人工智能选股系列——支持向量机(SVM)模型
Posted 万矿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能选股系列——支持向量机(SVM)模型相关的知识,希望对你有一定的参考价值。
Wind 旗下高端量化云平台
支持向量机(SVM)是应用最广泛的机器学习方法之一。线性支持向量机能够解决线性分类问题,核支持向量机则主要针对非线性分类问题,支持向量回归能够处理回归问题。我们将对包括线性核、多项式核、高斯核和 Sigmoid 核在内的各种核函数支持向量机以及支持向量回归进行系统性的测试,并分析它们应用于多因子选股的异同,希望对本领域的投资者产生有实用意义的参考价值。
本文参考:华泰证券《人工智能选股之支持向量机模型》
WQ
支持向量机(SVM)介绍
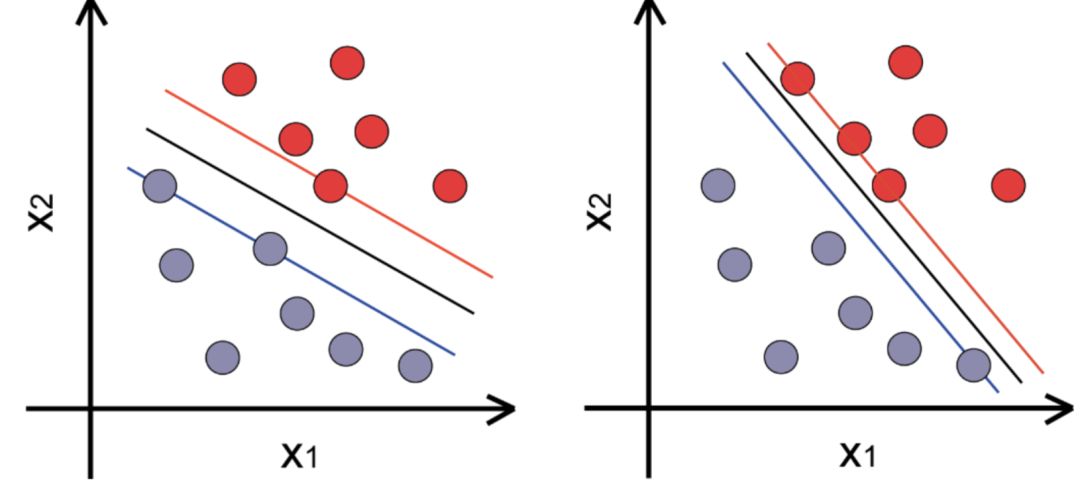
支持向量机(Support Vector Machine,SVM)是应用最广泛的机器学习方法之一。在20世纪90 年代,传统神经网络式微,深度学习尚未兴起,支持向量机由于其极高的预测正确率,并且能够解决非线性分类问题,成为当时最流行的机器学习方法。支持向量机可分为线性支持向量机和核支持向量机,前者针对线性分类问题,后者属于非线性分类器。相对于传统的分类器,神经网络,决策树,贝叶斯分类方法,支持向量机在于它提出了间隔最大化的思想,使得其在预测分类上有着更好的效果,对比的传统的分类器算法往往只要只要在迭代过程中找到解就停止运算。
另外一个就是在处理非线性可分的数据集采用核函数的方法将数据映射到高维空间,在本身不增加数据的维度的情况下避免了样本空间的稀疏,从而一定程度避免了维灾难。
WQ
数据指标的获取以及预处理
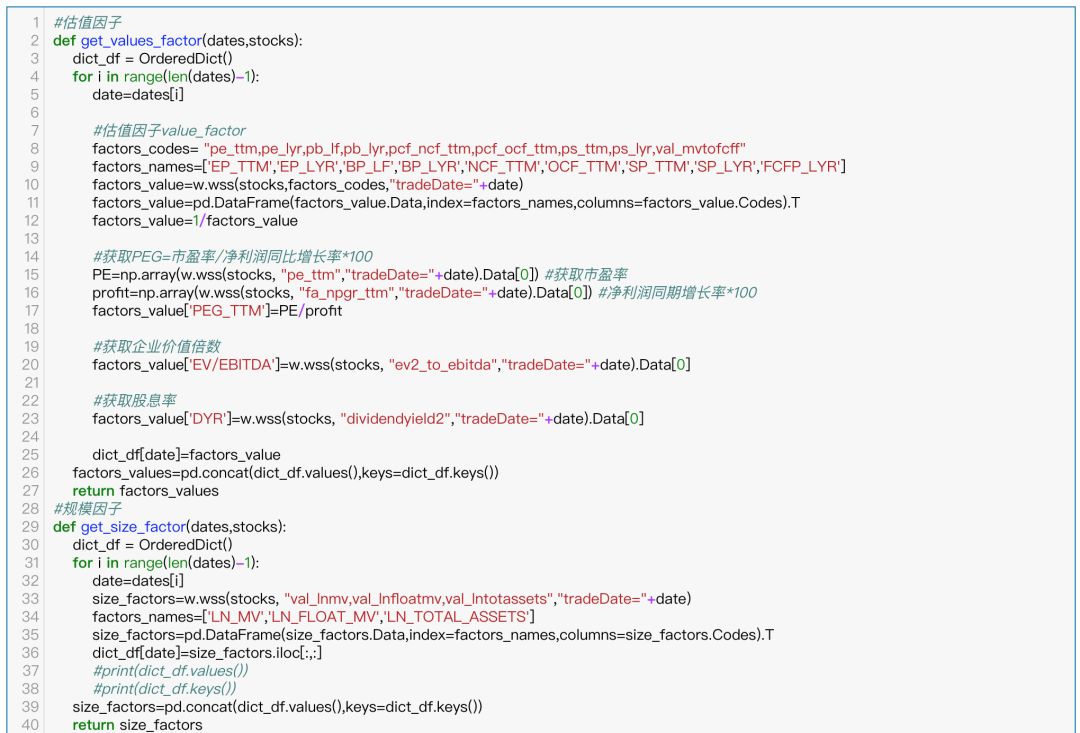
在这个部分,首先参考之前社区分享的建立市场因子库系列的代码,以及研报使用的相关因子,其中包括估值因子,规模因子,杠杆因子,技术因子,动量因子,以及成长因子。
首先采用2018年8月1号的沪深300为选股的股票池,然后选用数据的时间为2015年1月1日至2016年6月30日的数据来建立模型,在这之前,必须去掉2015年之前未上市的股票,筛选过后共有270只股票。
部分代码展示(完整查看文末)
数据预处理
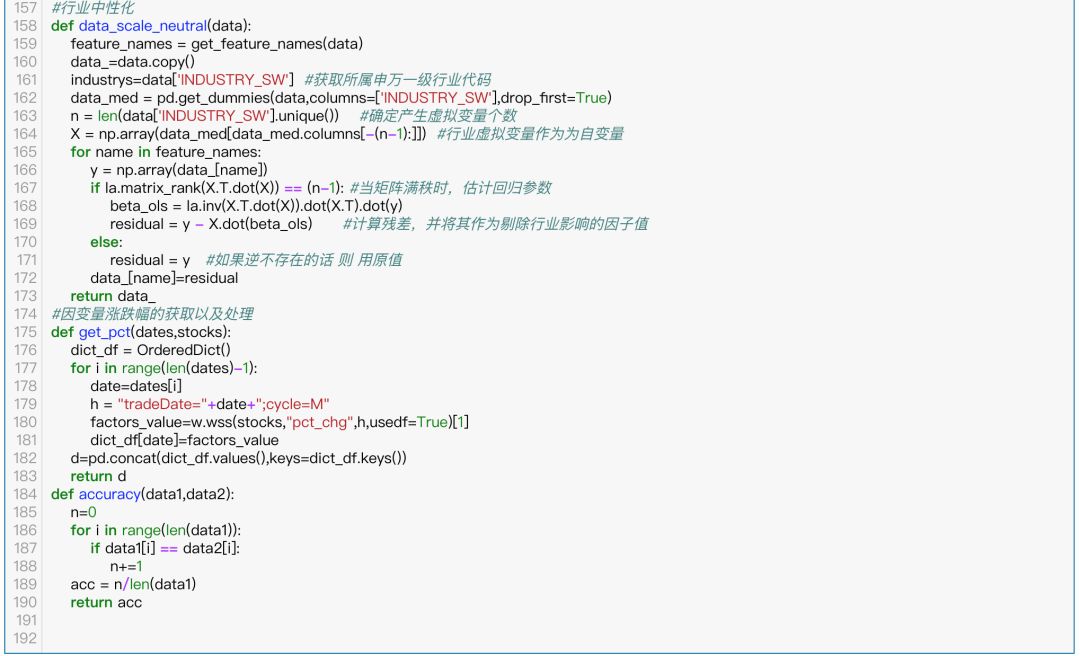
先中位数去均值法处理异常值(使用的是5倍标准差),然后看缺失值情况,直接删去或用均值替代,最后做市场中性化处理以及标准化。
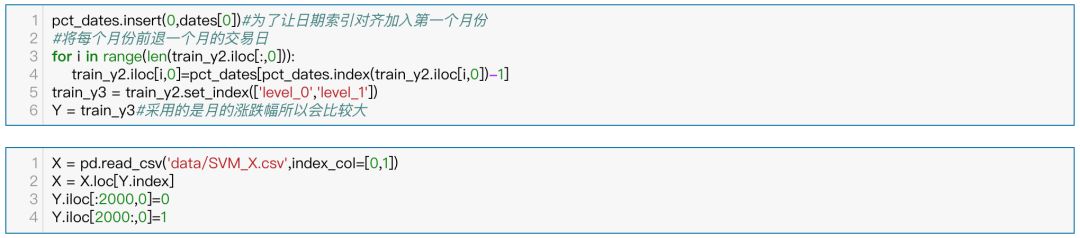
获取因变量涨跌幅,由于是因变量未下个月相对于上个月的涨跌幅,所以得滞后一个月。去除缺失后将其进行排序:

接下来将涨跌幅最高的两千个样本分为一类,以及涨跌幅最低的两千个样本分为一类:

WQ
训练集和测试集的划分
这部分按照研报的做法,选择收益率排名接近前约为40%的股票分为一类和收益率排名为后约为40%的股票分为一类。标签记为1和0,并将这部分作为训练集。因变量为收益率,即股票的月涨跌幅,在这里因为预测的是之后下个月的收益率,所以获取的月份数必须滞后一期,之后为与之前的因子数据对齐再向前前退一期。
WQ
SVM模型构建、交叉验证参数选择
在我们建立的模型中,除了通过迭代训练得到的参数外,还有一些参数是需要人为设定的,既然如此,那么多少就带了很大的主观性,为避免这种主观性,能通过交叉验证的方法来选择最优参数。在这里按照研报的做法,只考虑罚项C和系数gamma,在支持向量机模型中最常用的就是核函数的选择以及最常用的就是高斯核和线性核和多项式核,如果是高斯核那么还涉及参数gamma的设定,除此外模型为防止过拟合还需要人为设定参数C, 交叉验证的方法采用GridSearchCV,即每次对每一个核函数的两个参数进行组合进行遍历的方式,按照判断标准来选择最优参数,这里采用的准确率。参数的选择范围以及评判标准参考了研报的做法。
k-折交叉验证介绍
k-折交叉验证将样本集随机划分为k份,k-1份作为训练集,1份作为验证集,依次轮换训练集和验证集k次,验证误差最小的模型为所求模型。具体方法如下:
1、随机将样本集S划分成k个不相交的子集,每个子集中样本数量为m/k个,这些子集分别记作
S1,...Sk
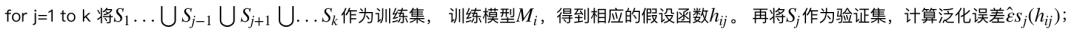
3、计算每个模型的平均泛化误差,选择泛化误差最小的模型Mi 。
K-折交叉验证方法,每次留作验证的为总样本量的1/k(通常取k=10),因此每次用于训练的样本量相应增加了,然而K-折交叉验证对于每个模型都需要运行k次,他的计算成本还是较高的。
sklearn GridSearchCV
在sklearn中,通过每两个参数构建一个组合进行遍历搜索,类似在一个三维平面上,在评选准则的坐标轴上上选择在该轴上最高的另外两个坐标轴形成的网格的参数组合。如下图所示,得到的x,y就是交叉验证的最优参数。
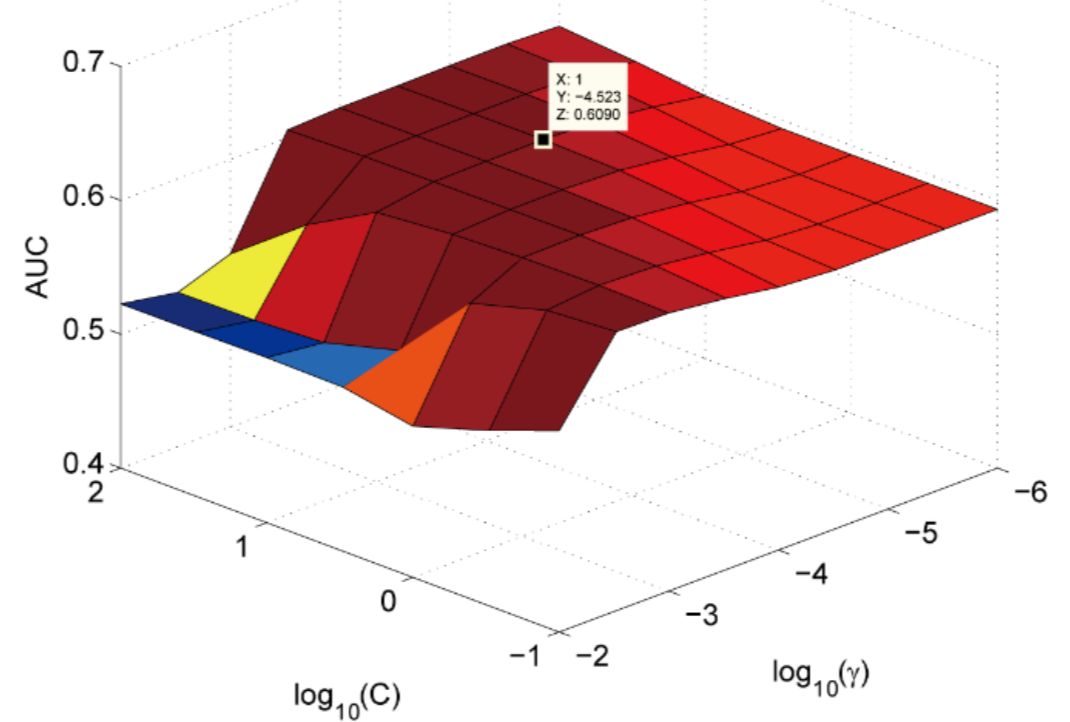
在接下来的调参过程中,我的调参范围参考了研报的参数范围的选取:
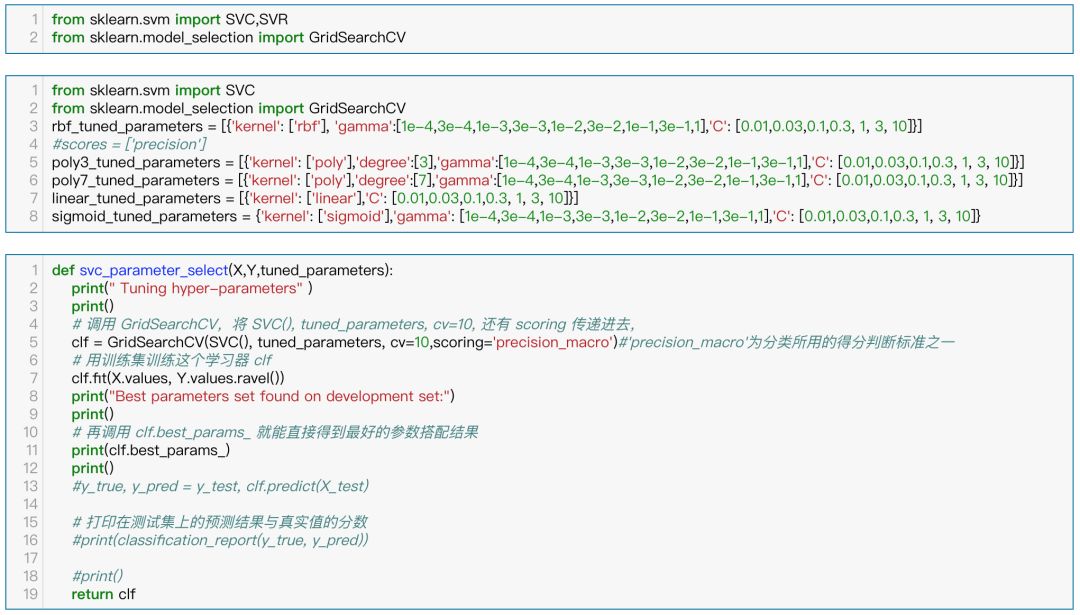
SVC部分¶

从运行结果我们可以看出svm模型中选择3阶的多项式核时惩项为0.01,gamma为0.3时最好,7阶多项式时罚项为0.1,gamma为0.1最好,线性核罚项为3最佳,sigmoid核罚项为10,gamma为0.001最好,选择高斯核函数时最优参数的gamma取值为0.03, 惩项C为3最好
WQ
不同核函数SVM 模型的拟合结果
我们根据返回的参数重新建立模型,其实如果GridSearchCV能够返回一个交叉验证后最优参数拟合得到模型是最好的。
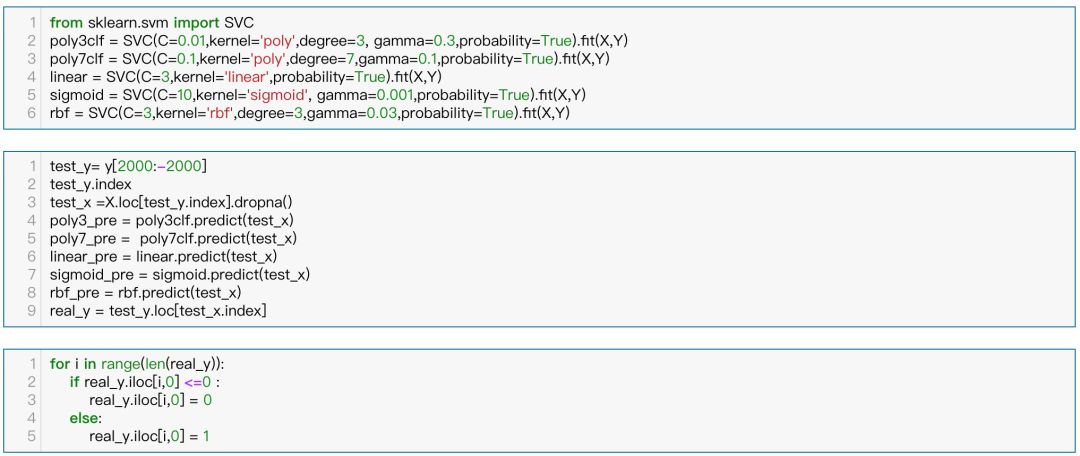
在预测准确率上我并没有得到像研报上相同。
由于划分的依据带有一定的主观性,于是我尝试在-1到1之间一百等分,尝试多个分界点进行划分看看分类结果。

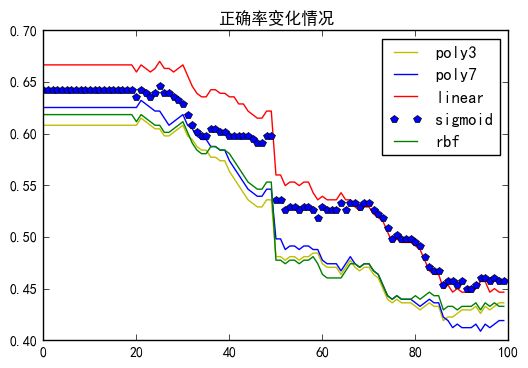
从上面我们可以看出在测试集上随着分界线的正向移动,分类的正确率会逐渐下降。
分类模型中各模型的的AUC值
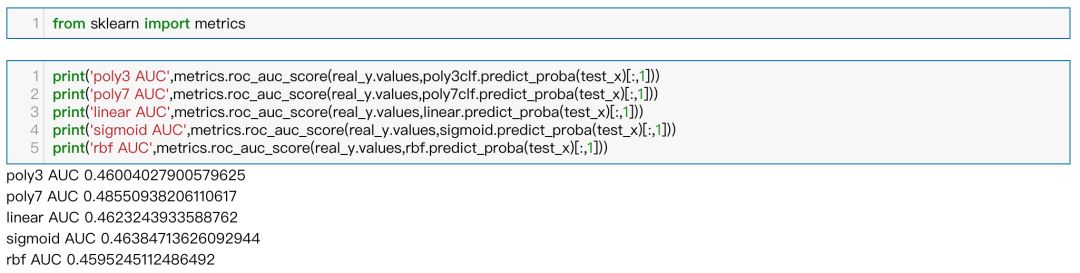
WQ
模型回测情况及其分析
接下来选择选用2018年7月1日至2018年6月30日的月数据进行预测:
部分代码展示(完整查看文末)

在得到各模型的预测结果,根据判断上涨的概率,选择上涨概率最高的一定数量的股票进行购买。

这里我们首先构建我们的调仓策略,与研报采用将涨跌值与因子求相关系数不同,我的策略是按月调仓一次,每月第一天卖出当前持有股票,然后根据预测结果在当天选择我们要购买的股票,购买的比例为为属于类别一概率最高的前十支股票,各股票购买的权重为各自概率的加权平均。
接下来运行各种核函数支持向量模型调参后的预测结果:
3阶多项式核支持向量机
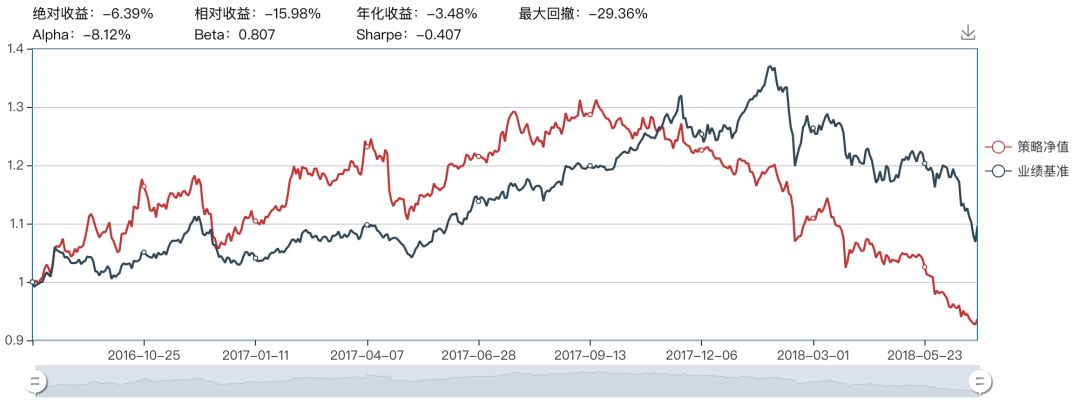
从上面3阶多项式核表现得较差。
7阶多项式核支持向量机
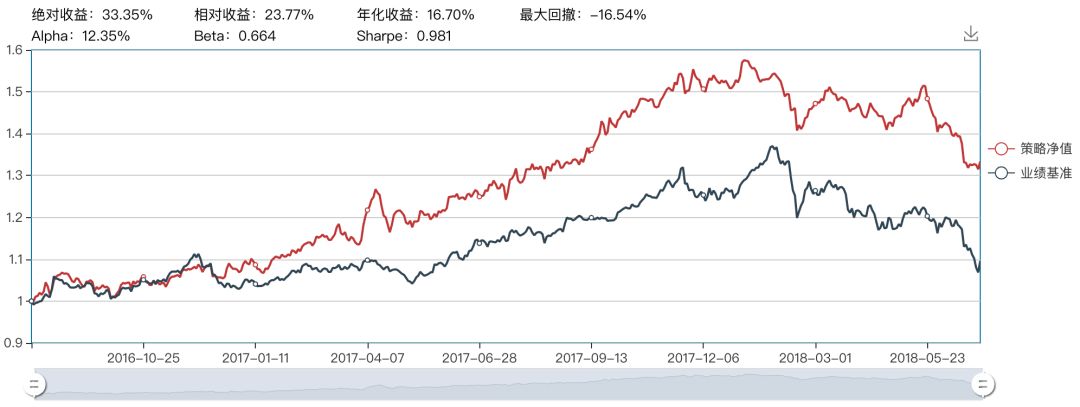
7阶多项式的核支持向量机相对比3阶的收益和回撤都好很多。
线性核支持向量机
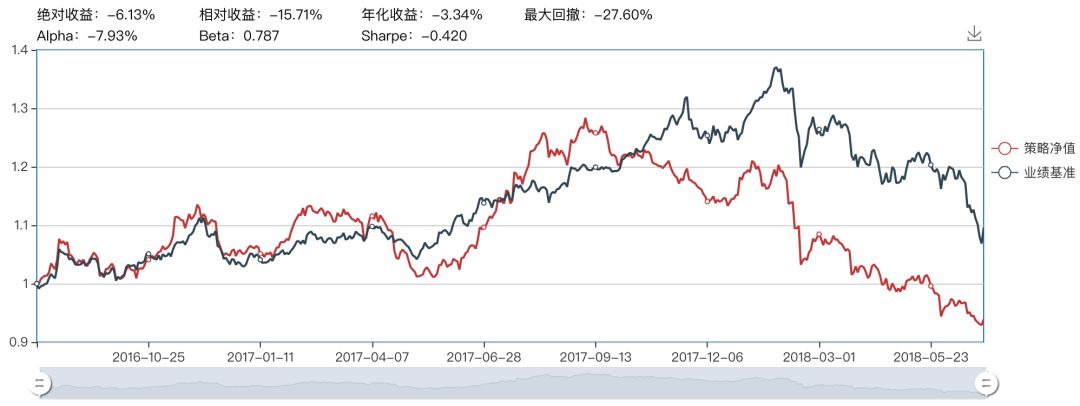
线性核在训练集的预测正确率是最高的,但是实际在测试集上表现最差,可能存在过拟合的现象导致泛化性能很差。
sigmoid支持向量机
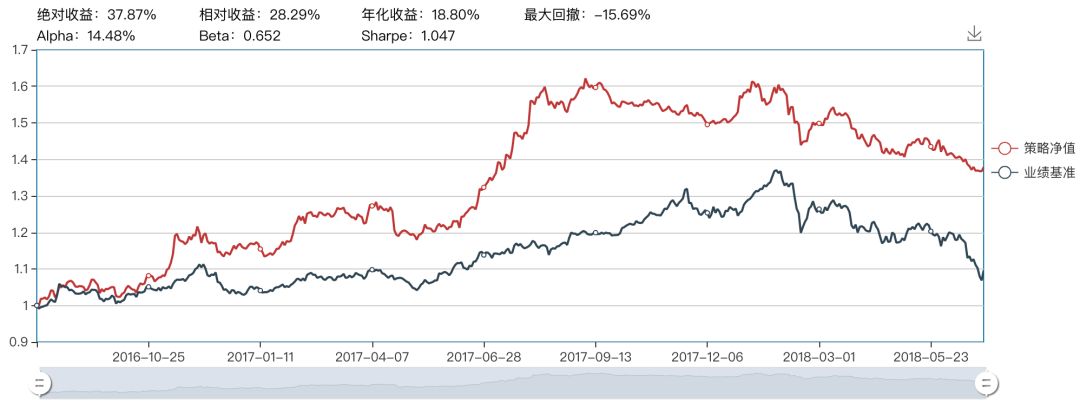
sigmoid核的回撤相对较大,但在2017年四月至七月存在明显的爬升。
高斯核支持向量机
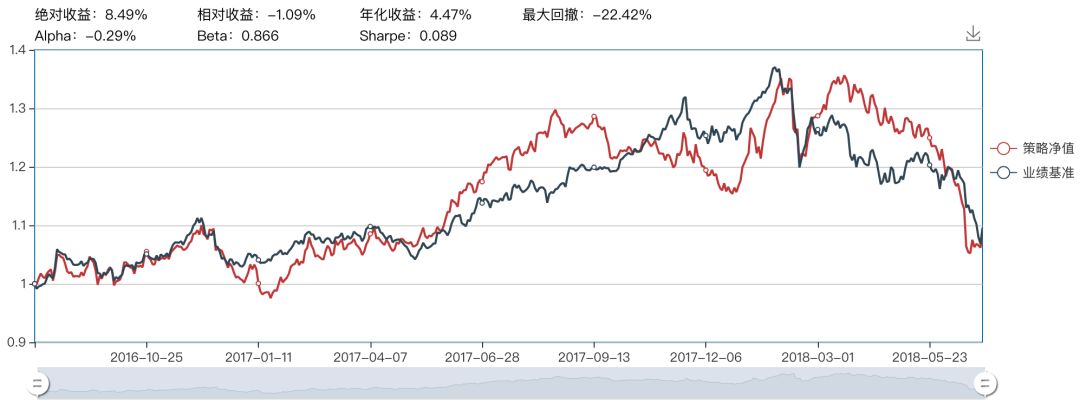
部分代码展示(完整查看文末)

WQ
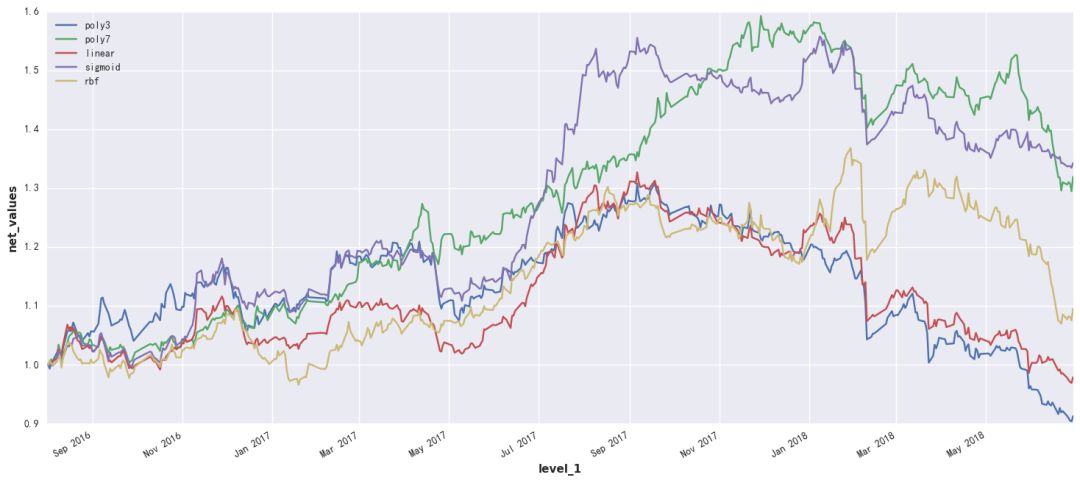
总结
从结果上看,多项式核的支持向量机效果是最好的,其次是sigmoid、rbf,最后线性核是最差的。
扫码查看源代码

WQ
万矿量化金融分析师计划
——End——
有Wind账号的朋友登录Wind金融终端
点击量化或输入WQT即可使用万矿
个人用户也可登录网页版免费注册使用
iWind群:463249
以上是关于人工智能选股系列——支持向量机(SVM)模型的主要内容,如果未能解决你的问题,请参考以下文章