Spark任务提交与执行之RDD的创建转换及DAG构建
Posted 大冰的小屋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark任务提交与执行之RDD的创建转换及DAG构建相关的知识,希望对你有一定的参考价值。
在这里通过使用wordcount例子来学习Spark是如何进行任务的提交与执行。本次先进行RDD的创建、转换以及DAG的构建进行学习。
整个wordcount的代码可以简单如下实现:
sc.textFile("/library/wordcount/input").flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).collect.foreach(println)程序的DAG图如下:
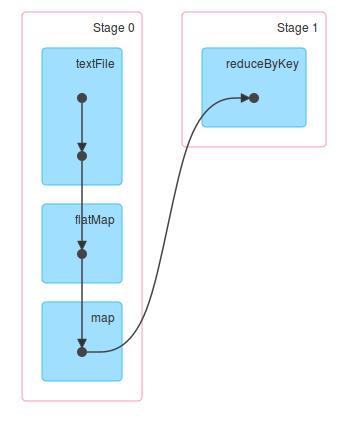
下面对每一步进行具体分析
1. textFile

SparkContext的testFile方法调用了hadoopFile方法用于创建HadoopRDD;其中hadoopFile方法包含三个步骤:
1. 将Hadoop的Configuration广播出去;
2. 设置文件输入路径;
3. 构建HadoopRDD实例对象;
对于构建的HadoopRDD实例对象调用map方法获得文件的内容,保存在MapPartitionsRDD类型的RDD中。在map方法中会调用clean方法,该方法实际调用ClosureCleaner的clean方法,这里是为了清除闭包中的不能被序列化的变量,防止RDD在网络传输过程中反序列化失败。
/**
* Read a text file from HDFS, a local file system (available on all nodes), or any
* Hadoop-supported file system URI, and return it as an RDD of Strings.
*/
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString)
def hadoopFile[K, V](
path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope
assertNotStopped()
// A Hadoop configuration can be about 10 KB, which is pretty big, so broadcast it.
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))
val setInputPathsFunc = (jobConf: JobConf) => FileInputFormat.setInputPaths(jobConf, path)
new HadoopRDD(
this,
confBroadcast,
Some(setInputPathsFunc),
inputFormatClass,
keyClass,
valueClass,
minPartitions).setName(path)
def map[U: ClassTag](f: T => U): RDD[U] = withScope
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
MapPartitionsRDD继承自RDD,在构造时调用了父类RDD的辅助构造器,可以看出MapPartitionsRDD的依赖关系为一对一的窄依赖。在这里依赖了HadoopRDD
/** Construct an RDD with just a one-to-one dependency on one parent */
def this(@transient oneParent: RDD[_]) =
this(oneParent.context , List(new OneToOneDependency(oneParent)))
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)
override def getParents(partitionId: Int): List[Int] = List(partitionId)
2. flatMap 一个元素映射到多个输出元素

对单词进行拆分,由于一行可以拆分出多个单词,所以需要使用flatMap而不是map操作。flatMap操作返回的还是MapPartitionRDD
/**
* Return a new RDD by first applying a function to all elements of this
* RDD, and then flattening the results.
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
3. map

这里的map操作和上面textFile方法中的map操作相同,都是获得MapPartitionsRDD。
4. reduceByKey

在上面map操作得到的MapPartitionsRDD中是没有reduceByKey方法的,那发生了什么呢?其实在这里发生了隐式转换,将MapPartitionsRDD转换成了PairRDDFunctions。隐式转换函数如下:
@deprecated("Replaced by implicit functions in the RDD companion object. This is " +
"kept here only for backward compatibility.", "1.3.0")
def rddToPairRDDFunctions[K, V](rdd: RDD[(K, V)])
(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null): PairRDDFunctions[K, V] =
RDD.rddToPairRDDFunctions(rdd)reduceByKey方法的定义如下,defaultPartitioner方法中会判断是未设置spark.default.parallelism属性,如果设置该属性则使用设定的值,否则默认为ShuffleRDD依赖的父RDD中最大的分区数。
/**
* Merge the values for each key using an associative reduce function. This will also perform
* the merging locally on each mapper before sending results to a reducer, similarly to a
* "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope
reduceByKey(defaultPartitioner(self), func)
/**
* Merge the values for each key using an associative reduce function. This will also perform
* the merging locally on each mapper before sending results to a reducer, similarly to a
* "combiner" in MapReduce.
*/
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner =
val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reverse
for (r <- bySize if r.partitioner.isDefined && r.partitioner.get.numPartitions > 0)
return r.partitioner.get
if (rdd.context.conf.contains("spark.default.parallelism"))
new HashPartitioner(rdd.context.defaultParallelism)
else
new HashPartitioner(bySize.head.partitions.size)
reduceByKey方法最终会调用combineByKeyWithClassTag方法,其处理步骤如下:
1. 创建Aggregator
2. 由于本例中当前RDD还没有设置Partitioner,self.partitioner != Some(partitioner),因而创建ShuffledRDD。
@Experimental
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray)
if (mapSideCombine)
throw new SparkException("Cannot use map-side combining with array keys.")
if (partitioner.isInstanceOf[HashPartitioner])
throw new SparkException("Default partitioner cannot partition array keys.")
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner))
self.mapPartitions(iter =>
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
, preservesPartitioning = true)
else
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
ShuffledRDD的依赖是ShuffleDependency。
@DeveloperApi
class ShuffledRDD[K: ClassTag, V: ClassTag, C: ClassTag](
@transient var prev: RDD[_ <: Product2[K, V]],
part: Partitioner)
extends RDD[(K, C)](prev.context, Nil)
...
override def getDependencies: Seq[Dependency[_]] =
List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
以上是关于Spark任务提交与执行之RDD的创建转换及DAG构建的主要内容,如果未能解决你的问题,请参考以下文章