深度学习和目标检测系列教程 16-300:通过全球小麦数据集训练第一个yolov5模型
Posted 刘润森!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习和目标检测系列教程 16-300:通过全球小麦数据集训练第一个yolov5模型相关的知识,希望对你有一定的参考价值。
@Author:Runsen
之前的检测系统重新利用分类器或定位器来执行检测,将模型应用于多个位置和比例的图像。
Yolo 使用了一种完全不同的方法。它将单个神经网络应用于完整图像。该网络将图像划分为多个区域并预测每个区域的边界框和概率。这些边界框由预测概率加权。
YOLO 模型与基于分类器的系统相比有几个优点。它在测试时查看整个图像,因此它的预测是由图像中的全局上下文提供的。比 R-CNN 快 1000 倍以上,比 Fast R-CNN 快 100 倍。
理论部分已经足够了,让我们来看看 YOLOv5 的自定义数据集实现,并了解如何实现到小麦检测挑战中。
该存储库代表 Ultralytics 对未来对象检测方法的开源研究。所有代码和模型均由 Ultralytics 创建。
- https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
!git clone https://github.com/ultralytics/yolov5.git
!mv yolov5/* ./
所有必需的依赖项都保存在 requirements.txt 文件中以安装所有然后运行一次
安装pycocoapi,pip install "git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI"出错,改为GItee
下面脚本将train.csv读取随便分配图片到convertor文件夹中
我们创建一个文件夹转换器,所有文件都以给定的格式存储在该转换器文件夹中。
- converter(main directory)
- val2017
- labels (contains all the box dimensions)
- images (contains images)
- train2017
- labels
- images
- val2017
import os
import pandas as pd
import numpy as np
def convertTrainLabel():
df = pd.read_csv('train.csv')
bboxs = np.stack(df['bbox'].apply(lambda x: np.fromstring(x[1:-1], sep=',')))
for i, column in enumerate(['x', 'y', 'w', 'h']):
df[column] = bboxs[:, i]
df.drop(columns=['bbox'], inplace=True)
df['x_center'] = df['x'] + df['w'] / 2
df['y_center'] = df['y'] + df['h'] / 2
df['classes'] = 0
from tqdm.auto import tqdm
import shutil as sh
df = df[['image_id', 'x', 'y', 'w', 'h', 'x_center', 'y_center', 'classes']]
index = list(set(df.image_id))
source = 'train'
if True:
for fold in [0]:
val_index = index[len(index) * fold // 5:len(index) * (fold + 1) // 5]
for name, mini in tqdm(df.groupby('image_id')):
if name in val_index:
path2save = 'val2017/'
else:
path2save = 'train2017/'
if not os.path.exists('convertor/fold{}/labels/'.format(fold) + path2save):
os.makedirs('convertor/fold{}/labels/'.format(fold) + path2save)
with open('convertor/fold{}/labels/'.format(fold) + path2save + name + ".txt", 'w+') as f:
row = mini[['classes', 'x_center', 'y_center', 'w', 'h']].astype(float).values
row = row / 1024
row = row.astype(str)
for j in range(len(row)):
text = ' '.join(row[j])
f.write(text)
f.write("\\n")
if not os.path.exists('convertor/fold{}/images/{}'.format(fold, path2save)):
os.makedirs('convertor/fold{}/images/{}'.format(fold, path2save))
sh.copy("global-wheat-detection/{}/{}.jpg".format(source, name),
'convertor/fold{}/images/{}/{}.jpg'.format(fold, path2save, name))
convertTrainLabel()
训练脚本
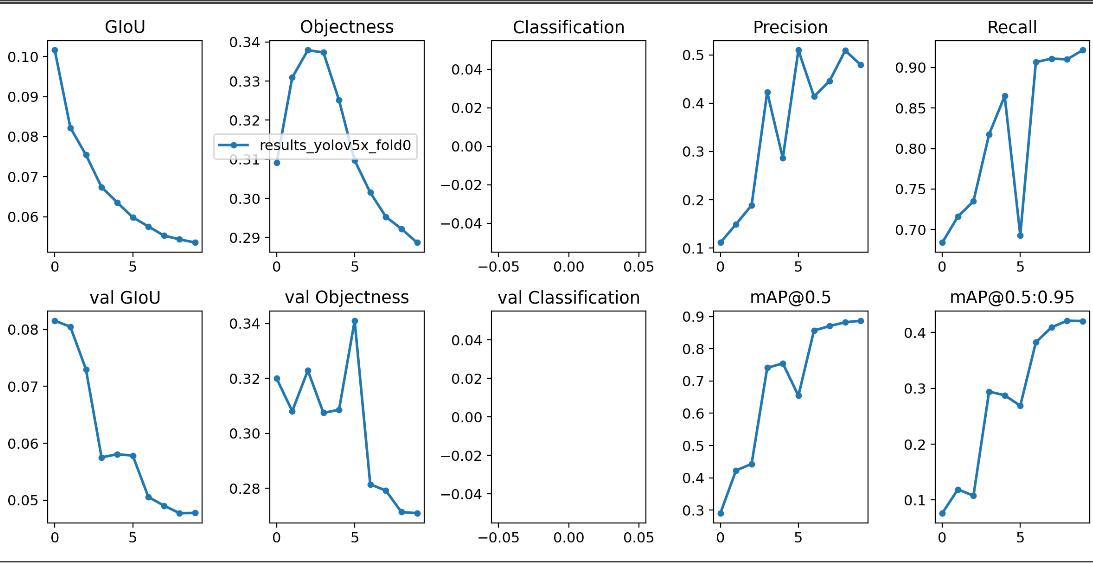
python train.py --img 512 --batch 4 --epochs 10 --data data/wheet0.yaml --cfg data/yolov5x.yaml --name yolov5x_fold0
测试脚本
python ./detect.py --weights ./weights/last_yolov5x_fold0.pt --img 512 --conf 0.4 --source ./convertor/fold0/images/val2017


链接:https://pan.baidu.com/s/1cApWw5uPVLZk0kFIGrzVVA
提取码:e39k
以上是关于深度学习和目标检测系列教程 16-300:通过全球小麦数据集训练第一个yolov5模型的主要内容,如果未能解决你的问题,请参考以下文章