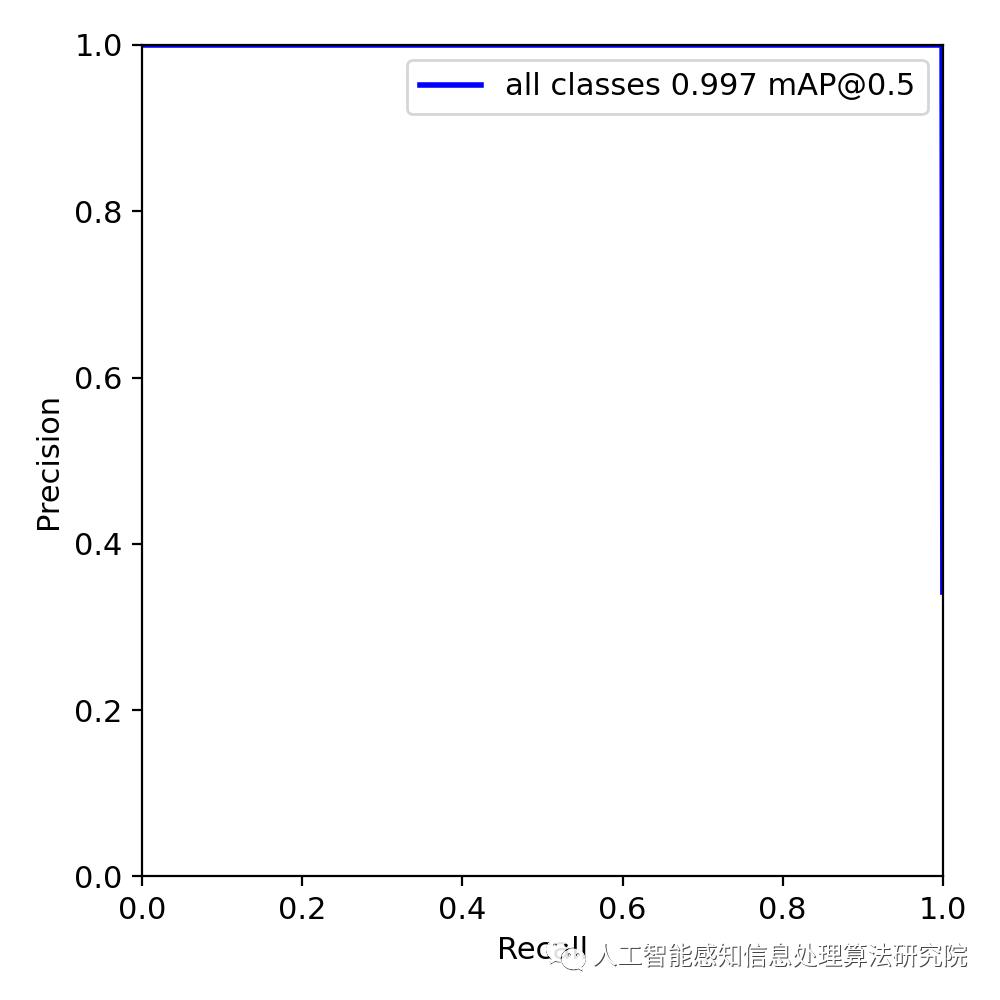
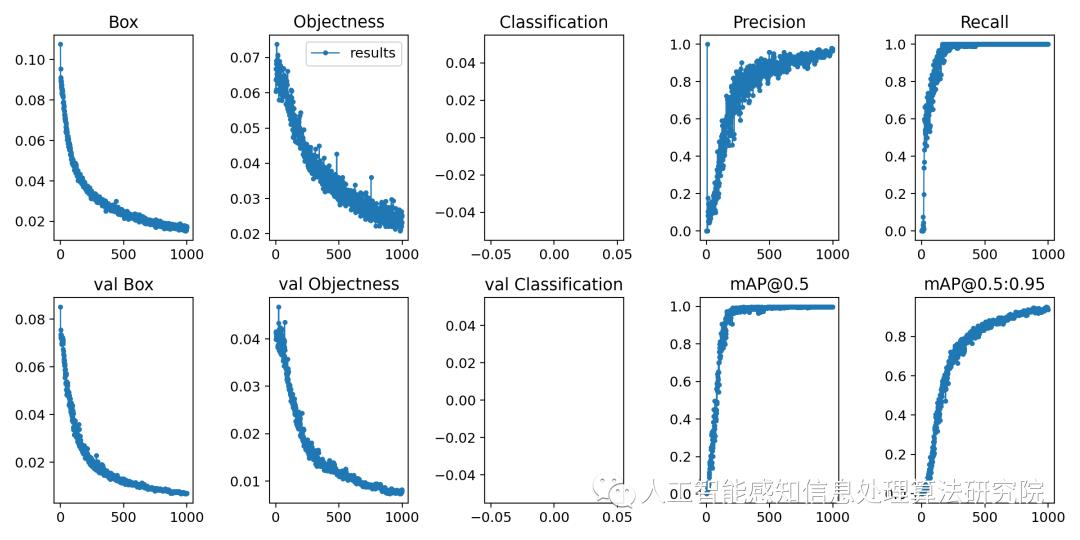
基于YOLOV5深度网络模型的火焰训练 Posted 2021-03-28 人工智能感知信息处理算法研究院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于YOLOV5深度网络模型的火焰训练相关的知识,希望对你有一定的参考价值。
1.背景介绍
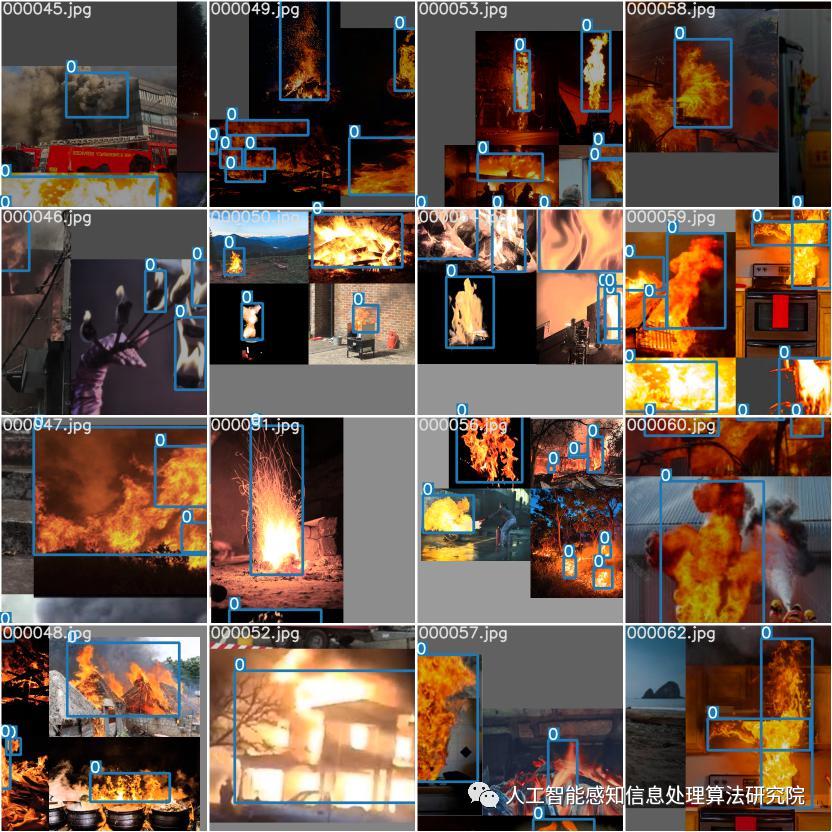
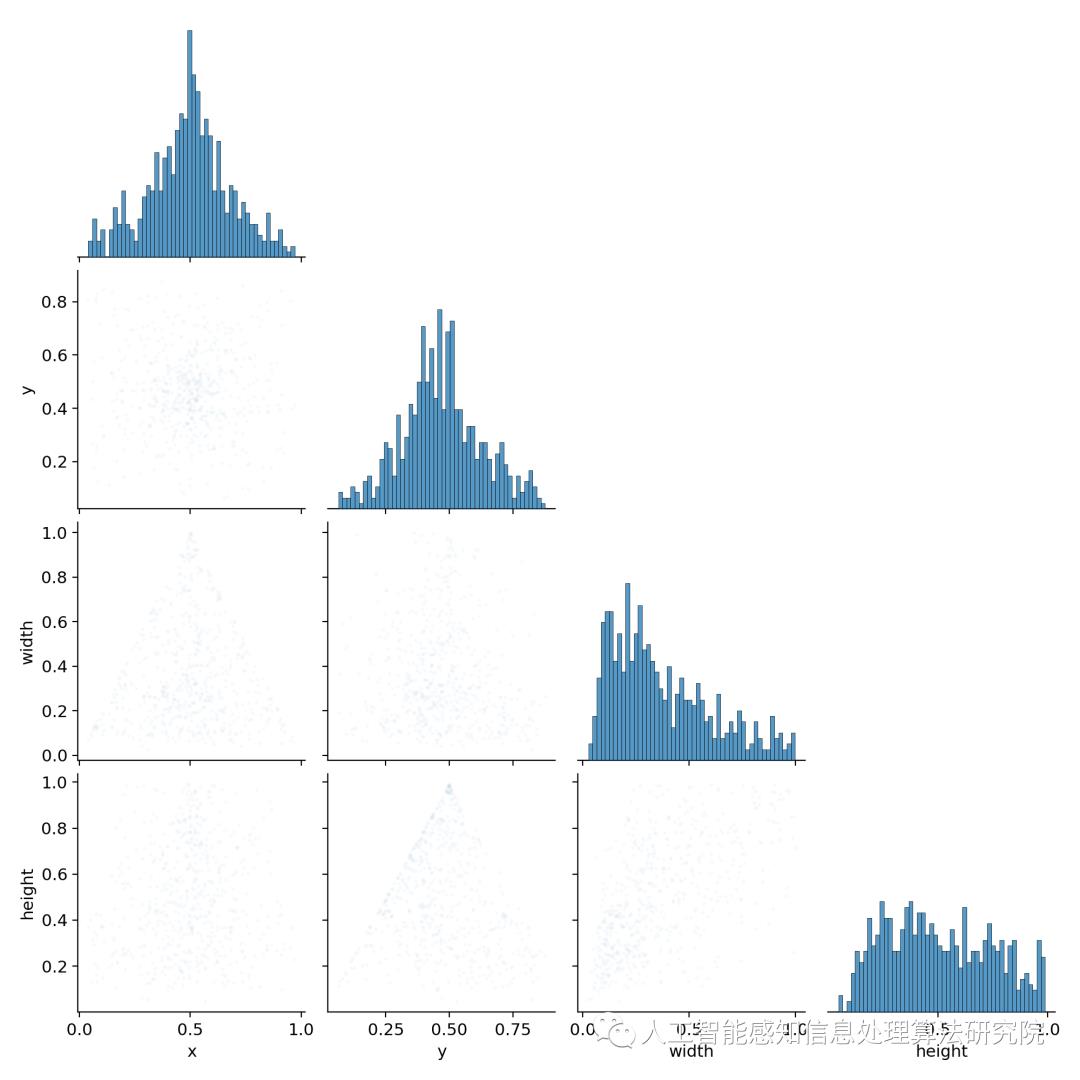
火灾作为一种发生频率较高的多发性灾害,蔓延速度快,破坏性强。随着视频监控的大量普及,基于图像视频的火灾自动检测与预警则十分有研究意义和使用价值。传统火焰检测通常是根据先验知识设计特征提取算法,人工提取火焰动态或静态特征,然后进行火焰识别。此类基于计算机视觉的传统火焰检测方法,其根据先验知识设计人工特征提取算法比较困难和耗时,在面对不同的复杂环境和多变的火焰类型时,其泛化能力往往不足。近年来随着基于深度学习的计算机视觉快速发展,利用卷积神经网络能够自动学习和获取图像特征,目标检测技术有了很大的发展革新。针对复杂环境下的火灾视频检测问题,本文基于YOLO系列的轻量级网络YOLOV5深度网络模型,搜集火焰样本图像,进行检测与识别。
目标检测是一件具有重要现实意义的且有挑战性的计算机视觉任务,其可以看成图像分类与定位的结合,给定一张图片,目标检测系统要能够识别出图片的目标类别并给出其位置,由于图片中目标数量是不确定的,并且要给出目标的精确位置,目标检测相比分类任务更复杂。目标检测广泛应用于无人驾驶、智能视频监控、工业检测、医学图像检测等众多领域,通过计算机视觉替代人力,减少对人力成本的消耗。随着神经网络和深度学习的快速发展和广泛应用,目标检测算法也得到了比较快速的发展,基于深度学习的目标检测逐渐替代传统目标检测而成为主流。
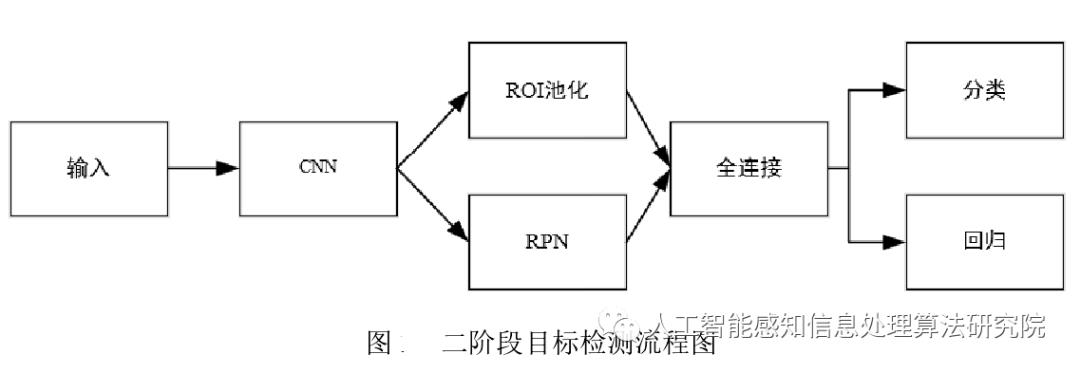
在深度学习时代之前,早期的目标检测流程分为三步:候选框生成、特征提取和区域目标分类,流程如下图所示。
第一阶段候选框生成的目标是搜索图像中可能包含物体的位置,这些位置又叫感兴趣区域(Region of Interesting,ROI)。物体目标可能出现在图像中的任何位置,而且相应的大小尺寸、长宽比例也无法确定,一个直观的思路是用滑动窗口遍历整幅图像。为了捕捉不同尺寸和长宽比物体的信息,输入图像也被重新分割为不同的尺寸和长宽比,然后用不同尺寸的窗口滑动扫描输入图像。
第二阶段,在图像的每一个位置上,利用滑动窗口获取固定长度的特征向量,人工设计特征从而捕捉该区域的判别语义信息。该特征向量通常由低级视觉描述子编码而成,这些描述子包括 SIFT、Haar 、HOG、SURF等,它们对缩放、光线变化和旋转具备一定的鲁棒性。
第三阶段,学习区域分类器,为特定区域分配类别标签。通常使用支持向量机作为分类器,因为它在小规模训练数据上性能优异。此外Bagging、级联学习和 Adaboost等分类技术也会用在此阶段,帮助提高目标检测的准确率。
传统目标检测方法的缺点是比较明显的:候选区域生成阶段的时间复杂度太高,这一阶段产生大量的冗余窗口,严重影响了之后特征提取和目标分类阶段的速度和性能,并且滑动窗口的长宽比一般都是设置固定的几个,对于尺寸波动较大的多类别目标检测,即便是滑动窗口遍历也不能得到很好的候选区域。特征提取阶段的人工设计的特征对于目标特征多样性的变化并没有很好的鲁棒性。
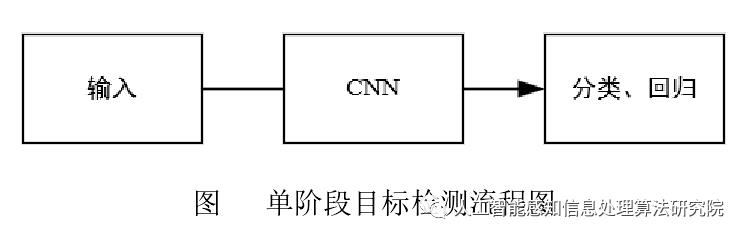
随着卷积神经网络在计算机视觉领域的飞速发展,其已作为图像识别领域的核心技术之一。2014 年Ross B. Girshick使用区域卷积神经网络(Regions with CNN,R-CNN)取代传统目标检测中滑动窗口结合人工设计特征的方式,使得目标检测领域得到了极大的成功和突破,掀起了基于深度学习的目标检测技术的研究热潮。目前基于深度学习的端到端目标检测主要分为两类:基于候选区域的二阶段目标检测器和基于回归的单阶段目标检测器。
二阶段目标检测流程如下图所示。R-CNN是一种具有代表性的两阶段目标检测器,对其网络结构进行修改,衍生出随后的Fast-RCNN和Faster R-CNN模型。两阶段检测器在训练网络时,第一步是训练区域候选网络(RegionProposal Network,RPN)用于生成候选区域,同时将图片划分为背景和目标两种类别,并会对目标位置进行初步的预测;第二步是训练目标区域检测网络用于实现对候选区域内目标类别的判定和目标位置的确定。两阶段目标检测器因其检测精度高而受到更加广泛的使用。但是两阶段目标检测器的网络结构比较复杂,这使得其训练和检测的效率较低,不能很好满足实时检测场景的需要。
单阶段目标检测器的体系结构比两阶段目标检测器更简单,不需要生成候选区域,通过卷积神经网络提取特征直接输出目标的类别、概率和位置坐标,从而实现端到端的目标检测。单阶段目标检测器又包含基于锚框(anchor-based)的和非锚框(anchor-free)的两种方法。SSD、YOLO 和 Retina Net 等都是 anchor-based 的单阶段检测器,它们处理速度快而但精度相对有限。Anchor-based 方法使用密集的锚框直接进行目标分类和回归,能有效提高网络的召回能力,但是冗余框很多。Anchor-free 目标检测器则抛弃锚框的设计,取而代之的使用关键点进行目标检测,诸如Corner Net,Center Net 等,都取得了不俗的效果。
2.3 火灾检测一般流程
YOLOv5 ( You Only Look Once ) 是 由 UltralyticsLLC 公司于 2020 年 5 月份提出,其图像推理速度最快达 0. 007 s,即每秒可处理 140 帧,满足视频图像实时检测需求,同时结构更为小巧,YOLOv5s 版本的权重数据文件为 YOLOv4的 1 /9,大小为 27 MB。
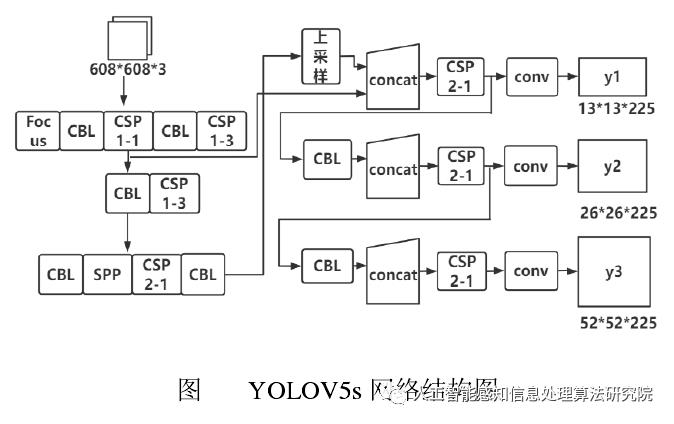
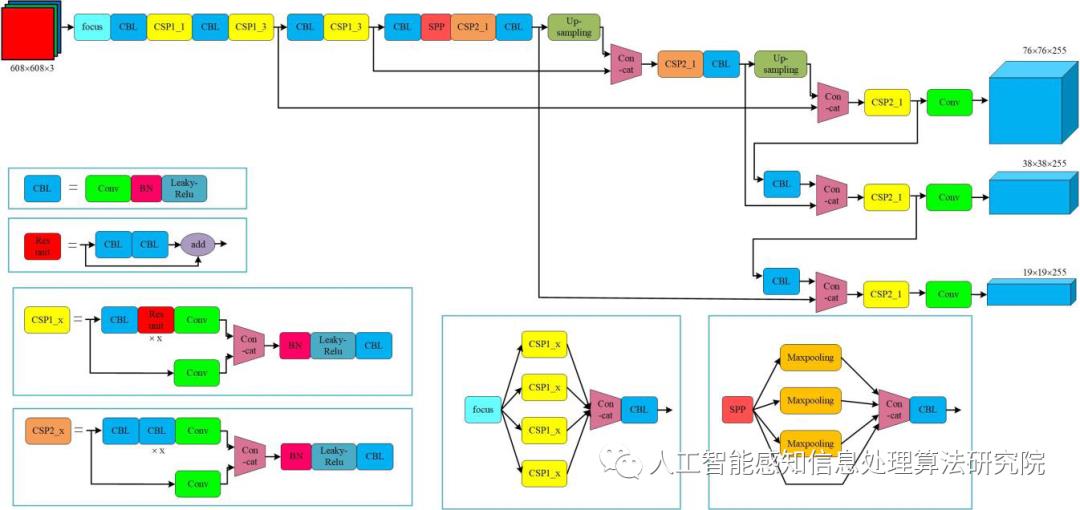
Yolov5 按照网络深度大小和特征图宽度大小分为 Yolov5s、 Yolov5m、Yolov5l、Yolov5,本文采用了 yolov5s 作为使用模型。Yolov5 的结构分为 input,backbone,Neck, 预测层。
(1)在输入端使用了 Mosaic 的数据增强方式,随机调用 4 张图片,随机大小和分布,进行堆叠,丰富了数据,增加了很多小目标,提升小物体的识别能力。可以同时计算 4 张图片,相当于增加了 Mini-batch 大小,减少了GPU 内存的消耗。Yolov5 首先也可以通过聚类设定anchor大小,然后还可以在训练过程中,在每次训练时,计算不同训练集中的ahchor值。然后在预测时使用了自适应图片大小的缩放模式,通过减少黑边,提高了预测速度。
(2) 在 Backbone 上 的 主 要 是 采 用 了Focus 结构,CSPnet 结构。
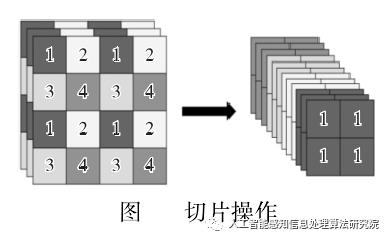
Focus 结构不存在与 YOLOv3和 v4 版本中,其关键步骤为切片操作,如下图 所示。例如将原始图像 416* 416* 3 接入 Focus 结构中,通过切片操作,变为 208* 208* 12 的特征图,接下来进行一次 32 个卷积核操作,变为 208* 208* 32 的特征图。
YOLOv4 目前只在主干网络中采用了 CSP 结构,v5 版中设计 了 2 种 CSP 结 构,CSP1 _ X 和 CSP2 _ X。其中,CSP1 _X 结构主要应用于 Backbone 网络中,CSP2_X 结构主要应用于 Neck 结构中。
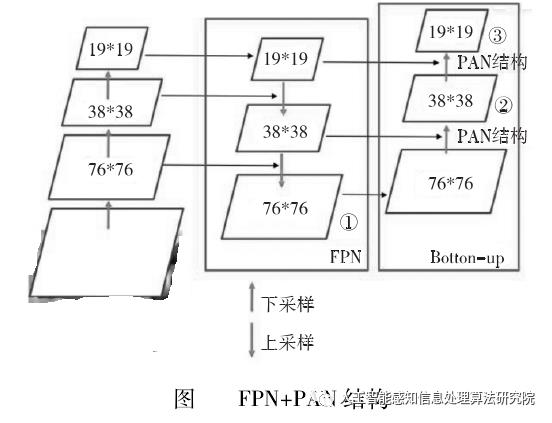
(3)在 Neck 上采用了 FPN 结构和 PAN结构。
FPN 是自上而下的,利用上采样的方式对信息进行传递融合,获得预测的特征图。PAN 采用自底向上的特征金字塔。
Prediction 包括 Bounding box 损失函数和非极大值抑制( NMS) 。YOLOv5 中使用 GIOU_Loss 作为损失函数,有效解决了边界框不重合时问题。在目标检测预测结果处理阶段,针对出现的众多目标框的筛选,采用加权 NMS 操作,获得最优目标框。
官方代码:https://github.com/ultralytics/yolov5
知乎主页:https://www.zhihu.com/people/zhuimeng2080
以上是关于基于YOLOV5深度网络模型的火焰训练的主要内容,如果未能解决你的问题,请参考以下文章
深度学习和目标检测系列教程 16-300:通过全球小麦数据集训练第一个yolov5模型
深度学习目标检测---使用yolov5训练自己的数据集模型(Windows系统)
大数据毕设选题 - 深度学习火焰识别检测系统(python YOLO)
大数据毕设选题 - 深度学习火焰识别检测系统(python YOLO)
大数据毕设选题 - 深度学习火焰识别检测系统(python YOLO)
大数据毕设选题 - 深度学习火焰识别检测系统(python YOLO)