深度学习下一阶段:神经架构自学习,带来最优计算机视觉模型
Posted 大数据文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习下一阶段:神经架构自学习,带来最优计算机视觉模型相关的知识,希望对你有一定的参考价值。
大数据文摘出品
来源:medium
编译:张大笔茹、胡笳、李雷、钱天培
深度学习是人工智能模型的先驱。从图像识别、语音识别,到文字理解,甚至自动驾驶,深度学习的来临极大地丰富了我们对AI潜力的想象。
那么,深度学习为何如此成功呢?
主流思想认为,一个重要的原因是,深度学习成功的原因是不依靠人类直觉来构建或表示数据的特征(视觉,文本,音频......),而是建立一个神经网络架构来自发学习这些特征。
关键词是特征。从特征工程,到特征搜索,到特征学习——每一阶段的进步都能带来巨大的性能提升。
既然“特征”上大有文章可做,那么“网络结构”是否也可以借鉴同样的经验呢?
没错,也可以!
这个新颖的观点已经得到了Allen Institute for AI最新研究的支持。他们的最新研究表明,计算机学习来的神经网络架构可以比人类设计的更好。
在训练期间,他们的网络的可以灵活改变网络架构——它既学习网络参数,也学习结构本身。所学习的架构具有高度稀疏的特性,因此就运算运算而言,它将是一个小得多却可以实现高精度的模型。
在高效稀疏计算硬件大力发展的环境下,这可能是深度学习模型下一演变阶段的重要触发因素。
在了解他们的最新成果前,让我们先回顾一下,从二十年前到开始进入深度学习时代AI模型在计算机视觉技术领域的关键发展阶段。同样的趋势在其他深度学习领域也有类似体现。
计算机视觉三个发展阶段
特征工程阶段
尝试人工找到图像中承载图像语义的高维向量。成功的例子有:SIFT,HOG,ShapeContext,RBF和Intersection Kernel。这些特征和函数是基于对人类视觉识别过程的模拟。这是当时计算机视觉技术背后的基础科学。经过了几年的直觉驱动研究,计算机视觉技术科学家并未能开发新的功能,这使得该领域进入了第二阶段。
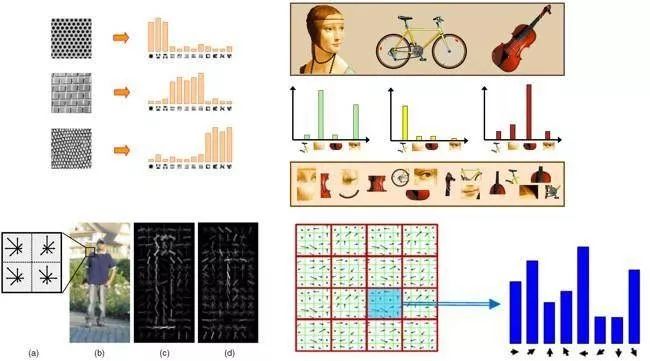
特征搜索阶段
又叫自动搜索过程,通过组合不同的可能特征或核函数来提高特定应用程序的准确性(例如,对象分类)。一些成功方法的包括:Feature selection methods 以及 Multiple Kernel Models。这些过程虽然计算量大,但却能提高计算机视觉模型的准确性。另一个主要局限是搜索空间的构建块(特征函数)是基于人类对视觉识别的直觉手动设计的。但有一些研究表明,人类可能无法准确说出自己是如何区分对象类别的。
例如,你能说明自己如何区分狗与猫的照片吗?你选择的任何特征(例如耳朵上的清晰度,或眼睛中的形状和颜色),都是猫和狗共有的,但是看照片却能立即说出它是狗或猫。这使得一些科学家放弃用传统的自下而上的模式设计特征驱动的计算机视觉模型,转向让计算机自己设计特征识别的阶段。
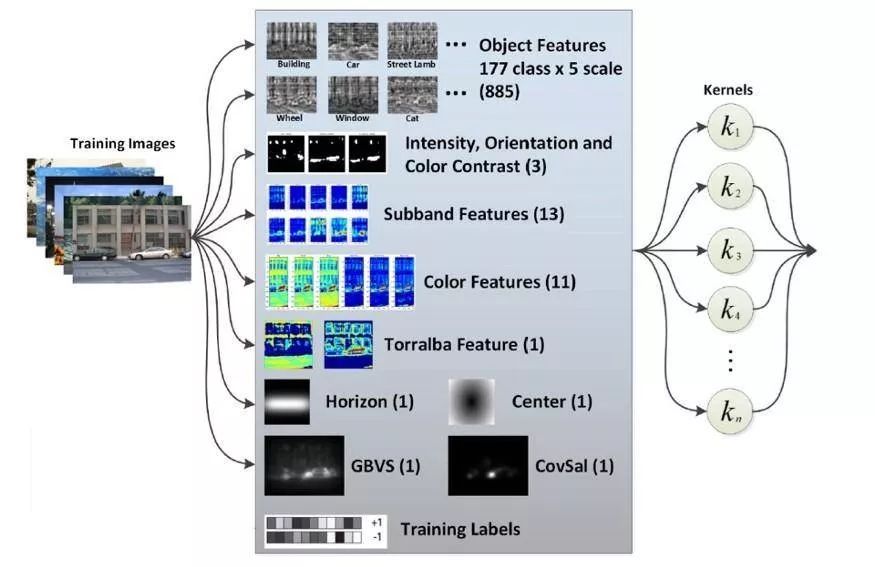
特征学习阶段
这是自动从高维向量空间确定视觉特征的阶段,该过程通过释义图像的内容来使计算机执行特定任务,例如对象分类。深度卷积神经网络架构(CNN)的发展使这种能力成为可能。由于在设计特征的过程中没有人为干预,这种算法也被称为端到端模型。实际上,由于该过程是高度计算密集型并且需要大量数据来训练底层神经网络,人类几乎无法解释其构造的特征。随着并行处理器硬件(例如GPU和TPU)的进步以及大规模数据集的可用性使其成为可能并取得成功。
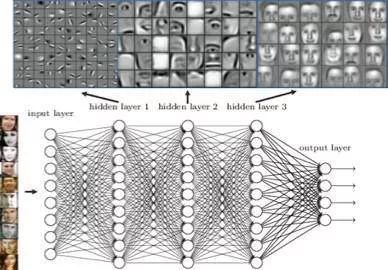
太赞了!深度学习好像能独立工作了。既然如此,那么计算机视觉科学家在其中需要扮演什么角色呢?!
展望未来
想象一下,如果我们用“架构”来取代“特征”这个词,结合上述三个阶段,大概可以说明深度学习今后的发展趋势。
架构工程
这与“特征学习”阶段几乎完全一样。需要手动为特定任务设计卷积神经网络架构。其主要原理是简单但更深(即更多层)的架构可以获得更高的准确性。在这个阶段,设计架构和训练(网络优化)技术是计算机视觉(以及许多其他DCNN应用程序)的主要目标。这些网络设计基于人类自身视觉识别系统的认知。一些成功的架构设计包括:AlexNet,VGGNet,GoogleNet和ResNet。这些模型的主要的局限在于计算的复杂性。他们通常需要运行数十亿次算术运算(浮点运算)来处理单个图像。在实践中,为了使模型能够以足够快的速度运行,通常需要使用GPU并消耗大量功率。因此,现代AI模型主要通过强大的云服务器来实现。
这促使科学家设计可以运行在边缘设备上的更高效的AI模型。一些成功的模型包括:Xnor-net,Mobilenet和Shufflenet。类似于“特征工程”阶段,几年后,江郎才尽的研究人员转向了“搜索”阶段。
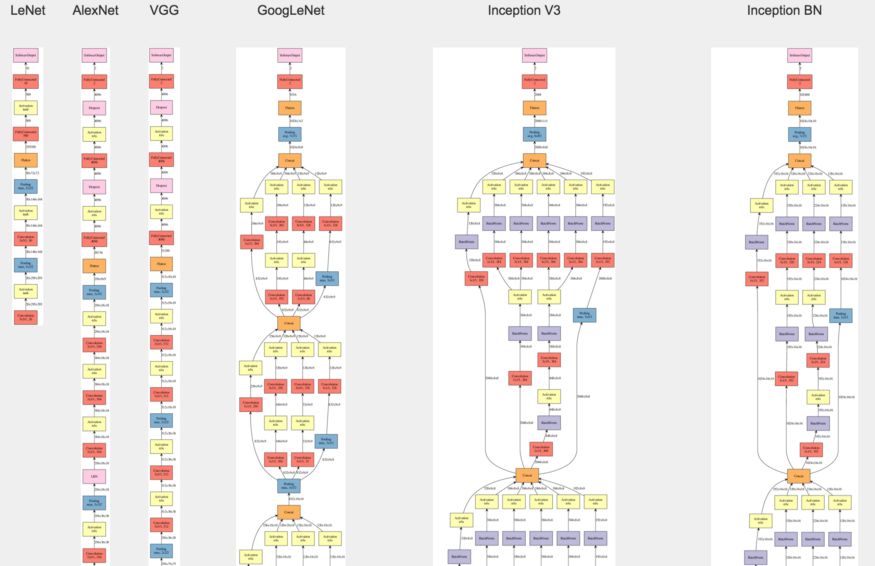 深度学习出现后,计算机视觉背后的基础科学变为网络架构设计(图片来自Joseph Cohe
n)
深度学习出现后,计算机视觉背后的基础科学变为网络架构设计(图片来自Joseph Cohe
n)
架构搜索
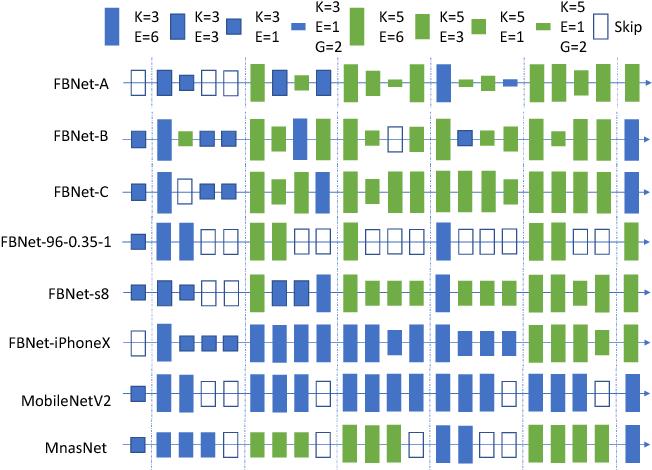
这是当前最先进的AI模型。主要原理是使用之前成功架构的构建块并尝试自动搜索这些块的组合,以构建新的神经网络架构。其关键目标是建立一个需要少量运算却高精度的架构。一些成功的神经架构搜索方法包括:NASNet,MNASNe和FBNet。由于其可能的组合的搜索空间非常大,训练这些模型比标准深度学习模型需要更多的计算量和数据。类似于“特征搜索”阶段,这些模型也受到基于人类直觉的手动设计其构建块的约束。根据以前的经验,人类对如何设计神经架构的直觉没有计算机好。最新研究表明,随机连接的神经网络完胜几种人工设计的架构。
综上所述,显然深度学习的下一阶段是让计算机自己设计架构。
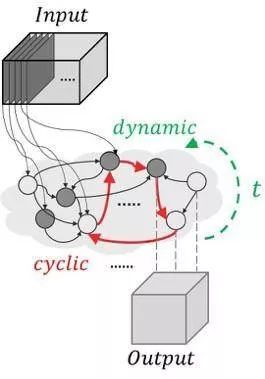
架构学习阶段
最近我们在Xnor.ai和Allen Institute for AI建立了一个名为Discovering Neural Wirings的新模型,用于直接从数据中自动学习神经网络架构。在该模型中,我们将神经网络设置为无约束图并且放宽层的概念,使节点(例如图像的通道)能够彼此形成独立的连接。这会使得可能的网络空间会更大。在训练期间,该网络的搭建不固定——它既学习网络参数,也学习结构本身。网络结构可以包含图中的循环,即形成了存储器结构的概念。所学习的架构具有高度稀疏的特性,因此就算术运算而言它将是一个小得多却可以实现高精度的模型。
代码:
当然,类似于“特征学习”阶段,这个深度学习阶段需要在训练中进行大量的计算以处理大图并且需要大量的数据。我们坚信,随着专门用于稀疏图形计算的硬件的发展,自动发现最佳网络架构技术会越来越成熟,实现高度精确、高效计算的边缘AI模型指日可待。
链接:
实习/全职编辑记者招聘ing
志愿者介绍




以上是关于深度学习下一阶段:神经架构自学习,带来最优计算机视觉模型的主要内容,如果未能解决你的问题,请参考以下文章