16.5 多模态假新闻识别
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了16.5 多模态假新闻识别相关的知识,希望对你有一定的参考价值。
1、前言
假新闻,指在形式上模仿新闻媒体内容伪造的信息,往往是一些不正确的或是误导人的信息。当今,社交媒体已经成为人们获取、分享和评论新闻的主要平台。然而,社交媒体的便利性和开放性也导致了假新闻的广泛传播,从而对社会造成了严重影响。例如,新型冠状病毒(2019-nCoV)的爆发威胁着人们的身体健康,然而一些疫情相关的假新闻也在社 交媒体上广泛传播,这极大阻碍了防疫工作的开展。
手动收集和调查假新闻尽管更加准确,但同时也需要耗费大量的资源和时间。因此对于社交媒体上的海量帖子,自动检测假新闻是非常必要的。通过挖掘假新闻和真实新闻特征的区别(例如帖子内容,用户信息,传播过程等),然后使用传统机器学习方法或者深度学习方法进行假新闻的检测。早期的假新闻检测研究主要基于帖子和评论的文本内容和写作风格, 使用循环神经网络将事件中的帖子按时间序列建模,学习事件的潜在表示形式并进行预测。
除了帖子中的文本外,图像能更加直观地表达信息,因此视觉信息也有助于检测假新闻。结合文本、视觉和社交环境特征,对假新闻进行预测。一个新闻帖子通常伴随着一系列相关的帖子,本文将它们的集合称为事件。新闻事件可以提供更多的文本和图像信息,针对新闻事件进行预测非常有必要。先前的多模态检测相关研究对于文本特征和图像特征仅进 行简单的融合,且只针对单个帖子进行预测。
2、相关知识
与假新闻检测相关的任务有很多,例如谣言检测和不实信息异常检测等。假新闻检测任务的重点是如何根据相应的特征来将新闻分类。现有的假新闻检测研究主要分为基于内容的方法和基于网络的方法。其中基于内容的方法包括文本内容和图像内容等,本文主要介绍基于内容的研究。
早期基于内容的研究采用特征工程等方法从文本中提取人工特征,并利用传统机器学习方法如决策树、SVM 等进行分类。Castillo 等人 统计了推文文本中的单词数、特殊字符、情感词、关键词等语言特征,使用决策树来检测谣言。Gupta 等人加入了人称代词、URL数量、主题标签等统计特征。Feng 等人研究了欺骗检测的句法风格,利用浅语法规则进行分类。Ma 等人首次将深度神经网络应用于这一领域,通过将各个时间段内的推文文本向量输入双向 GRU 网络来学习新闻的特征表示,避免了传统的手动提取特征。Chen 等人将 注意力机制整合到递归神经网络(RNN)中,来特别关注文本的时态等语言特征。
近年来,基于内容的方法开始研究如何利用图像信息或者文本、图像的多模态信息来进行假新闻检测。Jin 等人证明了视觉特征在检测假新闻中的重要性,手动提取了图像中的一些统计特征,通过早期将文本和图像特征串联拼接在一起或者将后期的预测结果融合在一起进行假新闻的检测。之后 Jin 等人提出了一种基于深度学习的假新闻检测模型,该模型首次利用深度学习来提取文本、社交环境和视觉等多模态特征进行假新闻检测任务。为了更好地对新出现的新闻进行检测,Wang 等人引入了对抗网络来学习与事件无关的多模态特征。Khattar 等人使用变分自编码器(VAE)来学习多模态信息的特征表示。以上三种神经网络模型都利用 VGG 网络来获取视觉表示,为了更好地对视觉特征进行建模,Qi 等人提出了一种新的模型从频域和像素域分别提取图像的部分特征。但是上述多模态方法对于文本特征和图像特征的融合较为简单,并且是针对单个新闻帖子进行分类,没有考虑利用新闻事件进行分类。
3、模型结构
MEDN:多模态假新闻事件检测网络
- 提出了一种用于假新闻事件检测的模型,该模型利用一个事件中多个帖子的文本和图像进行预测。
- 提出了相应的多模态特征融合网络和假新闻事件检测网络,可以有效地提高假新闻事件检测的准确性。
- 提出了一种新颖的假新闻检测模型,该模型考虑了新闻事件中的多个帖子的多模态信息,并且对于多模态特征的融合使用了注意力机制。
社交网络上的新闻通常包含一系列相关的帖子,每个帖子包含不同模态的信息:文字和图像。旨在利用多个相关帖子的多模态信息来确定一个新闻事件是否为假新闻。
问题定义
单独的社交媒体帖子比较短、包含的信息有限, 而一个帖子通常存在一系列相关的其他帖子。本文考虑将这些相关的帖子作为一个事件进行输入,假新闻检测网络针对具体的事件进行预测。给定一个新闻事件的集合 E = { E i } \\mathrm{E}=\\left\\{E_{i}\\right\\} E={Ei}, 其中每个事件 E i = { P i , j } E_{i}=\\left\\{P_{i, j}\\right\\} Ei={Pi,j} 包含一系列相关的帖子 P i , j P_{i, j} Pi,j, 每个帖子包含文本、图像等多种信息, 本研究的任务是预测事件 E i E_{i} Ei 是否为假新闻。
本文将一个新闻事件实例 E i = { P i , j } E_{i}=\\left\\{P_{i, j}\\right\\} Ei={Pi,j} 表示为多个相关帖子的集合。所提出的模型利用了新闻事件中每个帖子 P i , j P_{i, j} Pi,j 的文本内容 T i , j T_{i, j} Ti,j 、视觉内容 V i , j V_{i, j} Vi,j, 旨在学习一种可靠的多模态表示形式。 首先, 把单个帖子的文本和图片分别通过深层 C N N \\mathrm{CNN} CNN 网络得到相应的特征表示 R T i , j , R V i , j R_{T_{i, j}}, R_{V_{i, j}} RTi,j,RVi,j 。然后,利用注意力机制将文本特征和视觉特征融合起来得到多模态特征表示 R M i , j R_{M_{i, j}} RMi,j 。最后,将新闻事件中的多个帖子的多模态特征一起作为输入, 判断新闻事件为真还是假。拟议的 M E D N \\mathrm{MEDN} MEDN 模型结构如图 1 所示。它包括四个组件: 文本特征提取器, 视觉特征提取器, 多模态特征融合子网和假新闻事件检测子网。
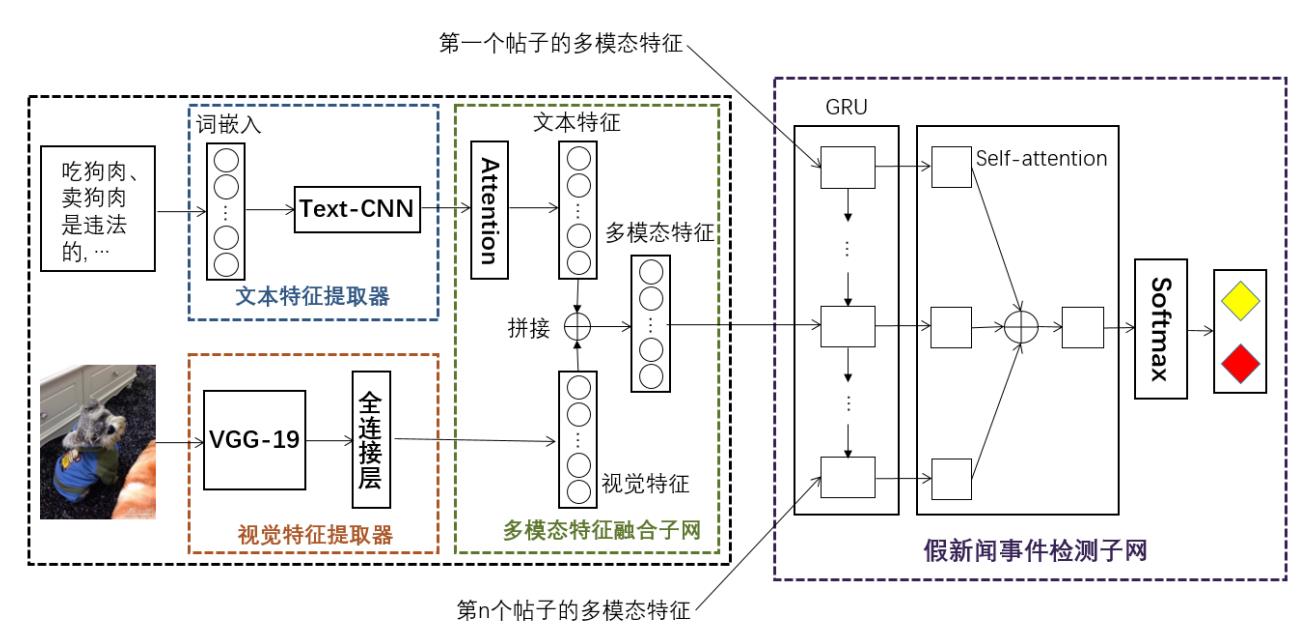
图
1
:
提
出
的
M
E
D
N
模
型
结
构
图 1: 提出的 MEDN 模型结构
图1:提出的MEDN模型结构
文本特征提取器
为了提取帖子的文本特征,模型中的文本特征提取器采用了卷积神经网络 ( C N N \\mathrm{CNN} CNN )。本 文采用了一种自然语言处理领域经典的 C N N \\mathrm{CNN} CNN 模型, T e x t − C N N \\mathrm{Text}-\\mathrm{CNN}^{ } Text−CNN 。该模型利用具有各种窗口大小的多个过滤器来捕获不同粒度的文本特征。
将每个帖子中单词的顺序列表作为文本特征提取器的输入。首先使用 Jieba 工具对帖子 中的文本进行分词。使用预训练的单词嵌入来初始化给定数据集。对于帖子文本中的第
i
i
i个 单词,相应的
k
\\mathrm{k}
k 维单词嵌入向量表示为
T
i
∈
R
k
T_{i} \\in R^{k}
Ti∈Rk 。假设新闻帖子的最大长度为
n
\\mathrm{n}
n, 少于
n
\\mathrm{n}
n 个单 词的帖子可以填充为长度为
n
\\mathrm{n}
n 的序列。因此,整个帖子可以表示为: 以上是关于16.5 多模态假新闻识别的主要内容,如果未能解决你的问题,请参考以下文章
T
1
:
n
=
T
1
⊕
T
2
⊕
T
3
⊕
⋯
⊕
T
n
(1)
T_{1: n}=T_{1} \\oplus T_{2} \\oplus T_{3} \\oplus \\cdots \\oplus T_{n}\\tag{1}
T1:n=T1⊕T2⊕T3⊕⋯⊕Tn(1)
其中
⊕
\\oplus
⊕是串联运算符。通常,令
T
i
:
i
+
j
T_{i: i+j}
Ti:i+j 表示单词
T
i
,
T
i
+
1
,
⋯
,
T
i
+
j
T_{i}, T_{i+1}, \\cdots, T_{i+j}
Ti,Ti+1,⋯,Ti+j 的串联。卷积运算涉及一个卷积滤波器
W
∈
R
h
k
W \\in R^{h k}
W∈Rhk, 该滤波器应用于帖子中
h
\\mathrm{h}
h 个连续单词的窗口以输出一个新特征。例如, 从第
i
\\mathrm{i}
i 个单词开始的
h
\\mathrm{h}
h 个连续单词的窗口生成新特征表示
t
i
t_{i}
ti :
t
i
=
σ
(
W
⋅
T
i
:
i
+
h
−
1
+
b
)
(2)
t_{i}=\\sigma\\left(\\mathrm{W} \\cdot T_{i: i+h-1}+\\mathrm{b}\\right)\\tag{2}
ti=σ(W⋅Ti:i+h−1+b)(2)
其 中
b
∈
R
b\\in R
b∈R 是一个偏差项, σ(∙) 是 ReLU 激活函数。将此过滤器应用于帖子
{
T
1
:
h
,
T
2
:
h
+
1
,
⋯
,
T
n
−
h
+
1
:
n
}
\\left\\{T_{1: h}, T_{2: h+1}, \\cdots, T_{n-h+1: n}\\right\\}
{T1:h,T2:h+1,⋯,Tn−h+1:n} 可以得到该帖子的一个特征向量:
t
=
[
t
1
,
t
2
,
⋯
,
t
n
−
h
+
1
]
(3)
\\mathrm{t}=\\left[t_{1}, t_{2}, \\cdots, t_{n-h+1}\\right]\\tag{3}
t=[t1,t2,⋯,tn−h+1](3)
其中
t
∈
R
n
−
h
+
1
t \\in \\mathrm{R}^{n-h+1}