RPI模型与人工神经网络耦合在ANSYS-FLUENT代码下模拟核沸腾*
Posted 安工engineer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RPI模型与人工神经网络耦合在ANSYS-FLUENT代码下模拟核沸腾*相关的知识,希望对你有一定的参考价值。
Simulation of nucleate boiling under ANSYS-FLUENT code by using RPI model coupling with artificial neural networks∗
RPI模型与人工神经网络耦合在ANSYS-FLUENT代码下模拟核沸腾*(一)
摘要:本研究旨在使用人工神经网络开发一种新的用户定义功能,旨在进行计算流体动力学(CFD)仿真,以预测通过核反应堆燃料组件的水蒸气多相流。确实,提供准确的材料数据,尤其是在更宽的温度和压力范围内为水和蒸汽提供的准确材料数据,是在核工程热力学中进行CFD模拟的基本要求。与商用CFD求解器ANSYS-CFX相反,在ANSYS-CFX内部材料数据库中实施了工业标准IAPWS-IF97(国际水和蒸汽工业配方协会1997),而求解器ANSYS-FLUENT仅提供使用状态方程(EOS)的可能性,例如理想气体定律,Redlich-Kwong EOS和分段多项式插值。为此,在CFD求解器ANSYS-FLUENT中,采用新方法来实现水和蒸汽对过冷水的热物理特性。该技术基于多层人工神经网络,可准确预测密度,比热,动态粘度,导热系数和饱和液体和饱和蒸气上的声速的10种热力学和传输特性。温度用作单个输入参数,人工神经网络ANN预测的最大绝对误差约为3%。因此,在CFD求解器ANSYSFLUENT下进行的数值研究与该领域中ANSYS-CFX的其他CFD代码具有竞争优势。实际上,Rensselaer理工学院(RPI)壁沸腾模型与已开发的Neural-UDF(用户定义函数)的耦合被发现对预测过冷沸腾流中的蒸汽体积分数很有用。
关键词:用户定义函数(UDF),计算流体动力学,IAPWS-IF97,ANSYS-FLUENT,多层感知器(MLP),伦斯勒理工学院
前言
本研究关注人工神经网络对正在进行的核沸腾研究的支持。重点放在在加压条件下加热壁的圆管中两相流的预处理的数值模拟上。计算流体动力学技术对过冷核沸腾的模拟显示出越来越大的前景。使用商业计算流体动力学(CFD)求解器ANSYS-FLUENT作为计算平台,并使用Eulerian方法与RPI沸腾模型相结合,其中各相假定为互穿连续体。该模型是所有多相流模型中最通用,最复杂的模型。ANSYS-FLUENT的优势在于可以适应特殊情况的湍流模型数量。另一方面,CFX是涡轮机械的通用代码。
通过基于加热管中空隙分布的实验数据进行详细的CFD分析,可以为在压水堆(PWR)条件下改进的沸腾沸腾模型做出贡献。当加热的表面超过周围冷却液的饱和温度时,表面上可能会沸腾。形成在受热表面上的气泡离开表面并被散装流体输送,因此据说存在两相流的条件。取决于过冷程度和加热管的长度,气泡在离开管子之前可能会凝结或不会凝结并坍塌。在过冷沸腾中,该过程导致流体进一步加热至饱和温度。在饱和沸腾或本体沸腾中,气泡可以沿加热管的整个长度传输而不塌陷。
在求解器ANSYS-FLUENT版本14.5.0中实施的伦斯勒理工学院(RPI)壁沸腾模型或热分配模型中,从加热壁到两相流的总热通量包括对流,淬火和蒸发热通量。此外,热通量分配模型将每个热通量贡献与无量纲的壁面积比率相关联,以定义热通量贡献之间的比率。重要的方面是对热传递过程中流体行为的了解和理解。水和蒸汽的热物理性质被指示为控制该过程的基本性质。
有几种方法可以专注于热力学和传输性质:通过不同的状态方程式以及通过许多近似函数。在1990年代初期,核设施安全分析规范的出现促进了对精度的探索,并扩大了水和蒸汽性质的范围。然后,IAPWS的新标准利用了数据和技术进步,开发了新的热力学性质。
人工神经网络已被广泛用于预测上述10个热力学和传输性质。人工神经网络(ANN)是一种高级数学工具,可根据可用的实验信息确定网络输出。它还暗示了任何线性和非线性系统的数学函数逼近。
吉布斯相位规则允许确定系统的自由度或方差数。这对于解释相图很有用。
其中F是自由度的数量,C是化学成分的数量,p是系统中的相数。之所以指定第二个数字,是因为该公式假定p和T均可变化[6]。根据等式(1)在两相区域中,对应于(PT)图中的饱和度曲线,水和蒸汽的热力学性质取决于单个状态变量,在我们的情况下为温度。预测范围在从273.15 K到临界温度Tc的整个气液饱和线内有效,即273.150 K≤T≤647.096 K。
通过使用实验数据库提供一系列输入数据和目标输出值来进行神经网络的训练,其中包括整个有效范围,其中温度是单个输入参数。
2.人工神经网络方法
神经网络作为黑匣子模型运行,不需要有关系统的详细信息。这是受生物神经元系统启发的高级数学建模程序。ANN方法似乎完全适用于变量之间的关系不是线性和复杂的问题。在多层结构中(图1),神经元被分组为一层,一层输入神经元,一层输出神经元和一个或多个由许多相互连接的神经元组成的隐藏层。
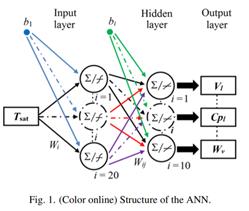
值的规范化是ANN中至关重要的一步。ANN的输入值可能相差几个数量级,这可能无法反映确定出口热物理和传输特性的输入的相对重要性。为此,使用等式给出的mapminmax算法在[-1,1]范围内将输入数据归一化。(2)标准化每行的最大值和最小值。针对输出变量,通过对数函数进行归一化。
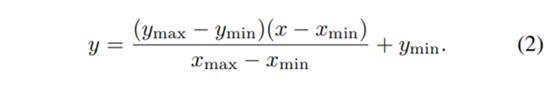
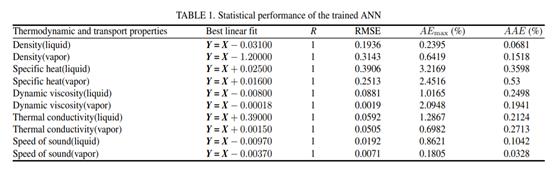
在研究了许多不同结构的神经网络后,本文选择的适当的人工神经网络具有一个包含20个神经元的隐藏层和一个包含10个神经元的输出层。隐藏层具有tansig传递功能。输出层具有purelin传递函数。ANN的典型结构如图1所示。输入是单个输入变量(T:温度),而饱和时的密度,比热,动态粘度,导热系数和声速的10个热力学和输运特性。液体和饱和蒸汽被视为输出变量。
每个神经元求和从神经元(j)到神经元(k)和输入(xj)的每个连接权重(wjk)的乘积,以及称为权重的额外权重,以获取神经元的总和值。第i个神经元有一个求和器,它收集其加权输入wij·xj和偏置bi以形成其净输入Pi。
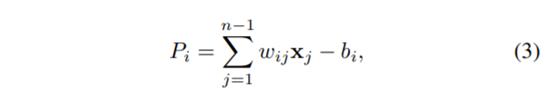
其中wij表示从第j个输入到第i个神经元的连接强度,xj是输入向量;bi是第i个神经元偏差。激活函数F(Pi),S形函数用于在给定神经元输入集的情况下计算神经元输出。为了为每个神经元找到合适的ws和偏见,过程训练必不可少。这是构建人工神经网络的第一步。训练是指对权重进行校正以产生预先指定的(“正确的”,从实验中得知)目标值,并且训练需要成对的集合(XS,YS)进行输入:网络中的实际输入是向量(XS),成功训练后,相应的目标标为(YS)。当从训练集中获得XS的每个向量的YS正确值时,希望网络会根据ANN模型的基本原理并使用更多数据进行训练,从而对X的任何新对象给出正确的Y预测。网络,将获得更好的结果。多层神经网络最常用的训练方法称为反向传播,其中应用Levenberg-Marquardt(LM),就速度和内存使用而言,该方法被认为是最有效的算法。
ANN中使用的观测数据数量为377,分为三个部分:训练集(275个数据),测试集(53个数据)和验证集(49个数据)。通过选择72%的数据集作为训练,14%的数据集作为测试和14%的数据集作为验证子集,可以获取ANN的训练,测试和验证子集。
观测值和预测值之间的差异将通过系统过滤回去,并用于调整各层之间的连接,从而提高了性能。均方根误差系数(RMSE)是评估ANN性能的主要标准,其定义如下:
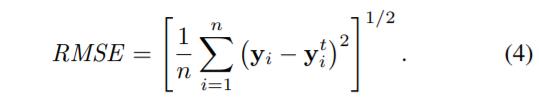
使用平方相关系数R,绝对误差AE和平均绝对误差AAE评估训练,测试和验证集的ANN的统计质量
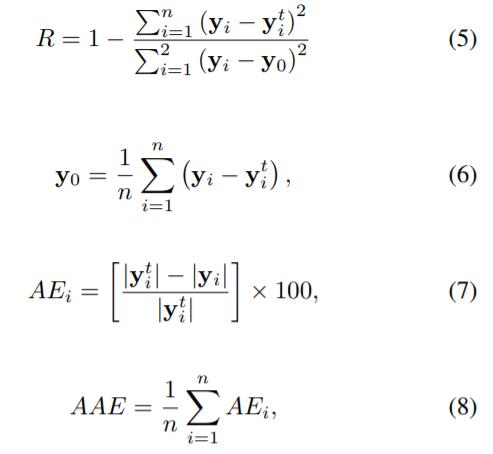
其中yi表示第i个训练,测试或验证输出值,而y t i是相应的目标值,其中n是输入向量的数量。结果总结在表1中
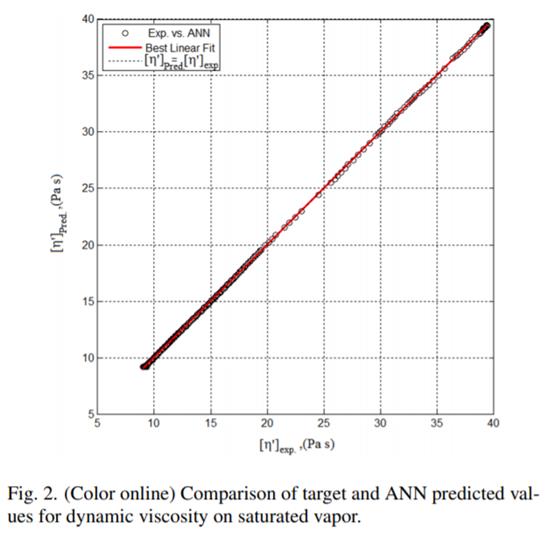
图2所示的观测和预测(以饱和蒸汽为例的动态粘度)的突破曲线表明,人工神经网络很好地描述了实验数据。
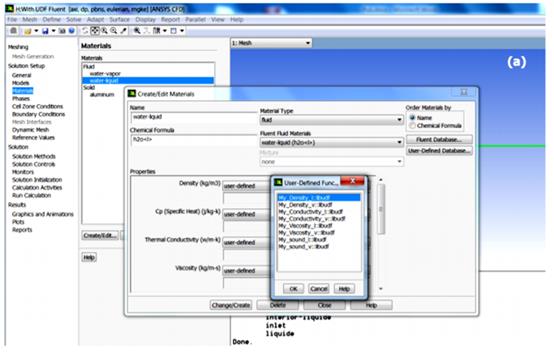
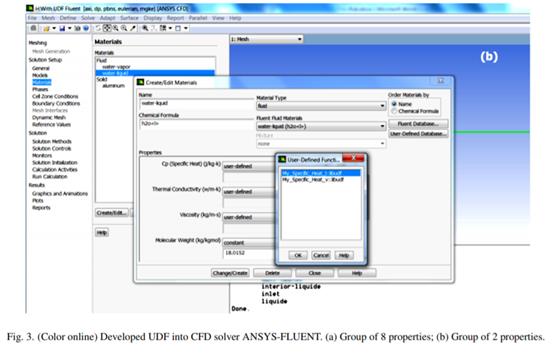
从建模性能来看,从属于水和蒸汽所有属性的人工神经网络获得的通用模型在UDF中实现,该UDF编译并挂接到求解器ANSYS-FLUENT中。图3显示了将UDF合并到求解器中的情况:一组8个属性(密度,动态粘度,导热率和饱和液体和饱和蒸汽的声速)和一组2个属性(比热在饱和液体和饱和蒸汽中的比热)。用C++编写的UDF是一个例程,可以与求解器FLUENT动态链接并由我们进行编程
3. CFD计算
A benchmark case
由Bartolemei和Chanturiya进行实验研究的拟议基准试验是使过冷水通过Φ15.4m×2的垂直加热管向上流动。
如图4所示,工作压力为4.5MPa。过冷度为58.2 K的过冷水从底侧进入,并向上穿过管子。均匀地施加在管表面上的热通量为0.57 MW/ m2。入口质量通量为900 kg /(m2 s)。可用的实验数据包括沿管壁和轴的温度,总体液体温度以及沿管的横截面平均蒸气体积分数。壁沸腾处于核沸腾状态
如表2中所示,进行了参数研究以研究开发的UDF的效果
B wall boiling model
在加热管中的有核过冷沸腾中,壁热部分用于形成气泡,其余部分转移到液体中。从成核位置附近的壁传热发生在两个不同的时期:气泡生长时间和等待时间。
C UDF-RPI model validation
由于问题公式是轴对称的,因此模拟的区域仅为宽度等于管半径的2D切片。代码手册建议对欧拉多相模型使用四边形计算网格,经过多次尝试找到最佳计算网格之后,我们采用了具有80个均匀径向元素和1000个均匀轴向元素的网格。接触区域(靠近加热壁)的网孔密度更高,以提供更好的局部流量参数分布并实现稳定的解决方案。
为确保入口处的速度量级和湍流量的曲线完全发达,将为没有沸腾(单相)的模拟流场生成的这些量的出口轮廓将用作沸腾(多相)模拟的入口信息。
通过Eulerian-RPI方法,可以在FLUENT中对多个分离但相互作用的相进行建模,以预测局部流动参数的分布,蒸气体积分数,气泡直径和液体温度。湍流现象通过经典的ReNormalization Group(RNG)k-ε模型与近壁处理的增强壁处理相结合来描述。 y + = 5的值被认为对于所选的增强墙面处理方法是合理的。有关输入参数的更详细列表,请参见表3,有关基准案例中使用的沸腾模型的相关性,请参见表4
在选定压力下的饱和温度为530.55 K,假定过冷沸腾模型水的性质随温度而变化。从技术上讲,它是我们开发的UDF的一部分。这就是这项工作的目的。
控制方程是非线性的,并且在获得收敛解之前必须执行几次循环迭代。对于数值精度,一阶迎风方案用于控制方程组的空间离散化。由于采用的数字方案与体积分数结合在一起,因此可以使用10的低库仑数来实现更快的收敛。
参考文献:https://www.sciencedirect.com/science/article/pii/S1359431117318859#t0005
以上是关于RPI模型与人工神经网络耦合在ANSYS-FLUENT代码下模拟核沸腾*的主要内容,如果未能解决你的问题,请参考以下文章