Spark全栈数据分析之飞机飞行记录
Posted 欢欢见闻
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark全栈数据分析之飞机飞行记录相关的知识,希望对你有一定的参考价值。
本篇文章主要用来记录Spark处理飞机飞行记录的过程,该应用依赖一文中分析出的本地文件,通过Spark批处理的方式对数据挖掘,这种方法符合处理大数据的要求。
飞行记录主要包括:
起飞机场,飞行日期,航班号,起降地,飞机编号6部分信息。
1. 将文件加载到内存,并保存到临时表中:
file_path = '/opt/spark-data/on_time_performance.parquet'on_time_dataframe = spark.read.parquet(file_path)on_time_dataframe.registerTempTable("on_time_dataframe")
2. 使用SparkSQL对数据进行整理:
flights = on_time_dataframe.rdd.map(lambda x: (x.Carrier, x.FlightDate, x.FlightNum,x.Origin, x.Dest, x.TailNum))flights.first()
这里从文件中提取对应的6个字段,然后每条记录放在一个元组中。
3. 使用规约函数对数据进行合并整理:
flights_per_airplane = flights.map(lambda xTuple:(xTuple[5], [xTuple[0:5]]) )\.reduceByKey(lambda a, b : a + b)\.map(lambda tuple:{'TailNum': tuple[0],'Flights': sorted(tuple[1], key=lambda x: (x[1], x[2], x[3], x[4]))})flights_per_airplane.first()
这里主要使用reduceByKey函数进行处理,该函数会寻找相同key的数据,当找到这样的两条记录时会对其value(分别记为x,y)做(x,y) => x+y的处理,即只保留求和之后的数据作为value。反复执行这个操作直至每个key只留下一条记录。我们这里的key为xTuple[5],也即对应的飞机编号,value值为列表。通过这种方法实现同一飞机编号飞行记录的合并。
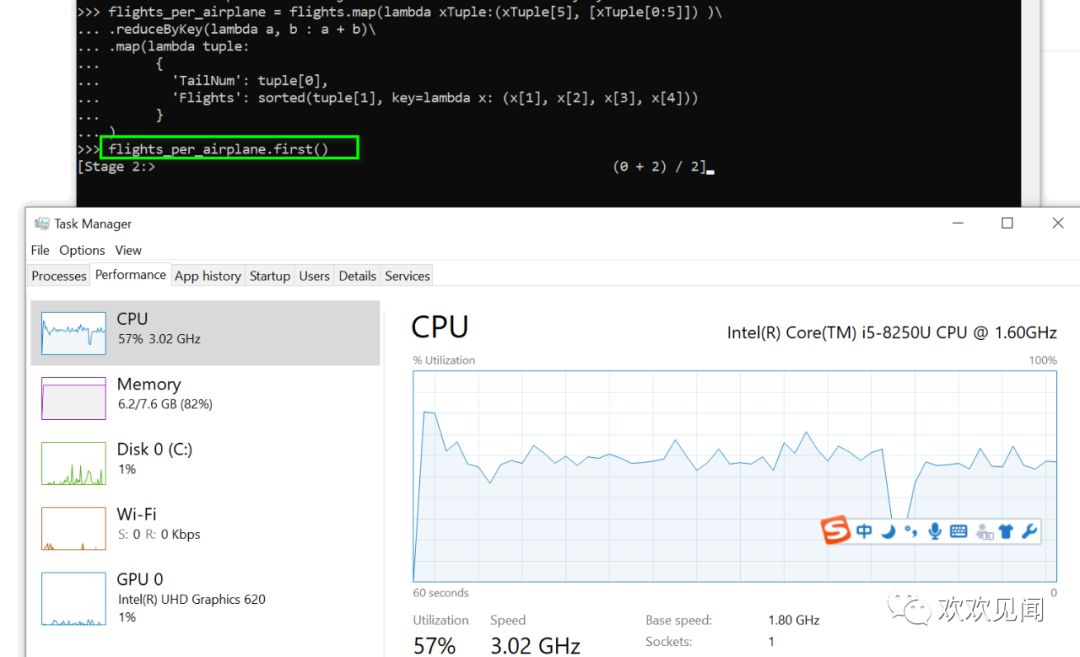
上图查看一条对应的合并记录,这是一个耗时的工作,大概需要4-5分钟。
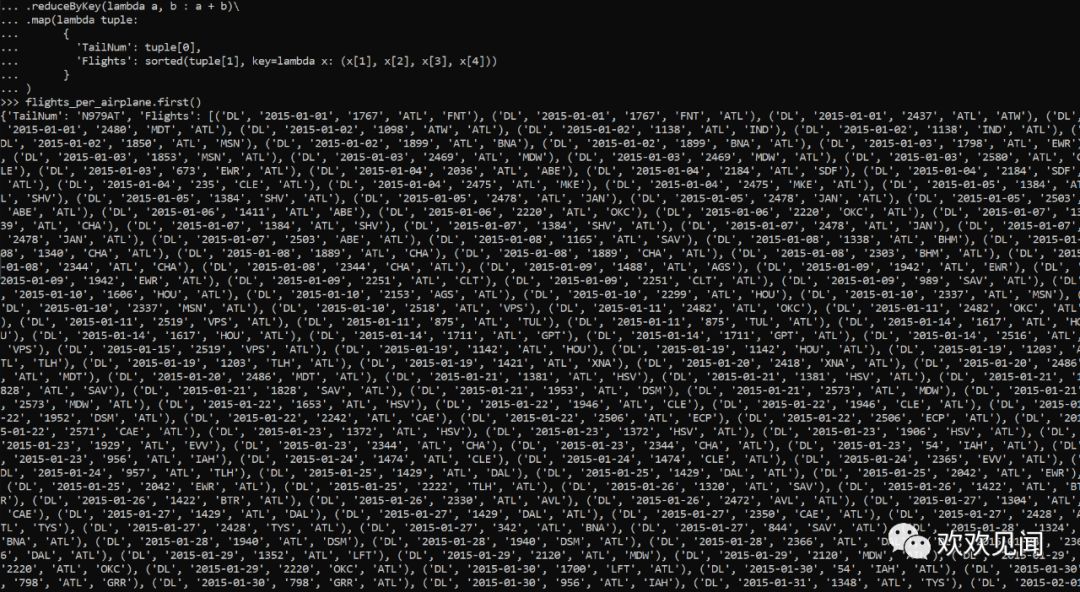
结果显示一飞机的飞行记录数据是很多的,也即意味着flights列表中的数据会有很多条。
4. 查看不同飞机编号的总数:
count = flights_per_airplane.count()print(count)
这里显示规约处理后的数据总条数,也即飞机数量:
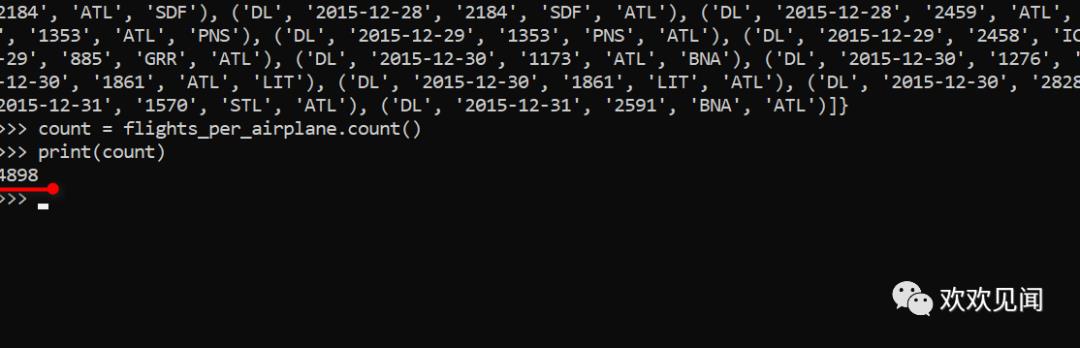
也即500万/5000,也即意味着一架飞机在一年平均飞行1000次。
5. 将飞机飞行记录保存到mongodb
import pymongo_sparkpymongo_spark.activate()mongo_url = 'mongodb://admin:123456@192.168.31.48:27017/admin.flights_per_airplane'flights_per_airplane.saveToMongoDB(mongo_url)
这里代码与前文别无二致,唯一的担心是flights字段值太大,会影响导入。
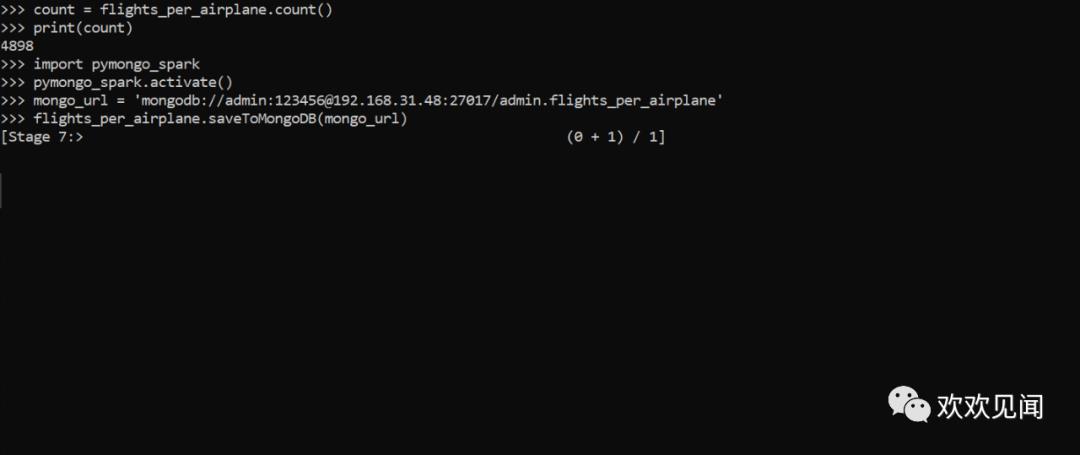
等待几分钟后,竟然报OOM错误:
不过查看mongdb数据库,大概导入了一半的数据:
这个错误该如何解决,是本机内存不够用造成的么?或许加大内存是一个选择,或者通过技术手段解决。
以上是关于Spark全栈数据分析之飞机飞行记录的主要内容,如果未能解决你的问题,请参考以下文章
13.6-全栈Java笔记:打飞机游戏实战项目|Shell|speed|launchFrame