机器学习——朴素贝叶斯分类器
Posted somedayli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——朴素贝叶斯分类器相关的知识,希望对你有一定的参考价值。
贝叶斯分类是一类分类算法的总称,这类算法均已贝叶斯定理为基础,因此统称为贝叶斯分类。在贝叶斯分类器中,常用朴素贝叶斯,就类似于看见黑人,大多会认为来自非洲。
事件A在事件B(发生)的条件下的概率,与事件B在事件A(发生)的条件下的概率是不一样的,但他们有确定的关系,贝叶斯定理就是对在这种关系的陈述。
优点:
简单、高效、健壮。能应用到大型数据库中,方法简单且分类准确率高,速度快。
缺点:
相关属性不独立,会影响贝叶斯分类准确率。
改进方法:
降低独立性假设的算法, 例如,TAN(Tree Augmented Bayes Network)算法、贝叶斯网络分类器(Bayes Network Classifier,BNC)。
朴素贝叶斯分类步骤:
(1)设为一个待分类项,a为x的一个特征属性。
(2)有类别集合
(3)计算;
(4)如果,则。
总体来说,大致分为三个阶段:

实例介绍:
运用朴素贝叶斯算法根据客户的16个属性,为一家银行建一个分类器,判断客户是否愿意购买理财产品:
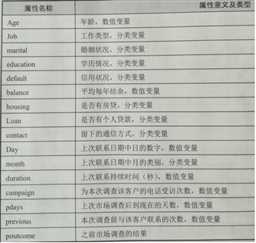
MATLAB实现代码:
1 %% ————————————2.朴素贝叶斯分类器——————————————%% 2 load ‘bank.mat‘; 3 names = bank.Properties.VariableNames;%使用数据文件,记录自变量和因变量的属性名 4 category = varfun(@iscellstr,bank,‘Output‘,‘uniform‘); %输出格式为数值格式。为字符串的返回结果为1,为数字的返回结果为0 5 for i = find(category) 6 bank.(names{i}) = categorical(bank.(names{i})); 7 %将bank中的属性创建分类数组。bank.(names{i}) 的类别是bank.(names{i})经过分类后的唯一值且经过排序 8 end 9 catPred = category(1:end-1); 10 dist = repmat({‘normal‘},1,width(bank)-1); 11 dist(catPred) = {‘mvmn‘}; 12 % 13 X = table2array(varfun(@double,bank(:,1:end-1)));%预测变量 14 Y = bank.y; 15 disp(‘数据中YES&No的统计结果‘); 16 tabulate(Y) %求重复数字的个数使用tabulate,占比率 17 Xnum = [X(:,~catPred) dummyvar(X(:,catPred))]; 18 Ynum = double(Y)-1; 19 20 %%%设置交叉验证方式 21 cv = cvpartition(height(bank),‘holdout‘,0.40); 22 Xtrain = X(training(cv),:); 23 Ytrain = Y(training(cv),:); 24 Xtest = X(test(cv),:); 25 Ytest = Y(test(cv),:); 26 XtestNum = Xnum(test(cv),:); 27 YtestNum = Ynum(test(cv),:); 28 %训练分类器 29 Nb = NaiveBayes.fit(Xtrain,Ytrain,‘Distribution‘,dist); 30 %进行预测 31 Y_Nb = Nb.predict(Xtest); 32 Yscore_Nb = Nb.posterior(Xtest); 33 Yscore_Nb = Yscore_Nb(:,2); 34 %计算混淆矩阵 35 disp(‘贝叶斯分类结果‘); 36 C_nb = confusionmat(Ytest,Y_Nb)
以上是关于机器学习——朴素贝叶斯分类器的主要内容,如果未能解决你的问题,请参考以下文章