x <- x - solve(obj$J, obj$f);
norm <- sqrt((x-x1) %*% (x-x1))
if (norm<ep){
index<-1; break
}
k<-k+1
}
obj <- fun(x);
list(root=x, it=k, index=index, FunVal= obj$f)
}
ga<-function(x){
ga<-1
for(i in 1:length(x)){
ga<-ga*gamma(x[i]+1)
}
ga
}
三、EM算法
EM算法是一种在观测到数据后,用迭代法估计未知参数的方法。可以证明EM算法得到的序列是稳定单调递增的。这种算法对于截尾数据或参数中有一些我们不感兴趣的参数时特别有效。
EM算法的步骤为:
E-step(求期望):在给定y及theta=theta(i)的条件下,求关于完全数据对数似然关于潜在变量z的期望
M-step(求极值):求上述期望关于theta的最大值theta(i+1)
重复以上两步,直至收敛即可得到theta的MLE。
从上面的算法我们可以看到对于一个参数的情况,EM仅仅只是求解MLE的一个迭代算法。M-step做得就是optimize函数做得事情。对于EM算法,我们也没有现成的求解函数(这个是自然的),我们一样可以通过人机交互的办法处理。
先举一个一元的例子:
设一次实验可能有4个结果,发生概率分别为0.5+theta/4, 0.25-theta/4 ,0.25-theta/4 ,theta/4.其中theta在0,1之间。现进行了197次实验,结果发生的次数分别为:125,18,20,34,求theta的MLE。
计算出theta(i+1)=(195theta(i)+68)/(197theta(i)+144)
为什么是这个结果,请翻阅王兆军《数理统计讲义》p43-p44
我们用简单的循环就可以解决这个问题,程序及结果如下:
>fun<-function(error=1e-7){
+theta<-0.5
+k<-1
+while(T){
+k<-k+1
+theta[k]<-(159*theta[k-1]+68)/(197*theta[k-1]+144)
+if(abs(theta[k]-theta[k-1])<error) break
+}
+list(theta<-theta[k],iter<-k)
+}
>fun()
[[1]]
[1]0.6268215
[[2]]
[1]9
我们再看一个二元的简单例子:
幼儿园里老师给a,b,c,d四个小朋友发糖吃,但老师有点偏心,不同小朋友得到糖的概率不同,p(a)=0.5,p(b)=miu, p(c)=2*miu, p(d)=0.5-3*miu 如果确定了参数miu,概率分布就知道了。我们可以通过观察样本数据来推测参数知道c和d二人得到的糖果数,也知道a与b二人的糖果数之和为h,如何来估计出参数miu呢?前面我们知道了,如果观察到a,b,c,d就可以用ML估计出miu。反之,如果miu已知,根据概率期望 a/b=0.5/miu,又有a+b=h。由两个式子可得到 a=0.5*h/(0.5+miu)和b=miu*h/(0.5+miu)。
># 已知条件
>
>h = 20
>c = 10
>d = 10
>
># 随机初始两个未知量
>miu = runif(1,0,1/6)
>b = round(runif(1,1,20))
>
>iter = 1
>nonstop=TRUE
>while (nonstop) {
+ # E步骤,根据假设的miu来算b
+ b = c(b,miu[iter]*h/(0.5+miu[iter]))
+ print(b)
+ # M步骤,根据上面算出的b再来计算miu
+ miu = c(miu,(b[iter+1] +c)/(6*(b[iter+1]+c+d)))
+ print(miu)
+ # 记录循环次数
+ iter = iter + 1
+ # 如果前后两次的计算结果差距很小则退出
+ nonstop =((miu[iter]-miu[iter-1])>10^(-10))
+}
[1]3.000000 4.450531
[1]0.14310878 0.09850182
>print(cbind(miu,b))
miu b
[1,]0.14310878 3.000000
[2,]0.09850182 4.450531
关于EM算法,及后续的发展GME的理论你可以在多数数理统计书上找到相关结论,也可以用类似办法编写函数处理它。
四、 自助法(bootstrap)
Bootstrap法是以原始数据为基础的模拟抽样统计推断法,可用于研究一组数据的某统计量的分布特征,特别适用于那些难以用常规方法导出对参数的区间估计、假设检验等问题。“Bootstrap”的基本思想是:在原始数据的围内作有放回的再抽样,样本含量仍为n,原始数据中每个观察单位每次被抽到的概率相等,为1,…,n,所得样本称为bootstrap样本。于是可得到参数Η的一个估计值Η(b),这样重复若干次,记为B。设B=1000,就得到该参数的1000个估计值,则参数Η的标准误的bootstrap估计。简而言之就是:既然样本是抽出来的,那我何不从样本中再抽样。
我们知道,如果分布函数F是已知的。在理论上就能够计算出参数的估计量的均方误差.若分布函数f未知,由格里文科-康特利定理知,当M充分大时,经验分布函数以概率1一致收敛到F。
我们举一例:利用bootstrap法估计标准正态分布随机变量的期望theta=E(X)
>gauss<-rnorm(100,2,6)
>boot<-0
>for(i in 1:1000){
+boot[i]=mean(sample(gauss,replace=T))
+}
>summary(boot)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.3345 1.9540 2.3350 2.3230 2.7020 4.2330
>summary(gauss)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-13.380 -2.238 2.570 2.296 6.861 16.230
>sd(boot)
[1]0.599087
>sd(gauss)/sqrt(100)
[1]0.5906275
结果分析:
| 方法 | 标准差 | 均值 |
| 理论值 | 0.6 | 2 |
| 矩估计 | 0.5906275 | 2.570 |
| bootstrap算法 | 0.599087 | 2.3230 |
需要指出的是bootstrap法不是为了提高估计量的精度.而是一般用来对估计量的方差进行估计。
数据挖掘入门与实战
教你机器学习,教你数据挖掘
数据分析入门与实战
从哪里做起学习数据分析?
如何培养数据分析的能力?
以上是关于R语言与点估计学习笔记(EM算法与Bootstrap法)的主要内容,如果未能解决你的问题,请参考以下文章