Spark Streaming源码解读之生成全生命周期彻底研究与思考
Posted xuanlin的专栏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming源码解读之生成全生命周期彻底研究与思考相关的知识,希望对你有一定的参考价值。
本期内容 :
- DStream与RDD关系彻底研究
- Streaming中RDD的生成彻底研究
问题的提出 :
1、 RDD是怎么生成的,依靠什么生成
2、执行时是否与Spark Core上的RDD执行有什么不同的
3、 运行之后我们要怎么处理
为什么有第三点 : 是因为Spark Streaming 中会随着相关触发条件,窗口Window滑动的时候都会不断的产生RDD ,
从最基本的层次考虑,RDD也是基本对象,每秒会产生RDD ,内存能不能完全容纳,每个处理完成后怎么进行管理?
一、 整个Spark Streaming操作的InPutDStream的流程源码


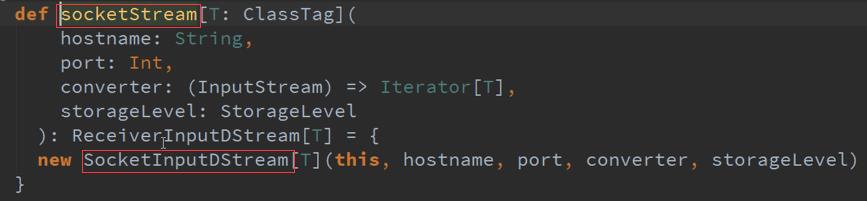
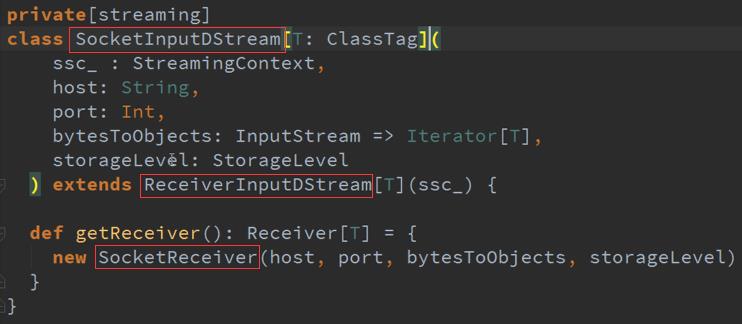
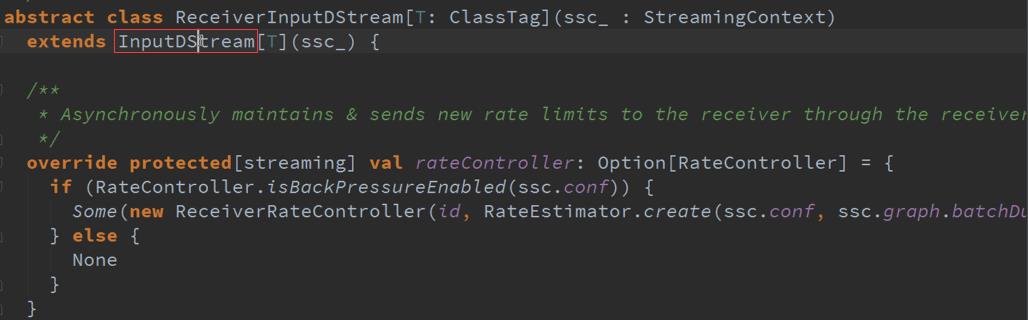
ForEachDStreams的产生有两种方式 :
1、 一种是DStreams 的Action,这是作业的产生且执行
2、 ForEachRDD也会产生ForEachDStreams,如果在ForEachRDD中没有Action级别的操作的话是不会执行作业的,
ForEachDStreams 不一定会触发Job的执行,但是一定会触发Job的产生,这句话是假的,因为是需要定时器Time与业务逻辑代码来产生的
ForEachDStreams 与Job的关系 :
1、 ForEachDStreams 与Job是否执行实际上是没有什么关系的,不一定触发Job的执行
2、 有ForEachDStreams的时候会产生Job ,这句话是假的,在没有ForEachDStreams的时候也会继续产生Job
Job的产生与业务逻辑代码没有什么关系,只是跟框架的调度,框架的定时器时间到了就会产生Job
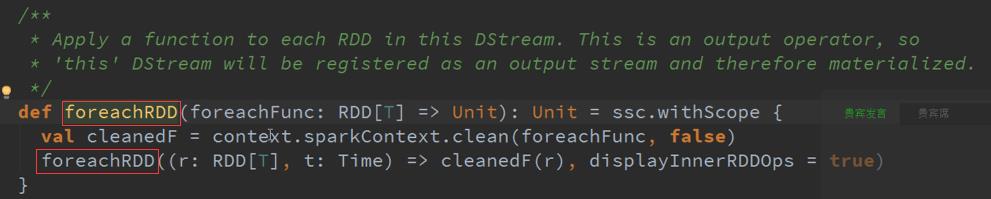

ForEachRDD是Spark RDD的后门,因为其是直接对RDD进行操作,但是背后还是封装成了ForEachStream,实际上在流处理中直接对RDD进行操作,但是本身还是产生了DStreams,在这个Spark Streaming的逻辑操作中,我们看到的都是对DStreams进行操作,其实就是对DStreams进行操作就是对RDD进行操作,DStreams就是RDD的一套模板,后面的DStreams对前面的DStreams有依赖。
为什么说后面的DStreams对前面的DStreams有依赖呢?源码如下:


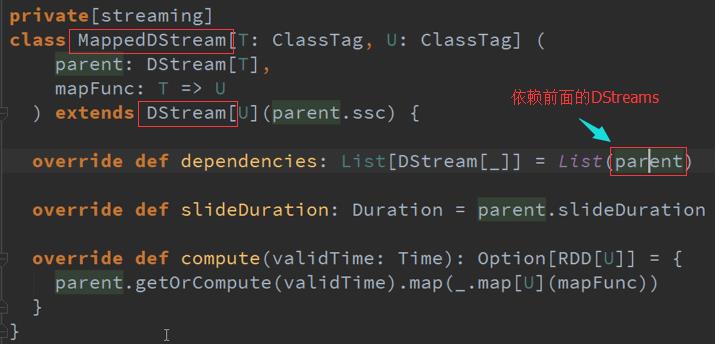
DStreams依赖以其它的DStreams ,除了第一个DStreams ,因为其是数据源产生的。
基于DStreams是怎么产生RDD ,是时间Time通过函数来产生的RDD ,是RDD的模板。
要研究RDD到底是怎么生成的 ,查看整个DStreams的操作,肯定有地方触发使RDD的生成,根据源码的路径跟踪RDD到底是怎么生成的 ?
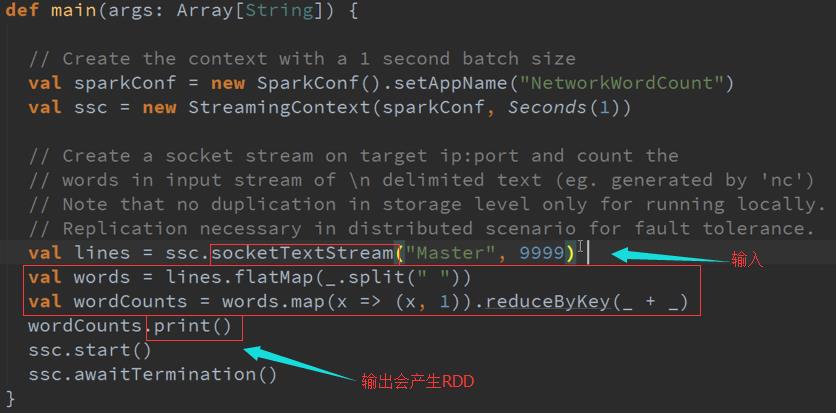
RDD的生命周期 : 均是后面依赖前面,每一步都会产生DStreams实例,DStreams是RDD的模板
为什么DStreams是从后面依赖前面的呢? DStreams必须是后往前依赖,有三点目的:
1、 是代表Spark Streaming级别的业务逻辑操作
2、 目的是根据这个生成RDD ,而RDD就是从后往前依赖的
3、 DStreams是lazy级别的,lazy级别是从后往前依赖奠定了基础
最重要的原因是第二点,DStreams的依赖必须要与RDD的依赖保持高度的一致,因为要根据时间间隔去生成RDD

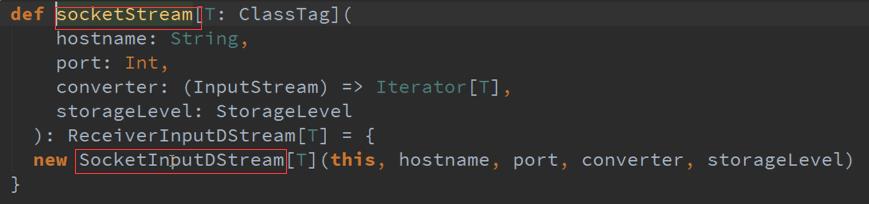
流程总结 :
从产生级别理解,每一个RDD都对应一个Job ,就是DStreams操作的最后的一个RDD ,最后的RDD对前面有依赖关系,只要有最后一个RDD就可以推导出所有的RDD
每一个DStreams的实例都有一个GeneratedRDD ,都有HashMap ,实际上执行的时候我们只需要关注最后一个,实际计算时就是从后往前推。
逻辑级别 :有一个又一个的DStreams对象,通过Map等操作都会产生DStreams对象,DStreams模板会随着时间的推移会产生一系列的RDD ,随着时间实例的推移,有时间注入就会产生RDD。
实际执行 : Spark STreaming操作就看最后一个DStreams ,从后往前找出RDD的依赖关系,相当于一个矩阵,加上时空维度。

GeneratdRDD是怎么获取的 :
DStream里面有个GetorCompute方法,就是根据时间生成RDD ,可能是缓冲级别获取的,或者计算出来的。
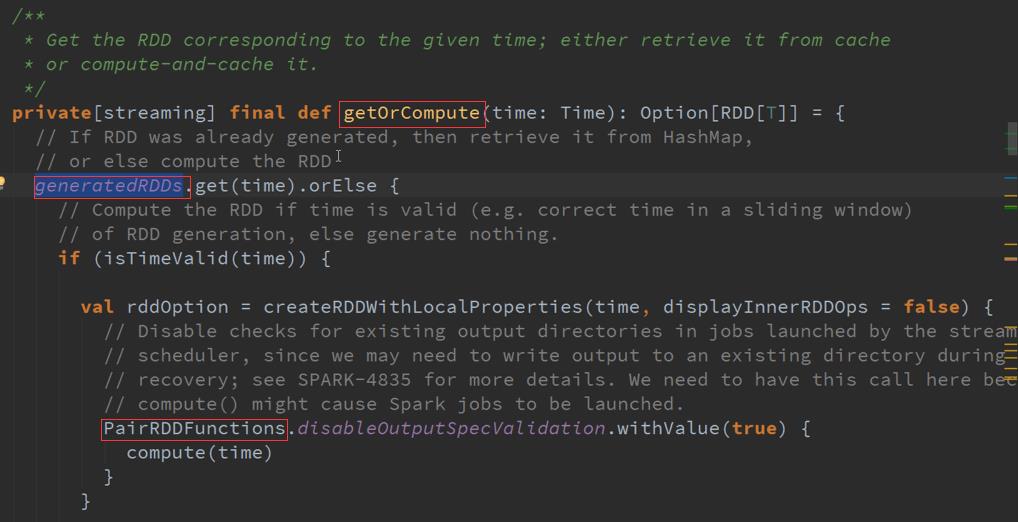
如果没有依赖就必将是自力更生:
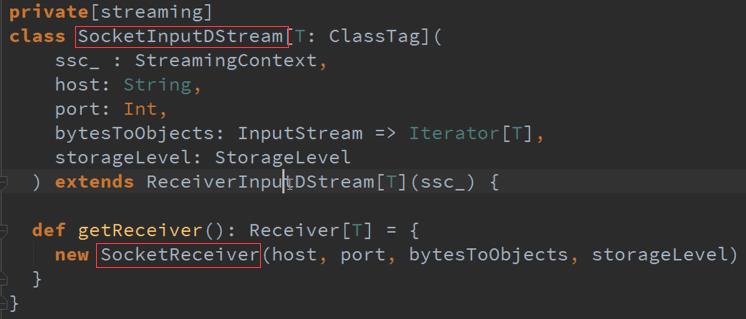
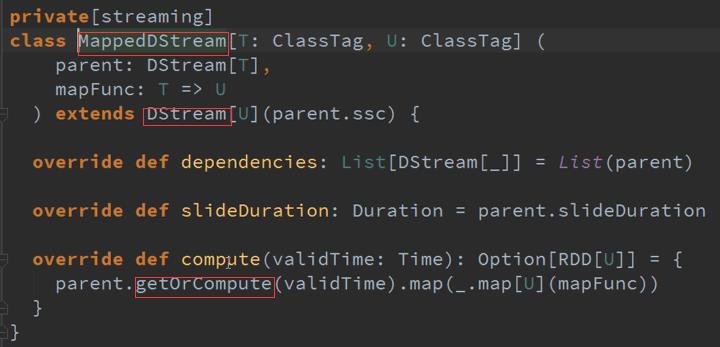
Map的DStreams ,是有依赖的,GetOrCompute产生RDD ,看到很多DStreams其实就是一个DStreams ,DStreams是逻辑级别的呈现,都是从后往前推.
Map会对RDD进行操作,DStreams里面的计算其实就是对RDD进行计算。
GetOrCompute返回的是RDD ,还有一个就是ForEachDStreams :
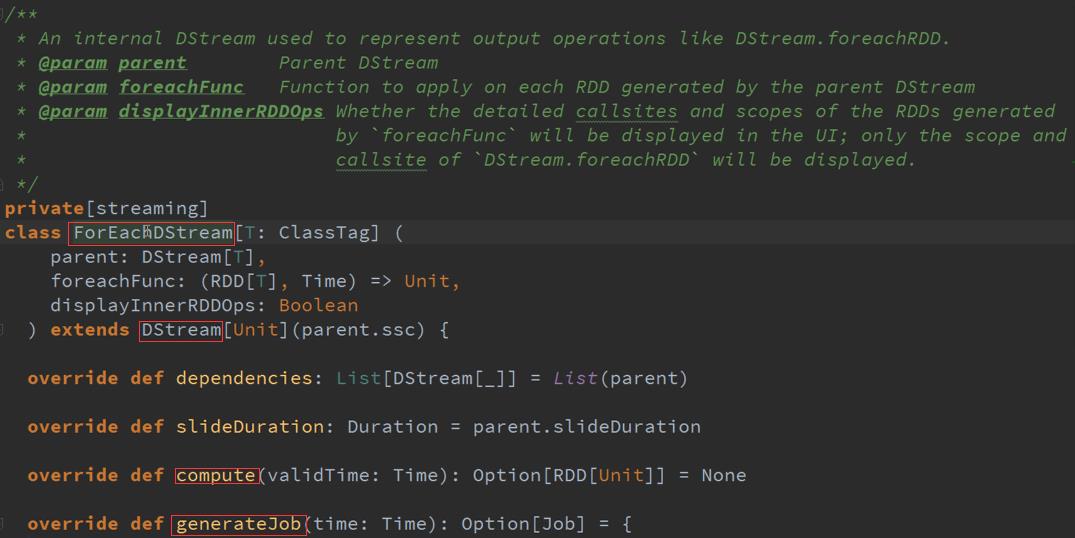
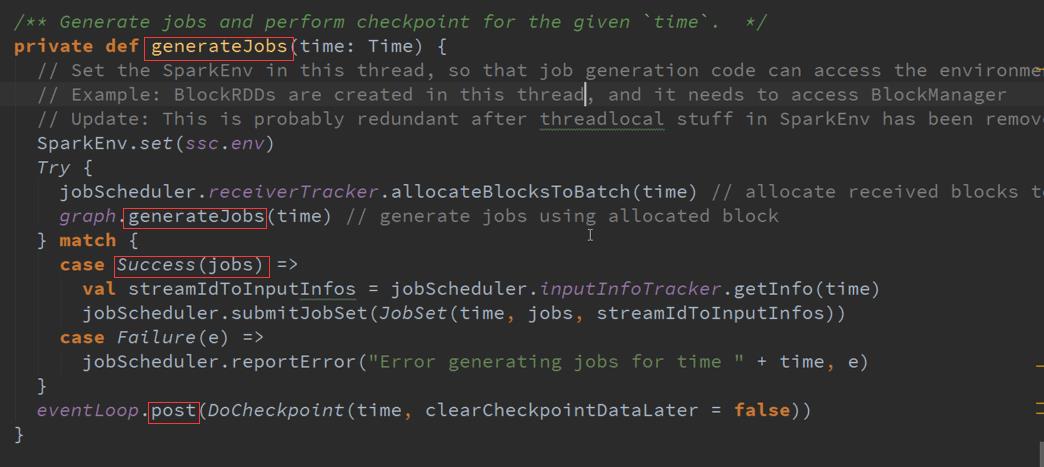
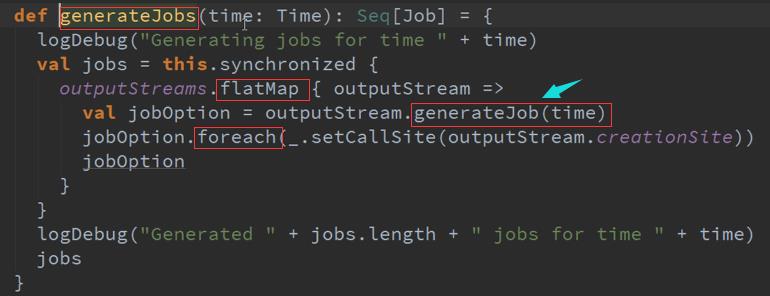
GenerateJob是通过调度器控制的 :
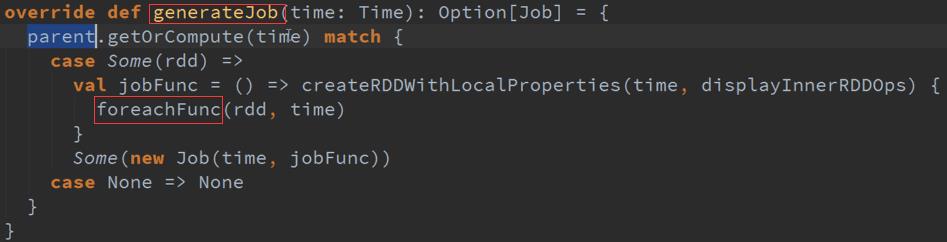
GenerateJob会去调用DStreams ,然后会调度到GenerateJob :
以上是关于Spark Streaming源码解读之生成全生命周期彻底研究与思考的主要内容,如果未能解决你的问题,请参考以下文章
Spark 定制版:008~Spark Streaming源码解读之RDD生成全生命周期彻底研究和思考
Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
Spark发行版笔记9:Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
Spark Streaming源码解读之RDD生成全生命周期详解
第9课:Spark Streaming源码解读之Receiver在Driver的精妙实现全生命周期彻底研究和思考
Spark 定制版:009~Spark Streaming源码解读之Receiver在Driver的精妙实现全生命周期彻底研究和思考