Spark Streaming源码解读之RDD生成全生命周期详解
Posted snail_gesture
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming源码解读之RDD生成全生命周期详解相关的知识,希望对你有一定的参考价值。
本篇博客将详细探讨DStream模板下的RDD是如何被创建,然后被执行的。在开始叙述之前,先来思考几个问题,本篇文章也就是基于此问题构建的。
1. RDD是谁产生的?
2. 如何产生RDD?
带着这两个问题开启我们的探索之旅。
一:实战WordCount源码如下:
object WordCount
def main(args:Array[String]): Unit =
val sparkConf = new SparkConf().setMaster("Master:7077").setAppName("WordCount")
val ssc = new StreamingContext(sparkConf,Seconds(1))
val lines = ssc.socketTextStream("Master",9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x,1)).reduceByKey(_+_)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
- Dstream之间是有依赖关系。比如map操作,产生MappedDStream.
/** Return a new DStream by applying a function to all elements of this DStream. */
def map[U: ClassTag](mapFunc: T => U): DStream[U] = ssc.withScope
new MappedDStream(this, context.sparkContext.clean(mapFunc))
2. MappedDStream中的compute方法,会先获取parent Dstream.然后基于其结果进行map操作,其中mapFunc就是我们传入的业务逻辑。
private[streaming]
class MappedDStream[T: ClassTag, U: ClassTag] (
parent: DStream[T],
mapFunc: T => U
) extends DStream[U](parent.ssc)
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[U]] =
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
3. DStream:
a) 每个DStream之间有依赖关系,除了第一个DStream是基于数据源产生,其他DStream均依赖于前面的DStream.
b) DStream基于时间产生RDD。
* DStreams internally is characterized by a few basic properties:
* - A list of other DStreams that the DStream depends on
* - A time interval at which the DStream generates an RDD
* - A function that is used to generate an RDD after each time interval
*/
abstract class DStream[T: ClassTag] (
@transient private[streaming] var ssc: StreamingContext
) extends Serializable with Logging
至此,我们就知道了,RDD是DStream产生的,那么DStream是如何产生RDD的呢?
- DStream中的generatedRDDs的HashMap中每个Time都会产生一个RDD,而每个RDD都对应着一个Job,因为此时的RDD就是整个DStream操作的时间间隔的最后一个RDD,而最后一个RDD和前面的RDD是有依赖关系。
// RDDs generated, marked as private[streaming] so that testsuites can access it
@transient
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]] ()
generatedRDDs是DStream的成员,说明DStream的实例中均有此成员,但是实质在运行的时候指抓住最后一个DStream的句柄。
generatedRDDs在哪里被实例化的?搞清楚了这里的HashMap在哪里被实例化的话,就知道RDD是怎么产生的。
1. DStream中的getOrCompute会根据时间生成RDD。
/**
* Get the RDD corresponding to the given time; either retrieve it from cache
* or compute-and-cache it.
*/
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] =
// If RDD was already generated, then retrieve it from HashMap,
// or else compute the RDD
generatedRDDs.get(time).orElse
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
if (isTimeValid(time))
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false)
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details. We need to have this call here because
// compute() might cause Spark jobs to be launched.
PairRDDFunctions.disableOutputSpecValidation.withValue(true)
//compute根据时间计算产生RDD
compute(time)
//rddOption里面有RDD生成的逻辑,然后生成的RDD,会put到generatedRDDs中
rddOption.foreach case newRDD =>
// Register the generated RDD for caching and checkpointing
if (storageLevel != StorageLevel.NONE)
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD $newRDD.id for time $time to $storageLevel")
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration))
newRDD.checkpoint()
logInfo(s"Marking RDD $newRDD.id for time $time for checkpointing")
generatedRDDs.put(time, newRDD)
rddOption
else
None
2. 在ReceiverInputDStream中compute源码如下:ReceiverInputDStream会生成计算链条中的首个RDD。后面的RDD就会依赖此RDD。
/**
* Generates RDDs with blocks received by the receiver of this stream. */
override def compute(validTime: Time): Option[RDD[T]] =
val blockRDD =
if (validTime < graph.startTime)
// If this is called for any time before the start time of the context,
// then this returns an empty RDD. This may happen when recovering from a
// driver failure without any write ahead log to recover pre-failure data.
//如果没有输入数据会产生一系列空的RDD
new BlockRDD[T](ssc.sc, Array.empty)
else
// Otherwise, ask the tracker for all the blocks that have been allocated to this stream
// for this batch
// receiverTracker会跟踪数据
val receiverTracker = ssc.scheduler.receiverTracker
// blockInfos
val blockInfos = receiverTracker.getBlocksOfBatch(validTime).getOrElse(id, Seq.empty)
// Register the input blocks information into InputInfoTracker
val inputInfo = StreamInputInfo(id, blockInfos.flatMap(_.numRecords).sum)
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
// validTime是
// Create the BlockRDD
createBlockRDD(validTime, blockInfos)
Some(blockRDD)
3. createBlockRDD源码如下:
private[streaming] def createBlockRDD(time: Time, blockInfos: Seq[ReceivedBlockInfo]): RDD[T] =
if (blockInfos.nonEmpty)
val blockIds = blockInfos.map _.blockId.asInstanceOf[BlockId] .toArray
// Are WAL record handles present with all the blocks
val areWALRecordHandlesPresent = blockInfos.forall _.walRecordHandleOption.nonEmpty
if (areWALRecordHandlesPresent)
// If all the blocks have WAL record handle, then create a WALBackedBlockRDD
val isBlockIdValid = blockInfos.map _.isBlockIdValid() .toArray
val walRecordHandles = blockInfos.map _.walRecordHandleOption.get .toArray
new WriteAheadLogBackedBlockRDD[T](
ssc.sparkContext, blockIds, walRecordHandles, isBlockIdValid)
else
// Else, create a BlockRDD. However, if there are some blocks with WAL info but not
// others then that is unexpected and log a warning accordingly.
if (blockInfos.find(_.walRecordHandleOption.nonEmpty).nonEmpty)
if (WriteAheadLogUtils.enableReceiverLog(ssc.conf))
logError("Some blocks do not have Write Ahead Log information; " +
"this is unexpected and data may not be recoverable after driver failures")
else
logWarning("Some blocks have Write Ahead Log information; this is unexpected")
//校验数据是否还存在,不存在就过滤掉,此时的master是BlockManager
val validBlockIds = blockIds.filter id =>
ssc.sparkContext.env.blockManager.master.contains(id)
if (validBlockIds.size != blockIds.size)
logWarning("Some blocks could not be recovered as they were not found in memory. " +
"To prevent such data loss, enabled Write Ahead Log (see programming guide " +
"for more details.")
new BlockRDD[T](ssc.sc, validBlockIds)
else
// If no block is ready now, creating WriteAheadLogBackedBlockRDD or BlockRDD
// according to the configuration
if (WriteAheadLogUtils.enableReceiverLog(ssc.conf))
new WriteAheadLogBackedBlockRDD[T](
ssc.sparkContext, Array.empty, Array.empty, Array.empty)
else
new BlockRDD[T](ssc.sc, Array.empty)
4. map算子操作,产生MappedDStream。
/** Return a new DStream by applying a function to all elements of this DStream. */
def map[U: ClassTag](mapFunc: T => U): DStream[U] = ssc.withScope
new MappedDStream(this, context.sparkContext.clean(mapFunc))
5. MappedDStream源码如下:除了第一个DStream产生RDD之外,其他的DStream都是从前面DStream产生的RDD开始计算,然后返回RDD,因此,对DStream的transformations操作就是对RDD进行transformations操作。
private[streaming]
class MappedDStream[T: ClassTag, U: ClassTag] (
parent: DStream[T],
mapFunc: T => U
) extends DStream[U](parent.ssc)
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
//parent就是父DStream
override def compute(validTime: Time): Option[RDD[U]] =
// getOrCompute是对RDD进行操作,后面的map就是对RDD进行操作
//DStream里面的计算其实是对RDD进行计算,而mapFunc就是我们要操作的具体业务逻辑。
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
6. forEachDStream的源码如下:
/**
* An internal DStream used to represent output operations like DStream.foreachRDD.
* @param parent Parent DStream
* @param foreachFunc Function to apply on each RDD generated by the parent DStream
* @param displayInnerRDDOps Whether the detailed callsites and scopes of the RDDs generated
* by `foreachFunc` will be displayed in the UI; only the scope and
* callsite of `DStream.foreachRDD` will be displayed.
*/
private[streaming]
class ForEachDStream[T: ClassTag] (
parent: DStream[T],
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean
) extends DStream[Unit](parent.ssc)
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[Unit]] = None
override def generateJob(time: Time): Option[Job] =
parent.getOrCompute(time) match
case Some(rdd) =>
val jobFunc = () => createRDDWithLocalProperties(time, displayInnerRDDOps)
foreachFunc(rdd, time)
//此时考虑jobFunc中一定有action操作
//因此jobFunc被调用的时候就会触发action操作
Some(new Job(time, jobFunc))
case None => None
7. 在上述案例中print函数源码如下,foreachFunc函数中直接对RDD进行操作。
/**
* Print the first num elements of each RDD generated in this DStream. This is an output
* operator, so this DStream will be registered as an output stream and there materialized.
*/
def print(num: Int): Unit = ssc.withScope
def foreachFunc: (RDD[T], Time) => Unit =
(rdd: RDD[T], time: Time) =>
//action操作
val firstNum = rdd.take(num + 1)
// scalastyle:off println
println("-------------------------------------------")
println("Time: " + time)
println("-------------------------------------------")
firstNum.take(num).foreach(println)
if (firstNum.length > num) println("...")
println()
// scalastyle:on println
foreachRDD(context.sparkContext.clean(foreachFunc), displayInnerRDDOps = false)
上述都是从逻辑方面把RDD的生成流程走了一遍,下面我们就看正在开始是在哪里触发的。
- 在JobGenerator中generateJobs源码如下:
/** Generate jobs and perform checkpoint for the given `time`. */
private def generateJobs(time: Time)
// Set the SparkEnv in this thread, so that job generation code can access the environment
// Example: BlockRDDs are created in this thread, and it needs to access BlockManager
// Update: This is probably redundant after threadlocal stuff in SparkEnv has been removed.
SparkEnv.set(ssc.env)
Try
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
//生成Job
graph.generateJobs(time) // generate jobs using allocated block
match
case Success(jobs) =>
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
2. 在DStreamGraph中我们前面分析的RDD的产生的动作正在被触发了。
def generateJobs(time: Time): Seq[Job] =
logDebug("Generating jobs for time " + time)
val jobs = this.synchronized
//此时的outputStream就是forEachDStream
outputStreams.flatMap outputStream =>
val jobOption = outputStream.generateJob(time)
jobOption.foreach(_.setCallSite(outputStream.creationSite))
jobOption
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
RDD的创建和执行流程如下:
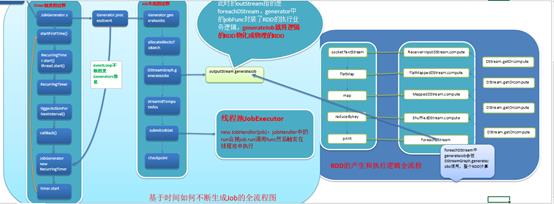
以上是关于Spark Streaming源码解读之RDD生成全生命周期详解的主要内容,如果未能解决你的问题,请参考以下文章
Spark Streaming源码解读之生成全生命周期彻底研究与思考
Spark Streaming源码解读之RDD生成全生命周期详解
Spark Streaming源码解读之Job动态生成和深度思考
Spark 定制版:009~Spark Streaming源码解读之Receiver在Driver的精妙实现全生命周期彻底研究和思考