用NLP识别“假新闻”
Posted 数据挖掘之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用NLP识别“假新闻”相关的知识,希望对你有一定的参考价值。
摘要: 我们的目标是寻找一种利用自然语言处理(NLP)来识别和分类假文章的方法。我们收集数据,对文本进行预处理,并将文章转换为用于监督和非监督模型的特性。我们从一开始就知道,把一篇文章归类为“假新闻”可能有点灰色 ...
介绍 什么是假新闻?我们都听说过它,但它并不总是容易辨认。假新闻是一种黄色新闻或宣传,包括有目的的错误信息。传统上它通过印刷和广播媒介传播,但随着社交媒体的兴起,它现在可以通过病毒传播。因此,大型科技公司已开始采取措施应对这一趋势。例如,谷歌已经调整了新闻排名,以优先考虑知名网站,并禁止有传播虚假新闻历史的网站。Facebook已经将事实调查组织整合到了自己的平台中。 这个问题有多重要?BuzzFeed分析了2016年总统大选前和相关的20篇最常见的假新闻和真实新闻。他们发现,在Facebook上,那些最重要的假故事比真实故事更有吸引力。 工作流程 我们的目标是寻找一种利用自然语言处理(NLP)来识别和分类假文章的方法。我们收集数据,对文本进行预处理,并将文章转换为用于监督和非监督模型的特性。
数据收集 我们从一开始就知道,把一篇文章归类为“假新闻”可能有点灰色。因此,我们使用了一个现有的Kaggle数据集,该数据集已经收集和分类了假新闻。这些文章是使用B.S.检测器导出的,B.S.检测器是一个浏览器扩展,它搜索页面上的所有链接,查找对不可靠源的引用,并根据第三方域名列表对它们进行检查。由于这些假文章是在2016年11月从一个新闻聚合网站webhose.io收集的,所以我们从同一个站点和时间框架收集了我们的真实新闻数据。为了确保我们没有从数据集中的可疑来源收集文章,我们手动识别并筛选出可靠的组织列表(即“纽约时报”、“华盛顿邮报”、“福布斯”)。最后,我们的最终数据集包括23,000篇真实文章和11,000篇假文章。 文本预处理 文本分类模型的性能在很大程度上取决于语料库中的词和这些词所产生的特征。常见的单词(也称为停止词)和其他“嘈杂”元素增加了特征维度,但通常无助于区分文档。我们使用Python中的spacy和gensim包来标记文本,并执行以下预处理步骤:
这些步骤帮助减少了语料库的大小,并在特征转换之前添加了上下文。特别是,词形归并将每个单词转换为其词根形式,将不同的单词转换为一个单独的词。介绍情况。N-grams将附近的单词合并成单个特征,这有助于为那些本身可能没有什么意义的单词提供上下文。在我们的项目中,我们测试了bigrams 和 trigrams.两种模式。 将文本转换为特征 要对文本进行预处理后进行分析和建模,首先必须将其转换为特征。技术可能包括 TF-IDF或Word2vec。 Term Frequency - Inverse Document Frequency (TF-IDF) TF-IDF是一个统计数字,旨在反映一个词对语料库中的文件的重要性。它随着文档中单词出现的次数成比例增加,但在整个语料库中的频率却抵消了它的增加。在整个语料库的频率。虽然TF-IDF是提取描述性术语的一个很好的基本标准,但它没有考虑到一个词的位置或上下文。
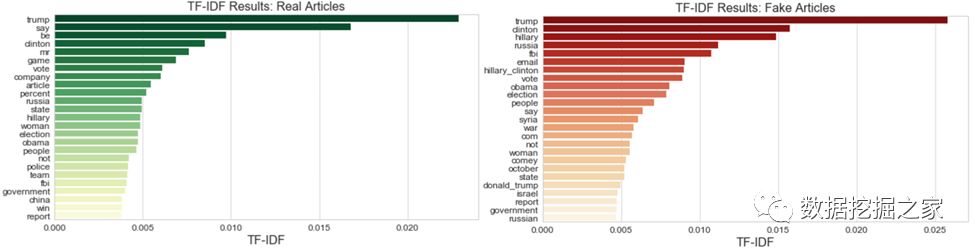
采用TF-IDF,我们发现在假新闻和真实新闻数据集中词汇的相对重要性。这两者之间有显著的重叠-“trump”是两类文章中最重要的词,而“clinton”、“fbi”和“email”等词也是名列前茅。
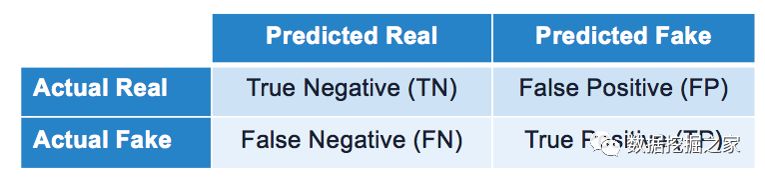
Word2Vec Word2vec技术将文本转换为特征,同时保持语料库中单词之间的原始关系。word2vec不是一个单一的算法,而是两种技术的结合-CBOW(连续的单词包)和skip-gram模型。两者都是浅层神经网络,它将单词映射到目标变量,而目标变量也是一个单词。这两种技术都学习作为单词向量表示的权重。 文字向量的质量随着训练数据的数量而显著增加,所以我们使用了在Google News数据集上训练过的向量(大约一千亿字)。模型包含三百万个单词和短语的300维向量。我们对每篇文章中的单词向量进行平均,以得到每个文档的单个向量表示。 分级 用不平衡的数据得分 由于我们的数据不是在两个类之间平均分配的,所以我们选择了度量模型时不会高估结果的度量标准。混淆矩阵对于分类方法中的结果度量是有用的。因为我们的目标是识别假新闻,那些我们正确地归类为假的是我们的真阳性,而虚假的文章,我们错误地归类为真实的是我们的假阴性(II型错误)。我们正确分类的真实文章是我们的真阴性,而错误分类的真实文章是我们的假阳性(I型错误)。
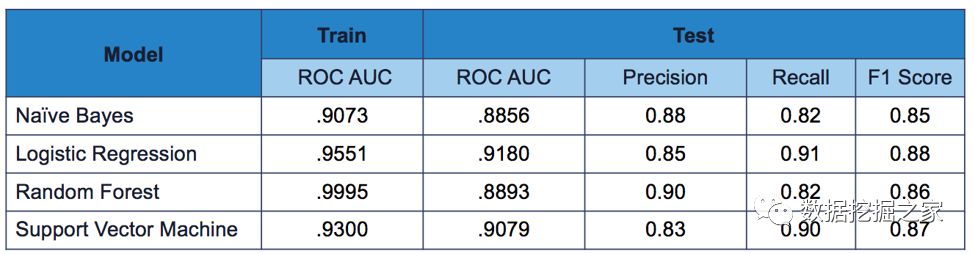
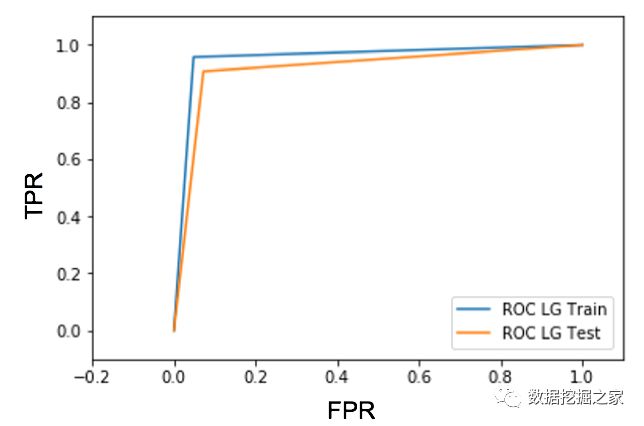
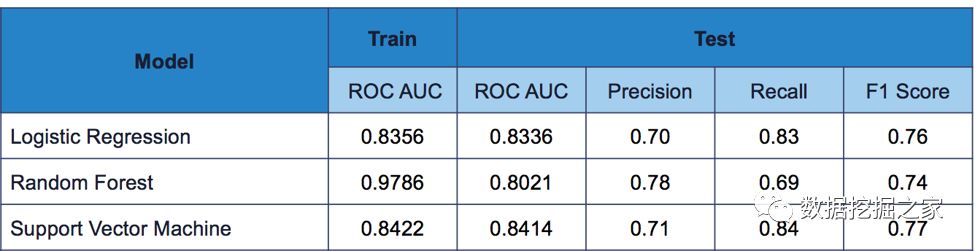
为了建立一个有效的模型,我们的目标是尽量减少假阴性和假阳性。F1评分有助于在准确性(假文章分类正确的超过预测为假的文章总数)和敏感性/召回(正确分类的假文章的比例)。 最后,我们使用ROC AUC评分来可视化我们的模型结果。ROC图y轴上的真阳性率(敏感性/召回率)和以及x轴上的假阳性率(我们分类不正确的真实新闻文章)。 模型结果 – TF-IDF 我们利用交叉验证和网格搜索,为TF-IDF算法和每个单独的模型寻找较佳参数。Logistic回归和支持向量机模型产生BEST结果使用 TF-IDF将我们的文本转换为特征。然而,Logistic回归模型的训练速度要快得多,从时间复杂性的角度来评价模型的性能是非常重要的。从下面的ROC图中可以看出,Logistic回归模型具有较高的灵敏性(它可以很好地预测假新闻文章)和较低的假阳性率(它没有预测大部分真实新闻是假的)。
Model Results – Word2Vec 我们还使用word2vec对每个模型进行了训练,以将文本转换为特征,但在所有模型类型中结果都很糟糕。
主题建模 由于我们的文章涵盖了广泛的主题,我们利用无监督的学习来更好地理解我们的数据。主题建模使我们可以在不必阅读每一篇文章的情况下描述和总结语料库中的文档。它通过使用每个文档中单词的频率来来发现单词的共现模式。 潜在Dirichlet分配(LDA)是NLP中最常用的描述文档的模型之一。LDA假设文档是由多种主题生成的,而主题是由与该主题相关的混合词生成的。此外,LDA假设这些混合物遵循Dirichlet概率分布。这意味着,对于每一份文档,我们可以假设只应包含少数几个主题,而对于每个主题,只有少数几个单词与该主题相关。例如,在一篇关于体育的文章中,我们不会期望找到很多不同的主题。 上图说明了这个过程。对于每个文档,该模型将从主题分布中选择一个主题,然后从基于该主题的发行版中选择一个单词。该模型将随机初始化和更新主题和单词,因为它迭代每一个文档,以找到一定数量的主题和相关的单词。超参数α和β可以分别用来控制每个文档的主题分布和每个主题的单词分布。高α意味着每个文档都可能包含大多数主题的混合(文档将出现更相似)。一个高β意味着每一个话题都可能包含大多数词的混合(话题看起来更相似)。 LDA是完全不受监督的,但是用户必须为模型提供特定数量的主题来描述整个文档集。对于我们的数据集,我们选择了20个主题。如下所示,主题没有命名,但是我们可以通过查看与每个主题相关的单词来更好地理解每个主题。 根据与主题2有关的词语,这似乎与选举有关。主题之间的距离直接关系到彼此之间的相似程度。正如我们所看到的,主题15与主题2相去甚远,很可能与艺术有关。 叠加模型的结果 对于最后一个模型,我们使用我们最初七个模型的预测生成了一个叠加模型。叠加模型通常比单个的模型更好,因为它们能够分辨出每个模型在哪里表现得好,哪里表现差。我们还将主题建模结果添加为新特性,以及每篇文章的长度以及是否有作者。 article and whether it had an author. 这些特征,再加上Logistic回归,给了我们相当好的结果--我们的假文章中只有34篇在2208的测试集中被错误分类,我们的AUC评分为0.9876。 结论 虚假新闻的兴起已经成为一个全球性的问题,就连Facebook和谷歌这样的大型科技公司也在努力解决这个问题。如果没有额外的上下文和人的判断,很难确定一个文本是否是事实性的。尽管我们的堆叠模型在测试数据上表现良好,但是对于来自不同时间段和主题分布的新数据,它可能表现得不太好。下图中显示了我们数据集中“最假”的单词,这是通过查看在虚假新闻中使用的比例比真实新闻更多的单词来确定的。 “hillary”、“clinton”和“email”等词在假新闻中的使用频率要高得多,其比例几乎为2:1。因此,我们的模型可能难以正确地对这些主题的新的真实文章进行分类,因为它们在假新闻中非常普遍。 写作风格也是区分真实新闻和假新闻的关键。随着时间的推移,我们将重新审视我们的文本预处理策略,以维护我们文章中的一些风格元素(即,大写、标点符号)并提高性能。 英文原文:https://blog.nycdatascience.com/student-works/identifying-fake-news-nlp/ 来源 :Dataguru.cn |


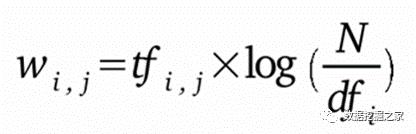
以上是关于用NLP识别“假新闻”的主要内容,如果未能解决你的问题,请参考以下文章
16.6 假新闻识别 Fake News Detection on Social Media A Data Mining Perspective
猖獗的假新闻:2017年1月1日起iOS的APP必须使用HTTPS!!!