机器学习A-Z~朴素贝叶斯
Posted LEAFW
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习A-Z~朴素贝叶斯相关的知识,希望对你有一定的参考价值。
本文要讲述一个古老的机器学习算法,叫做朴素贝叶斯。这个算法比较简单明了,没有使用非常复杂的数学定理。用到的核心的数学理论就是概率中的一个定理,叫做贝叶斯定理(Bayes' Theorem)。
贝叶斯定理
现在我们看一个例子,假设有一个生产扳手的工厂,有两台机器。这两台机器分别生产了很多扳手,而且每个扳手都能看出是哪个机器生产的。现在有了很多很多生产出的扳手,并且这些扳手里面有达标的正品和不达标的次品。现在要解决的问题是:我们想知道,2号机器它生产的产品是次品的概率是多少。解决这个问题要用到的定理就是贝叶斯定理。
学过概率论的朋友应该对它有点了解,这里也稍微解释下。我们给上面的问题提供一些条件:
1号机器每小时生产30个扳手
2号机器每小时生产30个扳手
所有的产品中有1%的次品
所有次品中有50%来自机器1,50%来自机器2
问题是:机器2生产的产品是次品的概率是多少?
现在一步步往下计算,首先计算最后生产的产品是机器1生产的概率P(Mach1)=30/50=0.6,最后生产的产品是机器1生产的概率P(Mach2)=20/50=0.4。然后所有产品中有1%的次品表示P(Defect) = 1%。接下来的条件表示要用到条件概率P(Mach1 | Defect) = 50%。这句话的意思就是如果一个产品是次品,那么它是机器1生产的概率是50%。同理P(Mach2 | Defect) = 50%。我们要求的是P(Defect | Mach2)= ?。带入贝叶斯定理公式: 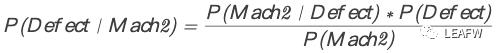
结果为0.50.01/0.4=1.25%。显然,使用贝叶斯定理可以通过一些很容易获得的概率来得出不容易获得的概率结果,可以节省我们很多的精力。这就是贝叶斯定理的应用。
朴素贝叶斯
接下来来讲朴素贝叶斯分类器,我们要用到的就是上述的贝叶斯定理。其中P(A|B)被称作后验概率,P(B|A)和P(B)这两个概率并不完全是概率,因为朴素贝叶斯分类器中,B代表特征,所以说这两个概率我们称作似然。
来看看下面的例子,有两组数据绿组和蓝组,x1代表人群的年龄,x2代表他们的收入。所有的红组代表所有步行上班的人,绿组代表开车上班的人。现在如果出现一个新的点,我们要对它进行分类,确定是分到红色组中还是绿色组中。
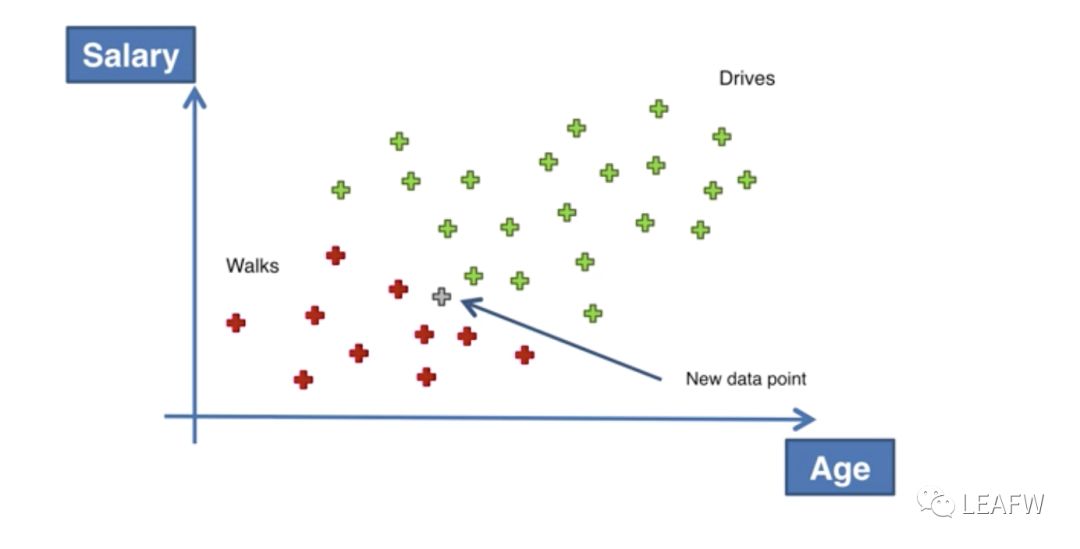
我们要使用朴素贝叶斯来解决这个分类问题,首先来看看我们需要经过的三个步骤。
第一步,看看这个贝叶斯公式: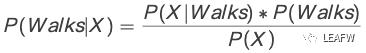
这里的X就是它的特征。对于新的点,它有对应的年纪和收入就是这个新用户的特征,我们要求的就是已知这些特征,要得到它分到红组或者绿组的概率。这里的P(Walks)就是随机抽一个人,它是走路上班的概率,这个也被称作先验概率,对应的就是后验。P(X)指的是随机抽一个人,他所显示的特征和新用户的特征的似然或者可能性。这里的似然也是个概率,它是对数据特征的概率,因此我们把它叫做似然。再然后,这里的P(X|)指的是对这个数据特征的概率,因此叫做似然。接下来第三部要求的也是个似然P(X|Walks),或者叫做边际的似然,边际的可能性。这样我们就能求出后验概率P(Walks|X)。
求解完步行部分的再求开车部分的:
然后我们就可以比较P(Walks|X)和P(Drives|X),也就是已知用户的特征,其步行或者开车的概率。这两个概率哪个比较大,那么就可以将这个用户分类到那个分组中。
那么开始按照上面说的流程进行计算,首先比较简单,P(Walks)=Number of Walkers/Total Observations=10/30。接下来,计算P(X),也就是似然。这个是朴素贝叶斯中核心的一步。这里的X指的是新用户他所代表的特征,即年纪和收入。我们可以围绕这个新用户画一个圈,那么这个圈就代表着在这个二维数据空间中的所有用户,他们的特征和新用户非常相似。要求的P(X)就是我们原先数据空间中的所有数据,它的特征坐落在这个圈中的概率。那么我们要计算的就是原先数据中与新用户拥有相似特征的个数除以总的人数。P(X)=Number of Similar Observations/Total Observations=4/30.
再然后求P(X}Walks),也就是边际似然,那么就是如果一个人是步行上班,那么它坐落在这个圈中的概率。那么这里的计算公式很简单,就是P(X|Walks) = Among those who Walk/Total number of Walkers=3/10。这样,我们就可以求得后验概率P(Walks|X) = 0.75。同样的方法可以得到P(Drives|X)=0.25。
由于0.75>0.25,因此这个用户分配到步行上班组的概率大于分配到开车上班组的概率。
朴素贝叶斯的一些补充说明
接下来我们来看看几个问题,首先第一个,为什么把它做朴素贝叶斯?或者为什么朴素?当我们使用朴素贝叶斯方法的时候已经做过一个假设,这个假设就是数据的所有特征都是独立的。在上述的例子里的两个特征,年龄和薪水,实际上这两者是可能有关系的,一般来说年龄越大可能薪水就越大。但这里假设年龄和薪水两者没有相关性。因此在一个机器学习的问题中,我们经常会做一些假设,这些假设并不一定都是对的,但这些假设可以帮助我们更高效快捷的解决问题。我们允许有一点误差,因为我们的终极问题是解决问题。
接下来第二个问题,似然函数P(X),上面计算这个函数的方法是先在新数据周围画了个圈,表示在这个圈里的数据点,都表示和这个新数据点有相似的特征,那么接下来这个似然就是指如果有一个新的点,那么它坐落在这个圈中的概率。那么这个P(X)你会发现,它跟我们想要计算的后验概率是和红组相关还是绿组相关是没有关系的。我们最后要计算的两个后验概率的公式中的分母都是P(X),那么我们比较这两者实际上可以把这个P(X)个消掉,也就是说可以直接比较两者的分子P(X|Walks)P(Walks)和P(X|Drives)P(Drives)。
最后一个问题,若我们已知的组超过两组怎么办?目前已经有两组的情况下,比较两者的后验概率,那么我们将新数据分配到更大的概率的分组中。那么同理如果有三组的话,就是比较三者的后验概率,哪个更大就分配到其分组中。
代码实现
这里的代码实现实际上也只是讲之前的文章中将分类器改成朴素贝叶斯即可:
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, y_train)
以上,就是朴素贝叶斯算法的相关知识。
以上是关于机器学习A-Z~朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章