机器学习笔记九 EM算法及其推广
Posted Banana_junn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记九 EM算法及其推广相关的知识,希望对你有一定的参考价值。
一、基本定义
EM算法(又称期望极大算法)是一种迭代算法,用于含有隐变量的概率模型的极大似然估计或极大后验概率估计。EM算法与其说是一种算法,不如说是一种解决问题的思路。
EM算法分为两步:
①E步(计算期望):利用对隐藏变量的现有估计值,计算其最大似然估计值;
②M步(最大化):在E步上求得的最大似然值来计算参数的值。M步上找到的参数估计值被用于下一个E步计算中,这个过程不断交替进行。
二、EM算法的适用情况
概率模型有时含有隐变量或潜在变量,此时无法用极大似然估计法或贝叶斯估计法估计参数,就得用EM算法了。
·Example1:男生组成一堆,有100人,女生组成一堆,也有100人,现在要求男女生身高的正态分布参数,如果是按照性别分堆的话,很容易就能用极大似然估计出该参数,可是如果男女生混为一堆了,就不知道每个身高是男生的还是女生的,这时就需要EM算法来解决。
·Example2:三硬币模型

※3、EM算法的基本思想
假设我们想估计的参数为A,B。 开始的时候A和B都未知, 但是如果我们知道了A,就能得到B。 我们得到了B就可以得到A。 EM会给A一个初始值,然后得到B,再由B得到A, 再得到B,一直迭代到收敛为止。
三、EM算法的基本流程

PS:EM算法与初值的选择有关,选择不同的初值可能得到不同的参数估计值,并且EM算法对初值是敏感的。
四、Jensen不等式
凸函数定义:设f是定义域为实数的函数,如果对所有的实数x,f(x)的二阶导数都大于0,那么f就是凸函数。
Jensen不等式定义:若f是凸函数,X是随机变量,则E[f(X)]≥f(E[X]),当且仅当X是常量时,该式取等号。其中,E(x)表示X的数学期望(也就是a和b的中值)。Jensen不等式应用于凹函数时,不等号方向反向,当且仅当X是常量时,该不等式取等号。
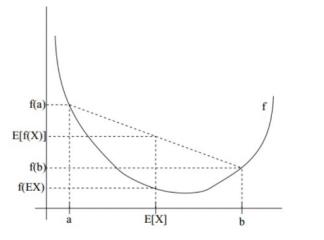
PS:这里的凸函数跟之前理解的凸函数有点不一样,只是定义不一样罢了。
以上是关于机器学习笔记九 EM算法及其推广的主要内容,如果未能解决你的问题,请参考以下文章