Spark WordCount 产生多少个 RDD
Posted Just do DT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark WordCount 产生多少个 RDD相关的知识,希望对你有一定的参考价值。
曾经在一次面试中被问到 Spark WordCount 产生多少个 RDD,您知道么?下面通过源码来说明经典的 WordCount 到底产生多少个 RDD。
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCountApp").setMaster("local[2]")
val sc = new SparkContext(conf)
val wc = sc.textFile("hdfs://hadoop001:9000/data/wordcount.txt")
.flatMap(x=>(x.split(","))).map(x=>(x,1)).reduceByKey(_+_)
.saveAsTextFile("hdfs://hadoop001:9000/data/output")
sc.stop()
}
}
textFile()
通过下面的源码,可以看到在这个方法中先调用了一个 hadoopFile 方法再调用 map 方法
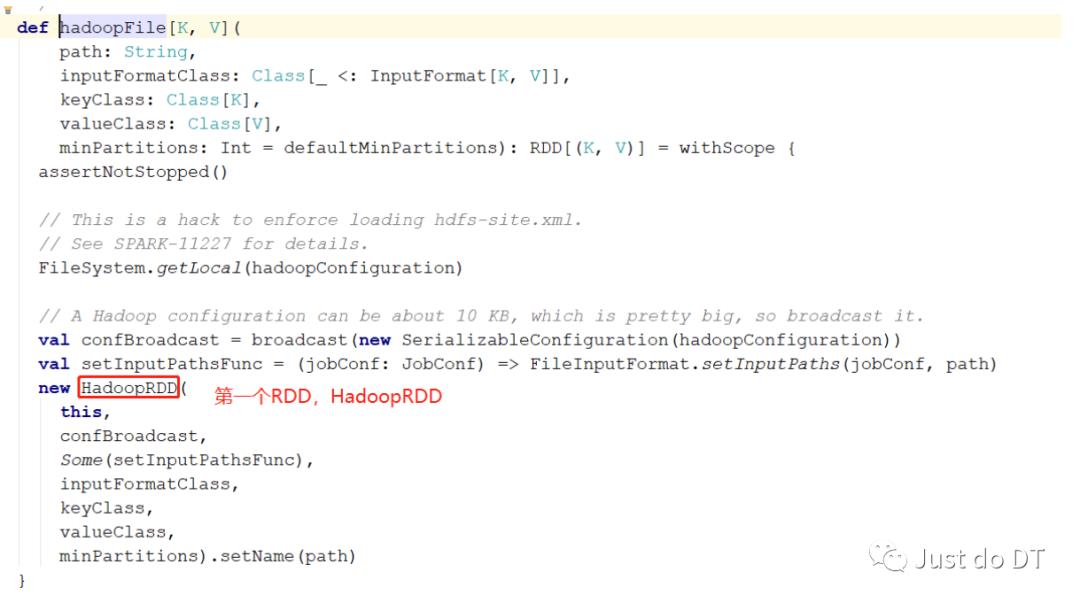
hadoopFile 方法返回的是个 RDD(HadoopRDD),在对这个RDD调用map方法,
点到map方法中可以看到 ,map方法中产生了一个MapPartitionsRDD


也就是说 textFile 产生 2个 RDD分别是 HadoopRDD 和 MapPartitionsRDD
flatMap ()

flatMap 产生了一个 RDD,MapPartitionsRDD
map()

map 产生了一个 RDD,MapPartitionsRDD
reduceByKey()
这里要注意啦,reduceByKey 虽然是一个 rdd 调用的,但 reduceByKey 这个方法不是 RDD 中的方法,我们可以在 RDD 中找到如下的一个隐式转换,当我们去调用reduceByKey 方法时,会发生隐式转换,隐式的 RDD 转化成了PairRDDFunctions这个类,reduceByKey 是 PairRDDFunctions 的方法

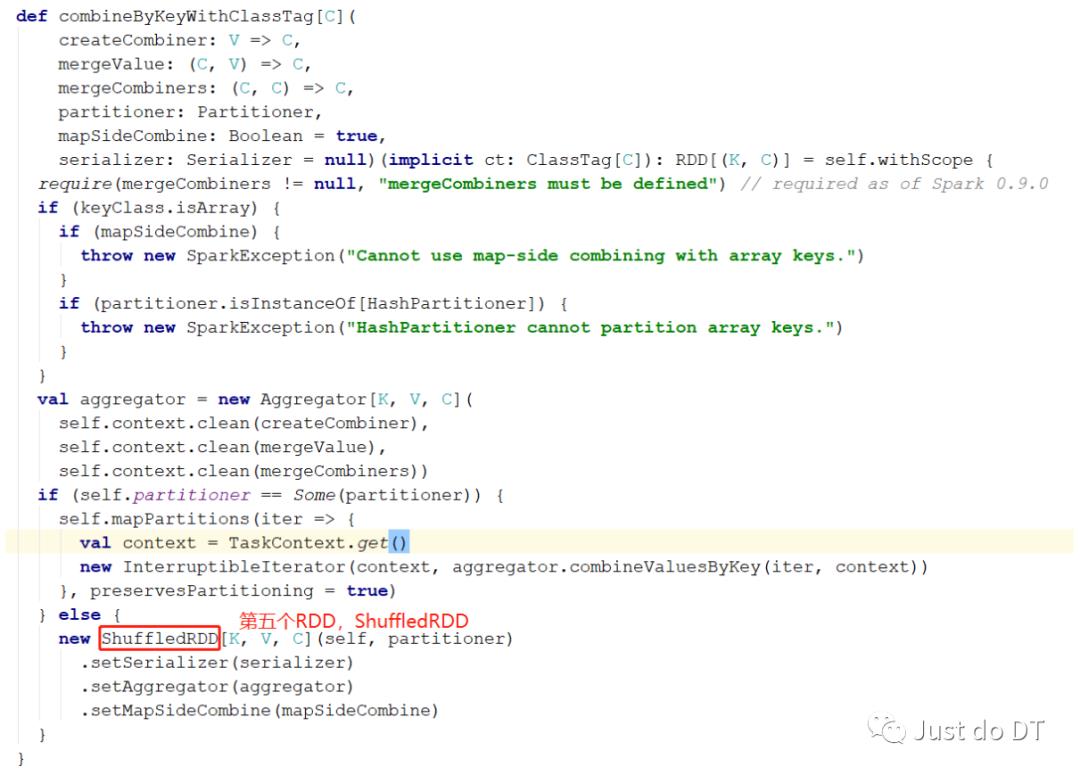
reduceByKey 产生了一个RDD,ShuffledRDD
saveAsTextFile()
其实,在执行saveAsTextFile之前,我们可以通过RDD提供的toDebugString看到这些个算子在调用的时候到底产生了多少个RDD
scala> val rdd = sc.textFile("file:///home/hadoop/data/wordcount.txt").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[9] at reduceByKey at <console>:24
scala> rdd.toDebugString
res1: String =
(2) ShuffledRDD[9] at reduceByKey at <console>:24 []
+-(2) MapPartitionsRDD[8] at map at <console>:24 []
| MapPartitionsRDD[7] at flatMap at <console>:24 []
| file:///home/hadoop/data/wordcount.txt MapPartitionsRDD[6] at textFile at <console>:24 []
| file:///home/hadoop/data/wordcount.txt HadoopRDD[5] at textFile at <console>:24 []
总结
我们可以看见在 Spark 的一个标准的 WordCount 中一共会产生 6 个 RDD,textFile() 会产生一个 HadoopRDD 和一个 MapPerPartitionRDD,flatMap() 方法会产生一个 MapPartitionsRDD,map() 方法会产生一个 MapPartitionsRDD ,reduceByKey() 方法会产生一个 ShuffledRDD,saveAsTextFile 会产生一个 MapPartitionsRDD,所以一共会产生 6 个 RDD。
以上是关于Spark WordCount 产生多少个 RDD的主要内容,如果未能解决你的问题,请参考以下文章