人工智能神经网络不训练检测模型,如何进行对象的检测与追踪?
Posted 珲春
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能神经网络不训练检测模型,如何进行对象的检测与追踪?相关的知识,希望对你有一定的参考价值。
前面的文章,小编分享了很多关于目标检测与目标追踪的文章,且使用python方面的目标检测算法打造了自己的目标追踪专栏文章,小伙伴们可以参考
由于目标检测算法太大,需要大量的计算机的计算能力,在小型的应用场景中,使用YOLO系列,或者SSD对象检测(虽然SSD算法简单,模型较小),Fast-RCNN 等等对象检测算法,需要配备高计算能力的计算机,有没有简单的适合小型应用场景的目标检测与追踪算法??本期我们利用OpenCV的背景分割技术来实现。
背景分割技术在许多计算机视觉应用十分常见,比如统计小区入门的车辆与人数量,商场进入人流量等等。这里我们将其用于运动检测与运行追踪上。
OpenCV中执行运动检测,跟踪和分析的方法很多。有些比较简单,还有一些比较复杂。但都是基于高斯混合模型的前景和背景分割技术的方式实现,我们采用基于贝叶斯(概率)的前景和背景分割技术。
视频流的背景在很大程度上是 静态的,并且在视频的连续帧中保持不变,这里我们首先收集背景图片,在没有任何物体移动的情况下,把这张图片定义为背景。因此,如果我们可以对背景进行计算检测,则可以对其内部的移动物体进行监视。如果背景里面有移动物体的存在,我们可以检测到此运动物体,并实时进行物体的追踪。
显然在现实世界中,由于阴影,反射,照明条件以及环境中任何其他可能的变化,我们的背景在视频的各个帧中看起来可能完全不同。如果背景看起来不同,则可能会使我们的算法失效。这就是为什么最成功的背景减法/前景检测系统使用固定安装的摄像机并在可控制的照明条件下使用的原因。
背景分割技术,讲的明白一些就是收集背景图片,此图片作为参考图片,当有移动物体进入背景后,实时对当前视频帧图片与背景帧图片进行对比,进而检测出运动物体的存在,并实时进行追踪

Python代码实现背景分割技术 import datetimeimport timeimport cv2vs = cv2.VideoCapture(0)time.sleep(2.0)firstFrame = None
首先,我们导入需要的第三方库,并打开笔记本的默认摄像头,定义第一帧,也是背景帧图片
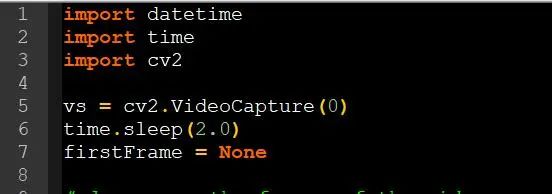
摄像头打开后,默认会使用第一帧图片作为背景图片,当运行软件时,请先设置好摄像头的位置以及环境背景灯光等能够影响到背景的因素,避免后期计算产生错误的数据
while True: ret, frame = vs.read() text = "find nothing" if frame is None: break frame = cv2.resize(frame, (500, 600)) gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) gray = cv2.GaussianBlur(gray, (21, 21), 0) if firstFrame is None: firstFrame = gray continue frameDelta = cv2.absdiff(firstFrame, gray) thresh = cv2.threshold(frameDelta, 25, 255, cv2.THRESH_BINARY)[1] thresh = cv2.dilate(thresh, None, iterations=2) cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cnts = cnts[0]
ret, frame = vs.read()为读取视频的一帧图片frame = cv2.resize(frame, (500, 600))这里对视频帧图片进行resize,避免后期大量的图片对比计算gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)转换图片到灰度空间gray = cv2.GaussianBlur(gray, (21, 21), 0)对图片进行高斯模糊,关于此函数,可以参考小编以前的文章
你是不是认为视频中的马赛克是后期添加的,这篇文章颠覆你的想象
frameDelta = cv2.absdiff(firstFrame, gray)然后计算前景图片与背景图片的差值thresh = cv2.threshold(frameDelta, 25, 255, cv2.THRESH_BINARY)[1]thresh = cv2.dilate(thresh, None, iterations=2)
若差值小于25,我们认为此处没有要检测的物体,并把此处设置为黑色(即背景色),若差值大于25,我们认为此处存在要检测的物体,设置前景色为白色
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)cnts = cnts[0]
前景一旦检测到后,便可以计算出前景的轮廓,并保存下来,以便后期处理
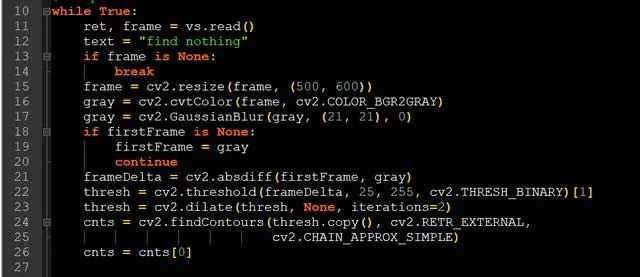
for c in cnts: if cv2.contourArea(c) < 500: continue (x, y, w, h) = cv2.boundingRect(c) cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2) text = "find something" cv2.putText(frame, "Status: {}".format(text), (10, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2) cv2.putText(frame, datetime.datetime.now().strftime("%A %d %B %Y %I:%M:%S%p"), (10, frame.shape[0] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 255), 1) cv2.imshow("frame", frame) cv2.imshow("Thresh", thresh) cv2.imshow("Delta", frameDelta) key = cv2.waitKey(1) & 0xFF if key == ord("q"): breakvs.release()cv2.destroyAllWindows()
当检测到外轮廓后,遍历外轮廓,这里小于500的小型轮廓,我们忽略不计,然后画出图片box并实时同步到视频中,我们也同步查看一下计算过程中frameDelta与thresh的图像
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)cv2.putText(frame, "Status: {}".format(text), (10, 20),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)cv2.putText(frame, datetime.datetime.now().strftime("%A %d %B %Y %I:%M:%S%p"),(10, frame.shape[0] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 255), 1)cv2.imshow("frame", frame)
以上代码的具体含义,小编这里不再一一介绍,主要功能是画出box,添加文字,并显示图片
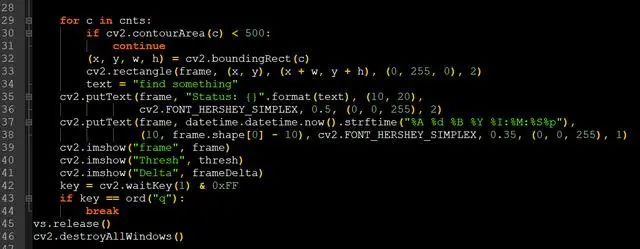
最后我们打开摄像头,看看实际运行的效果(我们的小编终于露脸了),从视频中可以看出,目标能够很好的检测,这里由于其他条件的限制,有个别失误的情况,所以要使用此方法,需要固定背景灯光,背景色,以及好的硬件设施等条件

import numpy as npimport cv2import timecap = cv2.VideoCapture(0)time.sleep(2.0)mog = cv2.createBackgroundSubtractorMOG2()while(1): ret, frame = cap.read() fgmask = mog.apply(frame) cv2.imshow('frame', fgmask) key = cv2.waitKey(1) & 0xFF if key == ord("q"): breakcap.release()cv2.destroyAllWindows()
使用opencv的MOG2背景分割器cv2.createBackgroundSubtractorMOG2()函数来实现背景分割技术
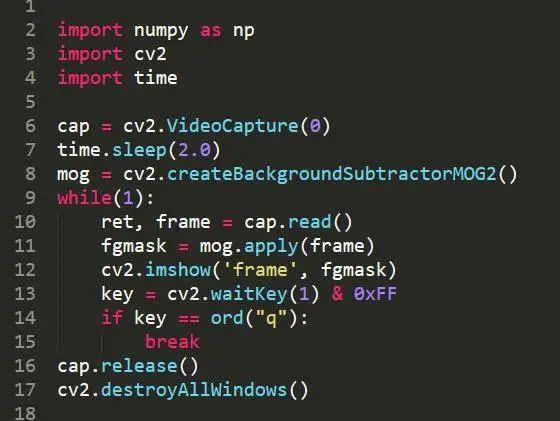
从视频中可以看出opencv的MOG2背景分割器自动优化背景,当某个背景一动不动的时候,默认是背景,当然我们以上的方法也可以实时的与上一帧的视频进行对比,进而实现opencv的MOG2背景分割器的效果
当然opencv 还有KNN分割器目标检测,均值漂移(Meanshift)和CAMShift等众多背景分割技术,小伙伴们可以自行学习
本文转载自网易号【晓萱的娱乐】,更多内容请点击“阅读原文”
以上是关于人工智能神经网络不训练检测模型,如何进行对象的检测与追踪?的主要内容,如果未能解决你的问题,请参考以下文章
keras中的预训练对象检测模型
深度学习架构师?这些图像识别目标检测等技术你需要掌握!
基于YOLOV5深度网络模型的火焰训练
对象检测/分类任务的性能指标(用于图像)
如何向预训练的对象检测模型添加其他类并训练它以检测所有类(预训练 + 新)?
如何增加树莓派的 fps 以进行对象检测