16.6 假新闻识别 Fake News Detection on Social Media A Data Mining Perspective
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了16.6 假新闻识别 Fake News Detection on Social Media A Data Mining Perspective相关的知识,希望对你有一定的参考价值。
16.5 多模态假新闻识别
1、前言
主要是利用新闻的图像信息,将频域和像素域的特征进行融合,以用于假新闻检测。
假新闻帖子中的图片,不仅包含了恶意篡改的虚假图片,也包含了被错误地用来代表无关事件的真实图片。
假新闻图像和真新闻图像相比,在物理和语义层面都可能有着显著不同的特征,分别体现在频率域和像素域上。
本文提出MVNN(Multi-domain Visual Neural Network)框架,混合频域和像素域的视觉信息,以用于假新闻检测。
特别地,本文设计了一个基于CNN的网络,自动捕获假新闻图像在频域的复杂模式;并且利用了multi-branch CNN-RNN模型来从像素域不同语义级别上抽取视觉特征。然后使用注意力机制动态融合频域和像素域的特征表示。
2、相关知识
(1)假新闻图片的分类
假新闻图片可分为两类:
- 篡改的图像(Tampered images):被ps过的图片;
- 误导的图像(Misleading images):图文不一致,图片是真实的,但是内容会误导。这类图片通常源于艺术作品或者描述以前事件的图像。
(2)现有工作
现有的关于假新闻检测的工作大多关注于文本内容和社交上下文,很少有工作利用视觉信息来进行假新闻检测。
有一些工作通过抽取特征来评估图像的权威性,但是这些特征大多是人为设计的,以用于检测特定的修改痕迹,不能适用于误导的图像。
也有一些方法利用预训练的CNN,例如VGG19,来获得整体的视觉表示。这类方法由于缺乏任务相关的信息,难以捕获到假新闻图像的语义共性。
因此,如何有效地利用假新闻图像的内在特性以实现假新闻检测是一个挑战。
(3)假新闻图像和真新闻图像的区别
假新闻图像和真新闻图像在物理层面和语义层面可能都有着显著不同的特性:
-
在物理层面:
误导性图片:假新闻图像可能是低质量的,这就会明显地反应在频域(frequency domain)。例如,在社交平台上多次上传下载之后,误导性的图片通常比真实新闻的图片有更严重的重压缩伪影(re-compression artifacts),比如图 3所示的块效应。
篡改的图片:有不可避免的篡改痕迹。
重压缩的图像和篡改的图像通常在频域中表现出周期性,具有捕获空间(spatial)结构特征能力的CNN可以很容易地表征出这些特征。作者设计了基于CNN的网络,自动捕获假新闻图像在频域中的特性,如图 2上部分所示。

图 3 : 假 新 闻 图 片 和 真 实 新 闻 图 片 在 物 理 层 面 的 比 较 。 我 们 观 察 到 假 新 闻 形 象 ( a ) 有 明 显 的 块 效 应 , 而 真 实 新 闻 图 像 ( b ) 更 清 晰 。 我 们 放 大 了 两 幅 图 像 的 面 部 以 便 更 好 地 比 较 。 图 3:假新闻图片和真实新闻图片在物理层面的比较。我们观察到假新闻形象\\\\ (a)有明显的块效应,而真实新闻图像(b)更清晰。我们放大了两幅图像的面部以便更好地比较。 图3:假新闻图片和真实新闻图片在物理层面的比较。我们观察到假新闻形象(a)有明显的块效应,而真实新闻图像(b)更清晰。我们放大了两幅图像的面部以便更好地比较。
-
在语义层面
假新闻图像在像素域(即空域)也有一些明显的特性。假新闻发布者倾向于利用图像来吸引并误导读者,以实现新闻的快速传播。因此假新闻了图像通常有视觉冲击(visual impact)和情感挑衅(emotional provocations),如图 4所示。
这些特征已经被证实与许多视觉因素有关(从低水平到高水平);因此作者建立了一个multi-branch CNN-RNN网络,抽取不同语义层次的特征(如图 2下部分所示),在像素域充分捕获假新闻图像的特征。
将频域和像素域的视觉信息融合有助于提高假新闻检测模型的性能。但并不是所有的特征都对假新闻检测任务同等重要,因此作者使用注意力机制动态地从不同域融合这些视觉特征。

图 4 : 假 新 闻 图 片 与 真 新 闻 图 片 在 语 义 层 面 的 比 较 。 我 们 可 以 发 现 , 假 新 闻 图 片 比 真 实 新 闻 图 片 在 视 觉 上 更 引 人 注 目 , 在 情 感 上 更 具 有 煽 动 性 , 尽 管 它 们 描 述 的 是 同 一 类 型 的 事 件 , 如 火 灾 ( a ) 、 地 震 ( b ) 和 道 路 坍 塌 ( c ) 。 图 4:假新闻图片与真新闻图片在语义层面的比较。我们可以发现,假新闻图片比真实新闻图片在视觉上更引人注目,\\\\ 在情感上更具有煽动性,尽管它们描述的是同一类型的事件,如火灾(a)、地震(b)和道路坍塌(c)。 图4:假新闻图片与真新闻图片在语义层面的比较。我们可以发现,假新闻图片比真实新闻图片在视觉上更引人注目,在情感上更具有煽动性,尽管它们描述的是同一类型的事件,如火灾(a)、地震(b)和道路坍塌(c)。
本文提出MVNN框架,利用新闻的图片,通过结合频域和空域的信息学习到有效的视觉表示,以用于假新闻检测。
模型由三部分组成:
- 频域子网络(frequency domain sub-network ),捕获假新闻图像物理层面的特征;
- 像素域子网络(pixel domain sub-network),捕获假新闻图像语义级别的特征;
- 融合子网络(fusion sub-network),动态地融合这些特征。
本文贡献如下:
-
使用多域的视觉信息用于假新闻检测的研究工作,在物理层面和语义层面捕获到了假新闻图像的特性;
-
提出MVNN框架,利用了端到端的神经网络同时学习频域和像素域的表示,并有效地将两者融合;
3、模型结构
如图 2所示,MVNN包括3个主要模块:1)a frequency domain sub-network;2)a pixel domain sub-network;3)a fusion sub-network。
它主要由频域子网络、像素域子网络和融合子网络三部分组成。频域子网络首先将输入图像从像素域转换到频域,并利用基于cnn的模型捕获图像的物理特征。像素域子网络采用多分支CNN-RNN网络提取输入图像不同语义层次的特征。融合子网络通过注意机制动态融合频率域和像素域子网络获得的特征向量,将输入图像分类为假新闻图像或实新闻图像。
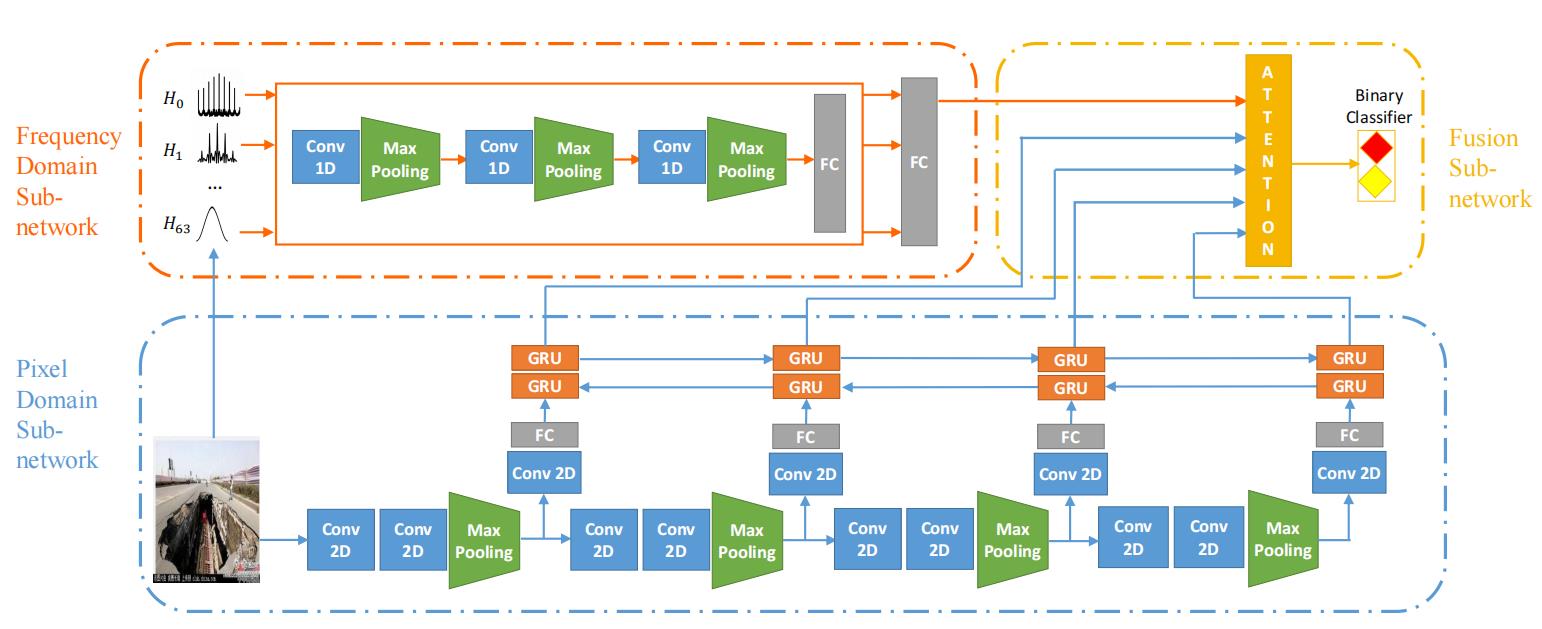
图 2 : 多 域 视 觉 神 经 网 络 ( M V N N ) 图 2:多域视觉神经网络(MVNN) 图2:多域视觉神经网络(MVNN)
对于一个输入图像,我们首先将其输入到频域和像素域子网络中以分别得到物理层面和语义层面的特征。然后将这些特征作为融合子网络的输入,以得到该图像最终的视觉表示,用于预测其是真新闻图像还是假新闻图像。
频域子网络
使用离散余弦变换(discrete cosine transform, DCT)将输入图像从像素域转换到频域。篡改的或重压缩的图像通常在频域上有周期性的特征,可以使用CNN捕获到这些特征。因此作者设计了基于CNN的网络,以捕获到假新闻图像在频域的特征,如图 5所示。

图 5 : 频 域 子 网 络 的 详 细 结 构 。 我 们 首 先 对 输 入 图 像 进 行 像 素 域 到 频 域 的 变 换 , 并 设 计 一 个 基 于 c n n 的 网 络 来 获 取 其 频 域 特 征 表 示 。 图 5:频域子网络的详细结构。我们首先对输入图像进行像素域到频域的变换,\\\\并设计一个基于cnn的网络来获取其频域特征表示。 图5:频域子网络的详细结构。我们首先对输入图像进行像素域到频域的变换,并设计一个基于cnn的网络来获取其频域特征表示。
- 对于输入图像,首先对其进行分块DCT,得到64个频率对应的DCT系数的64个直方图
- 然后在这些DCT系数直方图上进行1D Fourier transform,以增强CNN的影响。考虑到CNN需要固定大小的输入,因此对这些直方 图进行采样并得到64个250维的向量,表示成 { H 0 , H 1 , H 63 } \\left\\{H_{0}, H_{1}, H_{63}\\right\\} {H0,H1,H63} 。
- 预处理之后,每个输入向量被输入到共享的CNN网络,以得到相应的特征表示 { w 0 , w 1 , … , w 63 } 。 \\left\\{w_{0}, w_{1}, \\ldots, w_{63}\\right\\}_{\\text {。 }} {w0,w1,…,w63}。
这一CNN网络由3个卷积块和一个全连接层组成,每个卷积块都由一个一维的卷积层和一个最大池化层组成。为了加速模型的收敛,作者令卷积层中的过滤器数量递增。
已有的关于图像鉴别 (image forensics) 的工作通常只考虑了一部分频率的系数。本文作者发现所有的频率都对假新闻检测任务有帮助, 因此通过拼接将所有频率的特征向量进行融合得到特征表示 l 0 l_{0} l0, 并作为融合子网络的输入。
作者在实验中尝试了多种融合方法, 结果显示拼接 (concatenate) 操作在次任务中表现最好。
像素域子网络
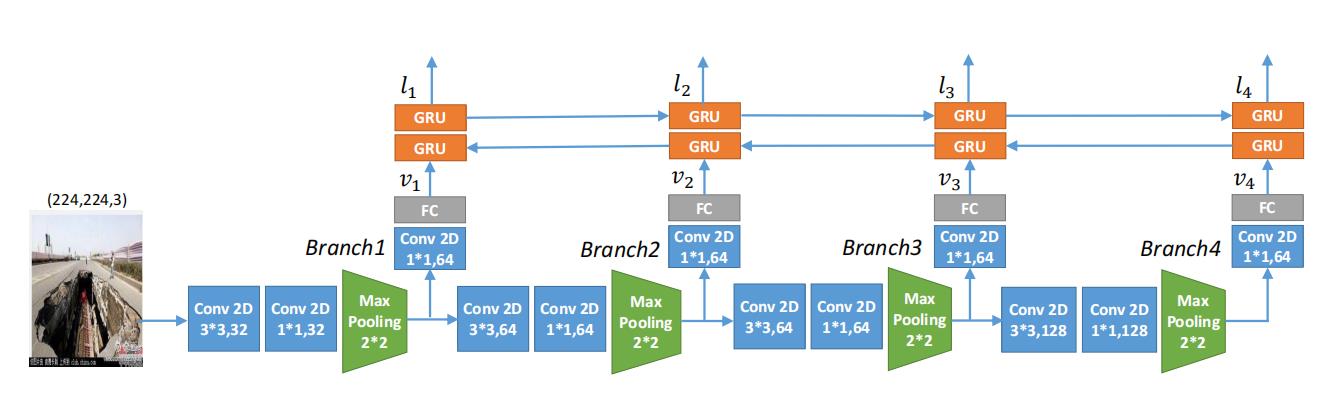
设计像素域子网络用于抽取输入图像在语义级别的视觉特征,如图 6所示。
图
6
:
像
素
域
子
网
的
详
细
结
构
。
对
于
输
入
图
像
,
我
们
利
用
多
分
支
C
N
N
R
N
N
网
络
在
像
素
域
提
取
其
不
同
语
义
层
次
的
特
征
。
图6:像素域子网的详细结构。对于输入图像,我们利用多分支CNNRNN网络在像素域提取其不同语义层次的特征。
图6:像素域子网的详细结构。对于输入图像,我们利用多分支CNNRNN网络在像素域提取其不同语义层次的特征。
靠前的卷积层倾向于捕获低层次的特征,例如颜色、线条和形状,后面的卷积层倾向于物体。在抽象的过程中,底层特征不可避免的会有损失,这进一步说明了CNN的底层和中间层可以为顶层提供补充信息。
许多工作已经证明对于某些任务(显著目标检测与图像情感分类),整合不同层的特征和仅使用高层次的特征相比,有助于实现更好的性能。我们前面也阐述了假新闻图像通常带有视觉冲击和情感挑衅,这些以及被证实和从低层次到高层次的许多视觉因素有关。
因此,为了捕获假新闻图像的语义特征,作者建立了multi-brach CNN网络以捕获不同层次的特征,并且利用Bi-GRU网络建模这些特征间的序列依赖。
如图 6所示,CNN网络主要由4块组成,每块由一个 3 × 3 3 \\times 3 3×3 卷积层和 1 × 1 1 \\times 1 1×1 卷积层以及一个最大池化层组成。将图片输入到CNN中,从4个branches中抽取的特征将经过一层 1 × 1 1 \\times 1 1×1 卷积和一层全连接层,以得到相应的特征向量 v t , t ∈ [ 1 , 4 ] v_t, t\\in [1,4] vt,t∈[1,4] 。这些特征表示图片的不同部分,例如line, color, texture(纹理), object。
受GoogLeNet中用到的Inception模块的启发,作者使用 1 × 1 1 \\times 1 1×1 卷积层来减小维度并增加模型的表示能力,因为它增加了非线性激活函数并促进了不同通道信息的融合。
不同层次的特征间有很强的依赖。例如,中间层次的纹理特征,是由低层次的线性特征组成的,同时也组成了高层次的特征,例如object。因此,作者使用Bi-GRU来建模低层次和高层次特征间的依赖。
r
t
=
σ
(
W
r
[
v
t
,
h
t
−
1
]
+
b
r
)
z
t
=
σ
(
W
z
[
v
t
,
h
t
−
1
]
+
b
z
)
h
~
t
=
tanh
(
W
h
~
[
v
t
,
r
t
⊙
h
t
−
1
]
+
b
h
~
)
h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
~
t
\\begin{gathered} r_{t}=\\sigma\\left(W_{r}\\left[v_{t}, h_{t-1}\\right]+b_{r}\\right) \\\\ z_{t}=\\sigma\\left(W_{z}\\left[v_{t}, h_{t-1}\\right]+b_{z}\\right) \\\\ \\tilde{h}_{t}=\\tanh \\left(W_{\\tilde{h}}\\left[v_{t}, r_{t} \\odot h_{t-1}\\right]+b_{\\tilde{h}}\\right) \\\\ h_{t}=\\left(1-z_{t}\\right) \\odot h_{t-1}+z_{t} \\odot \\tilde{h}_{t} \\end{gathered}
rt=σ(Wr[vt,ht−1]+br)zt=σ(Wz[vt,ht−1]+bz)