《机器学习》笔记-贝叶斯分类器
Posted 机器学习算法工程师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《机器学习》笔记-贝叶斯分类器相关的知识,希望对你有一定的参考价值。
编辑:陈人和
前 言
如今机器学习和深度学习如此火热,相信很多像我一样的普通程序猿或者还在大学校园中的同学,一定也想参与其中。不管是出于好奇,还是自身充电,跟上潮流,我觉得都值得试一试。对于自己,经历了一段时间的系统学习(参考《机器学习/深度学习入门资料汇总》),现在计划重新阅读《机器学习》[周志华]和《深度学习》[Goodfellow et al]这两本书,并在阅读的过程中进行记录和总结。这两本是机器学习和深度学习的入门经典。笔记中除了会对书中核心及重点内容进行记录,同时,也会增加自己的理解,包括过程中的疑问,并尽量的和实际的工程应用和现实场景进行结合,使得知识不只是停留在理论层面,而是能够更好的指导实践。记录笔记,一方面,是对自己先前学习过程的总结和补充。 另一方面,相信这个系列学习过程的记录,也能为像我一样入门机器学习和深度学习同学作为学习参考。
章节目录
贝叶斯决策论
极大似然估计
朴素贝叶斯分类器
半朴素贝叶斯分类器
贝叶斯网
EM算法
贝叶斯决策
贝叶斯决策论(Bayesian decision theory)是概率框架下的基本方法。
假设有N种可能的类别标记,即y={c1,c2,...,cN},λij是一个将真实标记为cj的样本误分类为ci产生的期望损失(expected loss),即在样本x上的“条件风险”(conditional rsik),
我们的任务是寻找一个判断准则,以最小化总体风险。
欲使用贝叶斯判定准则来最小化决策风险,首先要获得后验概率P(c|x)。然而,在现实任务中这通常难以直接获得。从这个角度来看,机器学习所要实现的是基于有限的训练样本尽可能准确的估计出后验证概率P(c|x)。大体来说主要有两种策略:
给定x,可通过直接建模P(c|x)来预测c,这样得到的是“判别式模型”(discriminative models)
先对联合概率分布P(x,c)建模,然后再由此获得P(c|x),这样得到的是“生成式模型”(generative models)。 显然,前面介绍的决策树、BP神经网络、支持向量机等,都可归入判别式模型的范畴。对于生成式模型来说,必然考虑,
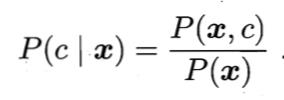
基于贝叶斯定理可写成,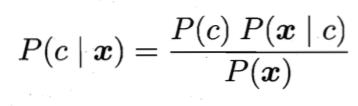
对给定样本x,证据因子P(x)与类标记无关。根据大数定理,先验概率P(c)可通过各类样本出现的频率来进行估计。因此,估计P(x|c)的问题就主要转换为如何基于训练样本D来估计似然P(x|c)。
极大似然估计
估计类条件概率的一种常见策略是先假定其具有某种确定的概率分布形式,再基于训练样本对概率分布的参数进行估计。 概率模型的训练过程就是参数估计(parameter estimation)过程。对于参数估计,统计学界的两个学派分别提供了不同的解决方案:
* 频率主义学派(Frequentist)认为参数虽然未知,但确实客观存在的固定值,因此,可通过优化似然函数等准则来确定参数值。
* 贝叶斯学派(Bayesian)则认为参数是未观察到的随机变量,其本身也有分布,因此,可假设参数服从一个先验分布,然后基于观测到的数据来计算参数的后验分布。 书中的介绍来自频率主义学派的极大似然估计(Maximum Likelihood Estimation,简称MLE),这是根据数据采样来估计概率分布参数的经典方法。
朴素贝叶斯分类器
基于属性条件独立性假设,条件概率P(c|x)可重写为,
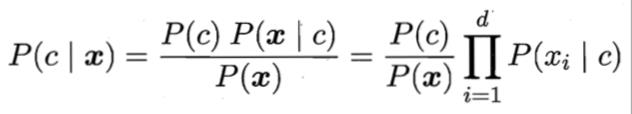
其中d为属性数目,xi为x在第i个属性上的取值。
由于对所有类别来说P(x)相同,因此贝叶斯判定准则可写为,
这就是朴素贝叶斯分类器的表达式。
半朴素贝叶斯分类器
为了降低贝叶斯公式中估计后验概率P(c|x)的困难,朴素贝叶斯分类器采用了属性条件独立性假设,但在现实任务中这个假设往往很难成立。于是,人们尝试对属性条件独立性假设进行一定程度的放松,因此产生了一类称为“半朴素贝叶斯分类器”(semi-naive Bayes classifiers)的学习方法。
贝叶斯网
EM算法
EM(Expectation-Maximization)算法就是常用的估计参数隐变量的利器。
end
机器学习算法全栈工程师
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助
以上是关于《机器学习》笔记-贝叶斯分类器的主要内容,如果未能解决你的问题,请参考以下文章