人工智能(30)–支持向量机
Posted 科技优化生活
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能(30)–支持向量机相关的知识,希望对你有一定的参考价值。
人工智能之支持向量机(SVM)
人工智能之机器学习有5大流派: 1) 符号主义,2) 贝叶斯派,3) 联结主义,4) 进化主义,5) Analogizer。今天我们重点探讨一下Analogizer中最擅长算法-支持向量机(SVM) ^_^
SVM概述:
支持向量机(SVM)是由Vapnik领导的AT&T Bell实验室研究小组在1995年提出的一种新的非常有潜力的分类技术。刚开始主要针对二值分类问题而提出,成功地应用子解函数回归及一类分类问题,并推广到大量应用中实际存在的多值分类问题中。支持向量机(SVM)是一种与相关学习算法有关的监督学习模型。
支持向量机(SVM)自诞生起便由于它良好的分类性能席卷了机器学习领域,并牢牢压制了神经网络领域好多年。如果不考虑集成学习的算法,不考虑特定的训练数据集,在分类算法中的表现SVM可以说是排第一的。
支持向量机(SVM)在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
SVM原理介绍:
支持向量机(SVM)方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折中,以求获得最好的推广能力。支持向量机(SVM)与神经网络类似,都是学习型的机制,但与神经网络不同的是SVM使用的是数学方法和优化技术。SVM背后的数学理论基础(概率论与数理统计、泛函分析和运筹学等)是近代人类的伟大数学成就。由于数学上比较艰涩,刚开始SVM研究一直没有得到充分的重视。直到统计学习理论SLT的实现和由于神经网络等较新兴的机器学习方法的研究遇到一些重要的困难,才使得SVM迅速发展和完善。
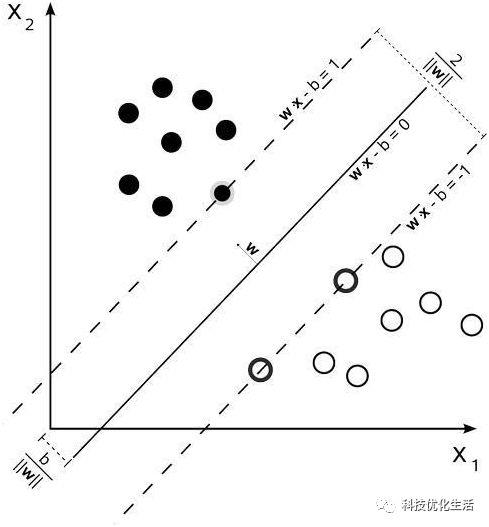
支持向量机(SVM)可以分析数据,识别模式,用于分类和回归分析。给定一组训练样本,每个标记为属于两类,一个SVM训练算法建立了一个模型,分配新的实例为一类或其他类,使其成为非概率二元线性分类。一个SVM模型的例子,如在空间中的点,映射,使得所述不同的类别的例子是由一个明显的差距是尽可能宽划分的表示。新的实施例则映射到相同的空间中,并预测基于它们落在所述间隙侧上属于一个类别。
除了进行线性分类,支持向量机可以使用核技巧,它们的输入隐含映射成高维特征空间中有效地进行非线性分类。一个支持向量机的构造一个超平面,或在高或无限维空间,其可以用于分类,回归,或其它任务中设定的超平面的。一个良好的分离通过具有到任何类的最接近的训练数据点的最大距离的超平面的一般实现中,由于较大的裕度下分类器的泛化误差。而原来的问题可能在一个有限维空间中所述,经常发生以鉴别集是不是在该空间线性可分。出于这个原因,有人建议,在原始有限维空间映射到一个高得多的立体空间,推测使分离在空间比较容易。保持计算负荷合理,使用支持向量机计划的映射被设计成确保在点积可在原空间中的变量而言容易地计算,通过定义它们中选择的核函数k(x,y)的计算以适应的问题。
在高维空间中的超平面被定义为一组点的点积与该空间中的向量是恒定的。限定的超平面的载体可被选择为线性组合与参数\alpha_i中发生的数据的基础上的特征向量的图像。这种选择一个超平面,该点中的x的特征空间映射到超平面是由关系定义:\字型\sum_i\alpha_ik(x_i中,x)=\mathrm{常数}。注意,如果k(x,y)变小为y的增长进一步远离的x,在求和的每一项测量测试点x的接近程度的相应数据基点x_i的程度。以这种方式,内核上面的总和可以被用于测量各个测试点的对数据点始发于一个或另一个集合中的要被鉴别的相对接近程度。
SVM分类器分类:
1)线性分类器:一个线性函数,可以用于线性分类。一个优势是不需要样本数据。线性分类器公式如下:
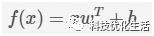 --(1)
--(1)
2)非线性分类器:支持线性分类和非线性分类。需要部分样本数据(支持向量),也就是αi≠0的数据。非线性分类器公式如下:
 --(2)
--(2)
其中,α, σ 和 b 是训练数据后产生的值。可以通过调节σ来匹配维度的大小,σ越大,维度越低。
SVM核心思想:
SVM目的是找到一个线性分类的最佳超平面 f(x)=xwT+b=0。求 w 和 b。首先通过两个分类的最近点,找到f(x)的约束条件。有了约束条件,就可以通过拉格朗日乘子法和KKT条件来求解,这时,问题变成了求拉格朗日乘子αi 和 b。对于异常点的情况,加入松弛变量ξ来处理。使用序列最小化SMO(Sequential Minimal Optimization)来求拉格朗日乘子αi和b。注意:有些αi=0的点,可以不用在分类器中考虑。
1)线性分类可以使用公式(1)和公式(2),对于公式(1)需要求解 w 和 b;对于公式(2)需要求解拉格朗日乘子αi和b;
2)非线性分类只能使用公式(2),不能使用公式(1),因为公式(1)是线性函数。非线性分类的问题将向量映射到高维度,需要使用核函数。
SVM实质:
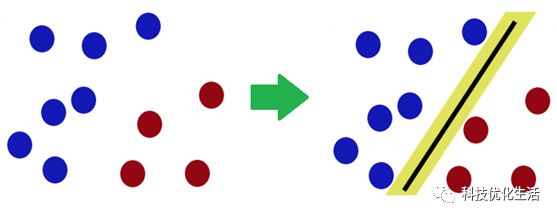
支持向量机(SVM)将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。建立方向合适的分隔超平面使两个与之平行的超平面间的距离最大化。其假定为,平行超平面间的距离或差距越大,分类器的总误差越小。
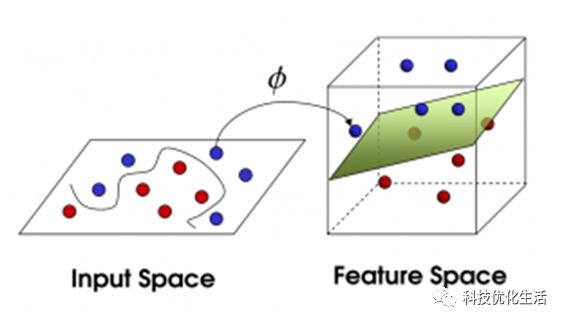
SVM关键因素:
SVM的关键在于核函数。低维空间向量集通常难于划分,解决的方法是将它们映射到高维空间。但这个办法带来的困难就是计算复杂度的增加,而核函数正好巧妙地解决了这个问题。也就是说,只要选用适当的核函数,可以得到高维空间的分类函数。在SVM理论中,采用不同的核函数将导致不同的SVM算法。在确定了核函数之后,由于确定核函数的已知数据也存在一定的误差,考虑到推广性问题,因此引入了松弛系数以及惩罚系数两个参变量来加以校正。在确定了核函数基础上,再经过大量对比实验等将这两个系数取定,则问题基本搞定。
SVM常用方法:
1)一对多法:把某一种类别的样本当作一个类别,剩余其他类别的样本当作另一个类别,这样就变成了一个两分类问题。然后,在剩余的样本中重复上面的步骤`这种方法箱要构造k个SVM模型,其中,k是待分类的个数。这种方案的缺点是训练样本数目大,训练困难。
2)一对一法: 在多值分类中,每次只考虑两类样本,即对每两类样本设计一个SVM模型,因此,总共需要设计k(k一l) /2个SVM模型。需要构造多个二值分类器,且测试时需要对每两类都进行比较,导致算法计算复杂度很高。
SVM决策树法:它通常和二叉决策树结合起来,构成多类别的识别器。这种方法的缺点是如果在某个节点上发生了分类错误,将会把错误延续下去,该节点后续下一级节点上的分类就失去了意义。weston虽然提出了用一个优化式解多值分类问题,但由于其变量t数目过多,所以只能在小型问题的求解中使用。
SVM是一种基于统计学习理论的模式识别方法,是一个二分类算法,它可以在N维空间找到一个(N-1)维的超平面,这个超平面可以将这些点分为两类。也就是说,平面内如果存在线性可分的两类点,SVM可以找到一条最优的直线将这些点分开。它在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。SVM应用范围很广,已经在许多领域,如生物信息学,文本和手写识别等中都取得了成功的应用。目前主要应用于模式识别领域。
结语:
在机器学习中,支持向量机(SVM)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。已经在许多领域,比如生物信息学,文本和手写识别等中都取得了成功的应用。目前主要应用于模式识别领域。
以上是关于人工智能(30)–支持向量机的主要内容,如果未能解决你的问题,请参考以下文章
LSSVM回归预测基于matlab人工蜂群算法优化最小二乘支持向量机LSSVM数据回归预测含Matlab源码 2213期