机器学习笔记EM算法及实践(以混合高斯模型(GMM)为例来次完整的EM)
Posted 王大宝的CD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记EM算法及实践(以混合高斯模型(GMM)为例来次完整的EM)相关的知识,希望对你有一定的参考价值。
今天要来讨论的是EM算法。第一眼看到EM我就想到了我大枫哥,EM Master,千里马,RUA!!!不知道看这个博客的人有没有懂这个梗的。好的,言归正传,今天要讲的EM算法,全称是Expectation maximization,期望最大化。怎么个意思呢,就是给你一堆观测样本,让你给出这个模型的参数估计。我靠,这套路我们前面讨论各种回归的时候不是已经用烂了吗?求期望,求对数期望,求导为0,得到参数估计值,这套路我懂啊,MLE!但问题在于,如果这个问题存在中间的隐变量呢?会不会把我们的套路给带崩呢,我们通过两个例子来认识一下这两种情况。
====================================================================
不存在中间变量的EM。
假设有一天人类消除了性别的差别,所有的人都是同一个性别。这个时候,我给了你一群人的身高让你给我做一个估计人身高的模型。
怎么办呢?感觉上身高应该是服从高斯分布吧,所以假设人的身高分布服从高斯分布N(Mu,Sigma^2),现在我又有了N个人的身高的数据,我就可以照着上面的套路进行了。先求对数似然函数
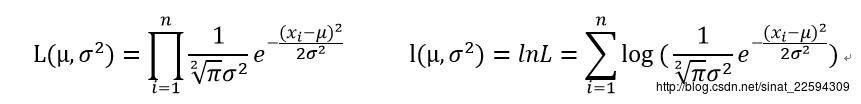
接着对两个参数求偏导为0

这样就得到了我们的参数估计
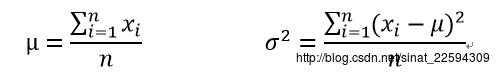
喜闻乐见的结果,又好求又符合我们的直觉,那我们再来看看另一种情况。
====================================================================
存在中间变量的EM。
正如你所知,身高和人种的关系挺大的,而人类又有那么多种族,所以,再给你一堆人的数据,要做一个估计人身高的模型,那我们应该怎么做呢?
首先,现在分为不同种族若干类了,这些类别的概率肯定有个分布,其次,各种族当中身高是服从不同的分布的,那么这样身高的估计就变成了
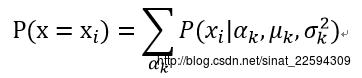
Alpha代表了该样本属于某一人种的比例,其实就是隐藏的中间变量。Muk和sigmak^2为各类高斯分布的参数。按照我们上面的套路就是求对数似然概率再求导得到参数的估计,那么先来看看似然函数
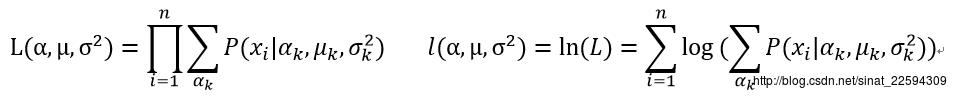
这下尴尬的情况出现了,对数里面带加号,这下求导就变得复杂异常了,而且没法求解,事实上,这种式子确实没有解析解。不过憋灰心啊,假设我们随便猜一个alpha的分布为Q,那么对数似然函数可以写成
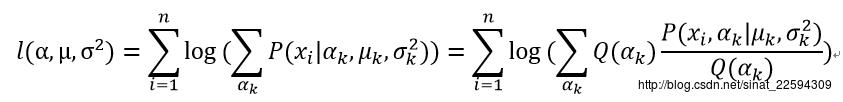
由于Q是alpha的一个分布,所以似然函数可以看成是一个log(E(x)),log是个凹函数啊,割线始终在函数图像下方,Jensen不等式反向应用一下,有log(E(x))>=E(log(x)),所以上面的对数似然有

冷静分析一下现在的情况,我们现在得到了一个对数似然函数的下界函数,我们采用曲线救国的战略,我们求解它的局部最大值,那么更新后的参数带入这个下界函数一定比之前的参数值大,而它本身又是对数似然函数的下界函数,所以参数更新后,我们的对数似然函数一定是变大了!所以,就利用这种方法进行迭代,最后就能得到比较好的参数估计。还有点晕吗,没事,我从百度扒个图给你来个形象的解释
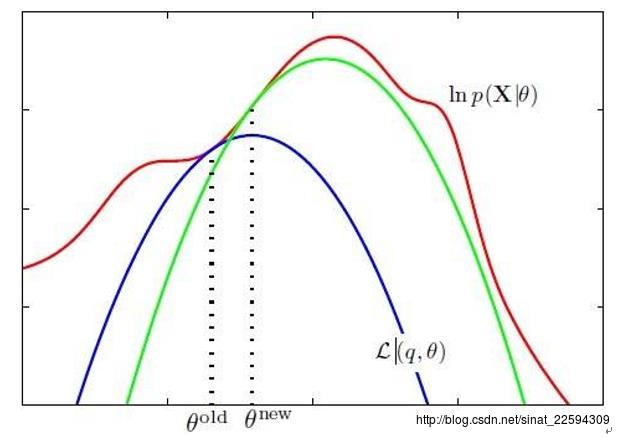
红色那条线就是我们的对数似然函数,蓝色那条是我们在当前参数下找到的对数似然的下界函数,可以看到,我们找到它的局部极值那么参数更新成thetanew,此时对数似然函数的值也得到了上升,这样重复进行下去,是不是就可以收敛到对数似然函数的一个局部极值了嘛。对的,局部极值,并不能保证是全局最优,但它就是个估计嘛,你还要她怎样?!
到了这里,我们好像跳着先把第二步参数更新的工作做完了,那么还有一个事情是我们要注意的,Q呢,Q是啥,没Q你算啥极值,更新啥参数。我们已经知道Q是alpha的一个分布,然后我们肯定是希望这个下界函数尽量贴近原来的对数似然函数,这样我们才能更快地更新参数,那下界函数啥时最大呢,等号成立呗,等号成立说明你求期望的对象是个常数呀,所以log和Q谁在前后都无所谓,那么就有了

直观地可以理解成第i个样本来自第k个类别的可能性。好了,现在Q也确定了,我们根据上面所说的方法更新参数,再更新Q,再更新参数,迭代进行下去就可以了。
如果你能坚持看到这里,少侠我只能说你大功已成。因为其实我们已经把EM算法整个推导完了,也许你还是有点云里雾里,那我们再来仔细梳理一下这个流程
1 拿到所有的观测样本,根据先验或者喜好先给一个参数估计。
2 根据这个参数估计和样本计算类别分布Q,得到最贴近对数似然函数的下界函数。
3 对下界函数求极值,更新参数分布。
4 迭代计算,直至收敛。
说起来啊,EM算法据说是机器学习进阶的一个算法,但至少目前来看,它的思路还是很容易理解的嘛,整个过程中唯一一个可能初学者觉得有点绕的地方就是应用Jensen不等式的那一步,那我再啰嗦两句。所谓Jensen不等式,你可以这么理解,对于一个凸函数f而言,它的割线始终在函数图像上方你承认吧,我在上面任取两点x1,x2,参数theta介于0到1之间,那么theta*x1+(1-theta)*x2就是介于x1和x2之间的一点吧,在这点上过x1x2割线的值大于函数值吧,是不是就有了theta*f(x1)+(1-theta)*f(x2)>f(theta*x1+(1-theta)*x2),根据这个结论再推广开来,就有E(f(x))>f(E(x)),在对数似然函数中,由于log是个凹函数,所以把它反过来用,老铁没毛病吧?!这一点想通了我觉得整个EM算法的流程还是蛮好懂的。
下面呢,我们还回到这个身高模型的预测,假设给了m个样本,有k个种族,每个种族的身高都是服从高斯分布的,那么这就变成了EM算法中最具代表性的一个例子,高斯混合模型GMM。
====================================================================高斯混合模型(GMM)
刚才已经讲了EM算法的套路了,假设我们现在处于某一步迭代中,那么我们该干嘛呢?
E-step 求最佳的类别分布
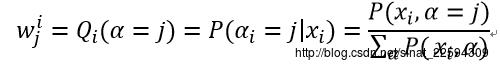
可以将其理解为第i个样本属于第J类的概率。
M-step 更新参数
求得了Q之后,我们就得到了最贴近原对数似然函数的下界函数,那我们对它求极值就可以得到更新后的参数,先看一下这个下界函数
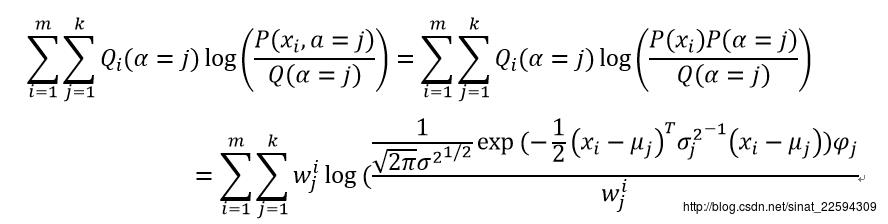
Log函数里面全是乘积项这是我们最喜欢的形式,这样求导的时候但凡不相关的我们直接扔掉就行,待求参数mu,sigma^2,psi,依次求导为0就成。
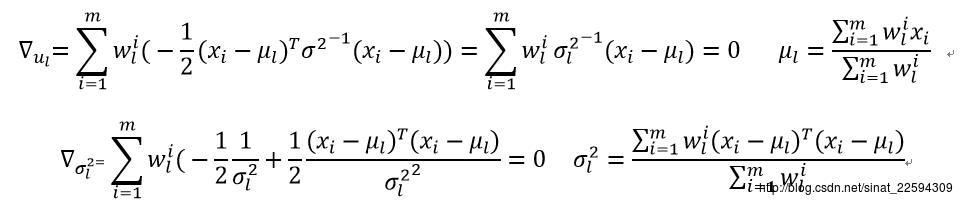
对于psi的求解可能复杂一些,首先我们把下界函数中与psi不相关的项全部去掉,然后psi作为各类别的比例有一个天然的约束条件就是所有的psi之和为1,所以目标函数变成

这种带约束的优化前面在SVM的时候不知道用了多少回,拉格朗日乘子法
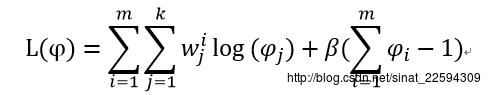
接下来对psi求导
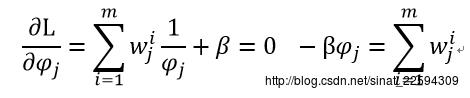
两边同时再对j从1到k连加,psi那一项就没了,右式就变成样本数目m,这样就求得了beta,回代我们就可以求得psi参数的更新
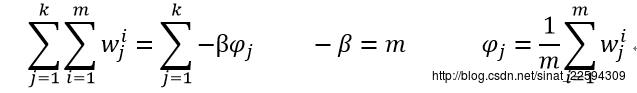
至此,所有的参数更新工作就已完成,下面重复进行迭代就行了。
我们先把GMM的算法梳理一下
1 给参数取初始值,开始迭代。
2 求每个样本对每个类别的概率,科学的叫法叫求响应度

3 更新模型参数
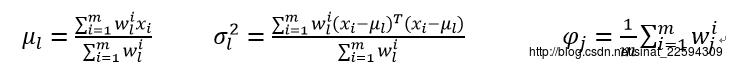
4 重复23两步直至收敛。
我们再来看看这些参数的意义,其实未尝不符合我们的直觉认识。W(i,j)可以看做第i个样本属于第j类的概率,那么所有样本中属于第j类的个数就是w(i,j)之和,每个样本xi对应第j类的值就是W(i,j) xi,这样算的平均数就是第j类对应的mu,继续按照这个思路算的方差就是第j类的sigma^2,第j类的概率就是第j类的个数除以总样本数。所以,GMM模型虽然推导起来有点吓人,但仔细想想它最后的结果也是符合我们的直觉认识的,每个样本都是一部分属于某一类,所有样本中的某一类的部分构成了这一类的分布,perfect!!!
====================================================================
这样的话,理论部分我们就讲完了,接下来又是调包侠的时刻了,上次写完后我想到鸢尾花数据无监督算法也能做啊,不给标签我们强行给它分类看看效果如何。所以这里我们K-Means和GMM算法分别对鸢尾花进行处理,看看它们的聚类效果如何。
代码如下
import numpy as np
from sklearn import datasets
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
#读取数据
iris=datasets.load_iris()
x=iris.data[:,:2]
y=iris.target
mu = np.array([np.mean(x[y == i], axis=0) for i in range(3)])
print '实际均值 = \\n', mu
#K-Means
kmeans=KMeans(n_clusters=3,init='k-means++',random_state=0)
y_hat1=kmeans.fit_predict(x)
mu1=np.array([np.mean(x[y_hat1 == i], axis=0) for i in range(3)])
print 'K-Means均值 = \\n', mu1
print '分类正确率为',np.mean(y_hat1==y)
gmm=GaussianMixture(n_components=3,covariance_type='full', random_state=0)
gmm.fit(x)
print 'GMM均值 = \\n', gmm.means_
y_hat2=gmm.predict(x)
print '分类正确率为',np.mean(y_hat2==y)
输出结果为
实际均值 =
[[5.006 3.418]
[5.936 2.77 ]
[6.588 2.974]]
K-Means均值 =
[[5.77358491 2.69245283]
[ 5.006 3.418 ]
[ 6.81276596 3.07446809]]
分类正确率为 0.233333333333
GMM均值 =
[[5.01494511 3.44040237]
[ 6.69225795 3.03018616]
[ 5.90652226 2.74740414]]
分类正确率为 0.533333333333怒摔键盘啊,什么破正确率呀!!!憋急啊,我看事情并不简单。机智的我们观察一下均值矩阵。K-Means给出的第一行似乎和实际的第二行很接近,第二行和实际的第一行很接近。同样,GMM给出的均值矩阵也有同样的问题,第二行和第三行似乎对调了。这不是算法的锅啊,它只管给你聚类,哪里还能保证标签和你一样啊,三个类别六种标签方式人家算法也只能随机一种好吗,所以现在我们把预测的结果的标签改一下看看实际的正确率如何。
import numpy as np
from sklearn import datasets
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
#读取数据
iris=datasets.load_iris()
x=iris.data[:,:2]
y=iris.target
mu = np.array([np.mean(x[y == i], axis=0) for i in range(3)])
print '实际均值 = \\n', mu
#K-Means
kmeans=KMeans(n_clusters=3,init='k-means++',random_state=0)
y_hat1=kmeans.fit_predict(x)
y_hat1[y_hat1==0]=3
y_hat1[y_hat1==1]=0
y_hat1[y_hat1==3]=1
mu1=np.array([np.mean(x[y_hat1 == i], axis=0) for i in range(3)])
print 'K-Means均值 = \\n', mu1
print '分类正确率为',np.mean(y_hat1==y)
gmm=GaussianMixture(n_components=3,covariance_type='full', random_state=0)
gmm.fit(x)
print 'GMM均值 = \\n', gmm.means_
y_hat2=gmm.predict(x)
y_hat2[y_hat2==1]=3
y_hat2[y_hat2==2]=1
y_hat2[y_hat2==3]=2
print '分类正确率为',np.mean(y_hat2==y)
输出结果为
实际均值 =
[[5.006 3.418]
[ 5.936 2.77 ]
[ 6.588 2.974]]
K-Means均值 =
[[5.006 3.418 ]
[ 5.77358491 2.69245283]
[ 6.81276596 3.07446809]]
分类正确率为 0.82
GMM均值 =
[[5.01494511 3.44040237]
[ 6.69225795 3.03018616]
[ 5.90652226 2.74740414]]
分类正确率为 0.786666666667
啊,这样的结果还是比较让人满意的,甚至比前面的一些监督学习的结果还要好一些……另外,标签不一致的问题我这里采用的是最蠢的手动调整,大家当然可以根据你算出的均值矩阵每行与原始均值矩阵哪行的距离最小,确定它在原始数据中的标签自动调整,这当然是OK的,我这里偷一点懒。
好了,愉快的工作日又要结束了,哈哈哈,周末你好!!!
以上是关于机器学习笔记EM算法及实践(以混合高斯模型(GMM)为例来次完整的EM)的主要内容,如果未能解决你的问题,请参考以下文章