神经网络基础
Posted Keep--Silent
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络基础相关的知识,希望对你有一定的参考价值。
第08天:初始深度学习
第08天:初始深度学习-神经网络基础(1)
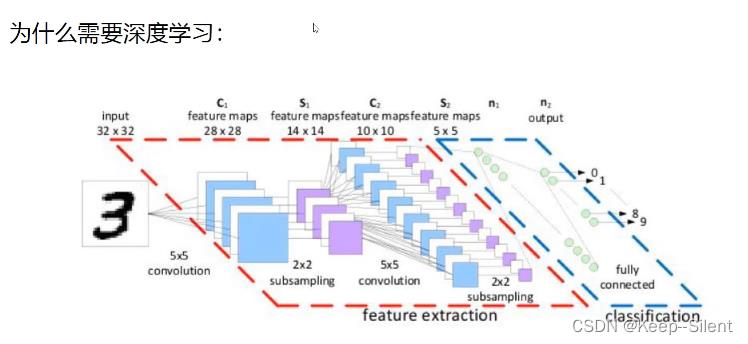
5-深度学习要解决的问题 :
深度学习要解决的问题 :提取特征
机器学习流程:
- 数据获取
- 特征工程
- 建立模型
- 评估与应用
特征工程的作用:
- 数据特征决定了模型的上限
- 预处理和特征提取是最核心的
- 算法和参数选择决定了如何逼近这个上限
特征提取
- 传统提取:找特征难

- 深度学习:
6-深度学习应用领域
7-计算机视觉任务
8-视觉任务中遇到的问题
机器学习常规套路:
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
K近邻算法:
- 计算一直类别数据集中的点与当前点的距离
- 按距离以此排序
- 选取与当前距离最小的k个点
- 确定前k个点所在类别的出现概率
- 返回前k个点出现频率最高的类别作为当前点预测分类
使用k近邻会使得背景相同的分为同类,并不适合
9-得分函数
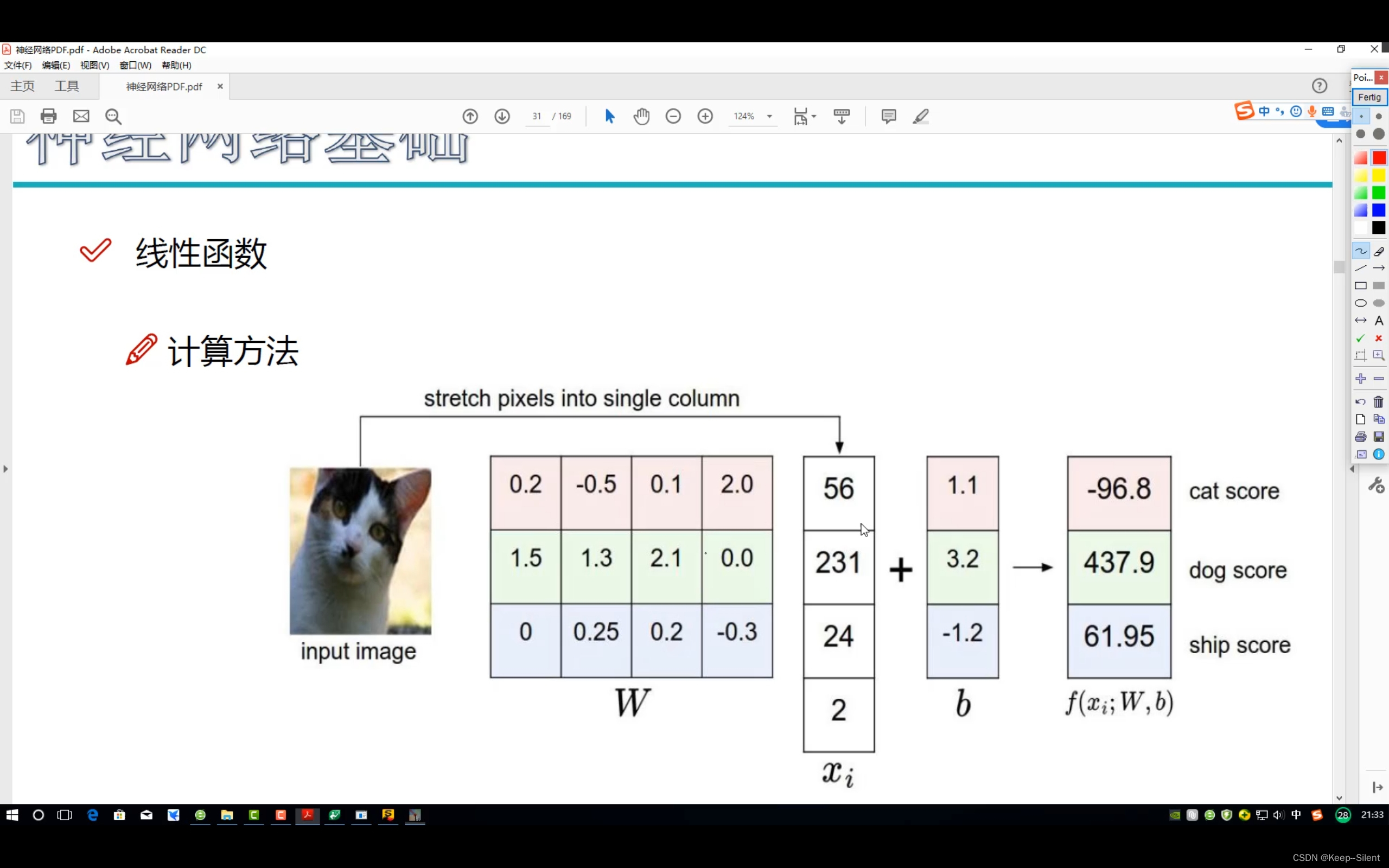
- 线性函数:
从输入到输出的映射
x:img(32*32*3=3072),W:权重参数,b(偏执参数)
f(x,W)=Wx
W:1*3072;x:3072*1
假设3类,图片img(2*2*1)
W=3*4;x=4*1;b=3*1
f=WX+b。
- 损失函数
如 L i = ∑ j ≠ y i max ( 0 , s j − s y i + 1 ) L_i=\\sum_j\\neq y_i\\max(0,s_j-s_y_i+1) Li=∑j=yimax(0,sj−syi+1)

10-损失函数的作用
损失函数=数据损失+正则化惩罚项
L
=
1
N
∑
i
=
1
N
∑
j
≠
y
i
max
(
0
,
f
(
x
i
;
W
)
j
−
f
(
x
i
;
W
)
y
i
+
1
)
+
λ
R
(
W
)
L=\\frac1N\\sum_i=1^N\\sum_j\\neq y_i\\max(0,f(x_i;W)_j-f(x_i;W)_y_i+1)+\\boxed\\lambda R(W)
L=N1∑i=1N∑j=yimax(0,f(xi;W)j−f(xi;W)yi+1)+λR(W)
R
(
W
)
=
∑
k
∑
l
W
k
,
l
2
R(W)=\\sum_k\\sum_l W_k,l^2
R(W)=∑k∑lWk,l2
防止过拟合
Softmax分类器
归一化:
P
(
Y
=
k
∣
X
=
x
i
)
=
e
∗
k
∑
i
e
∗
j
where
s
=
f
(
x
i
;
W
)
P(Y=k|X=x_i)=\\frace^*_k\\sum_i e^*_j\\quad\\textwhere\\quad s=f(x_i;W)
P(Y=k∣X=xi)=∑ie∗je∗kwheres=f(xi;W)
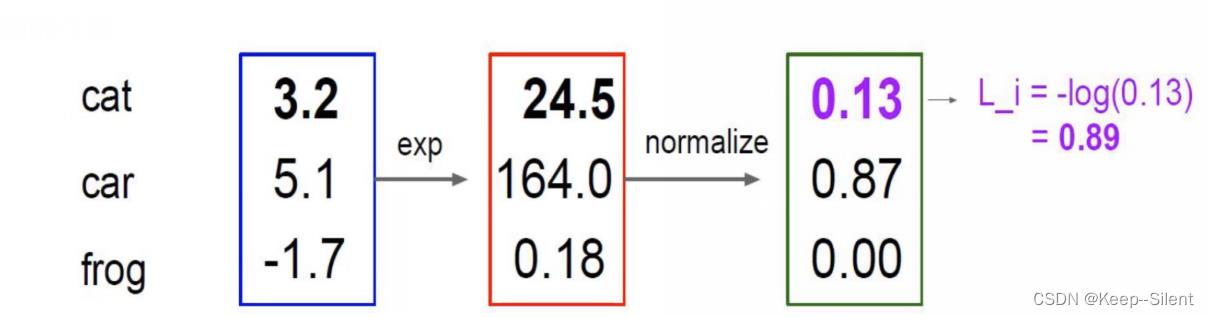
计算损失值:
L
i
=
−
log
P
(
Y
=
y
i
∣
X
=
x
i
)
L_i=-\\log P(Y=y_i|X=x_i)
Li=−logP(Y=yi∣X=xi)
11-前向传播整体流程

第08天:初始深度学习-神经网络基础(2)
1-反向传播计算方法


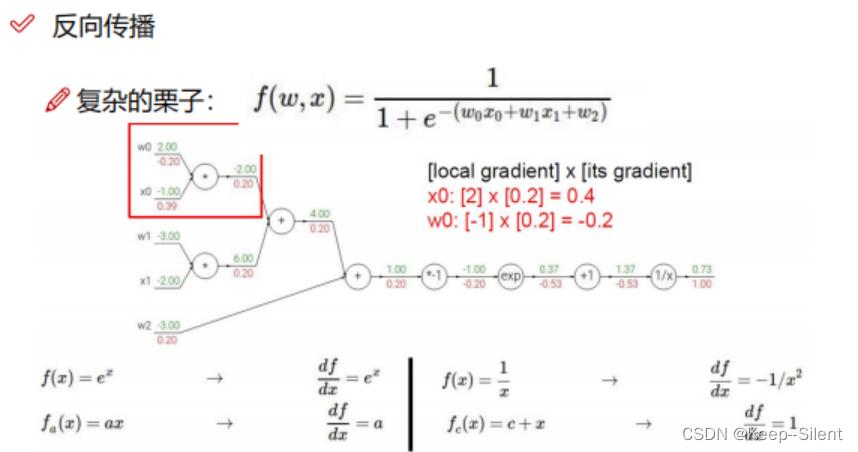
加法门单元:均等分配
MAX门单元:给最大的
乘法门单元:互换的感觉

2-神经网络整体架构
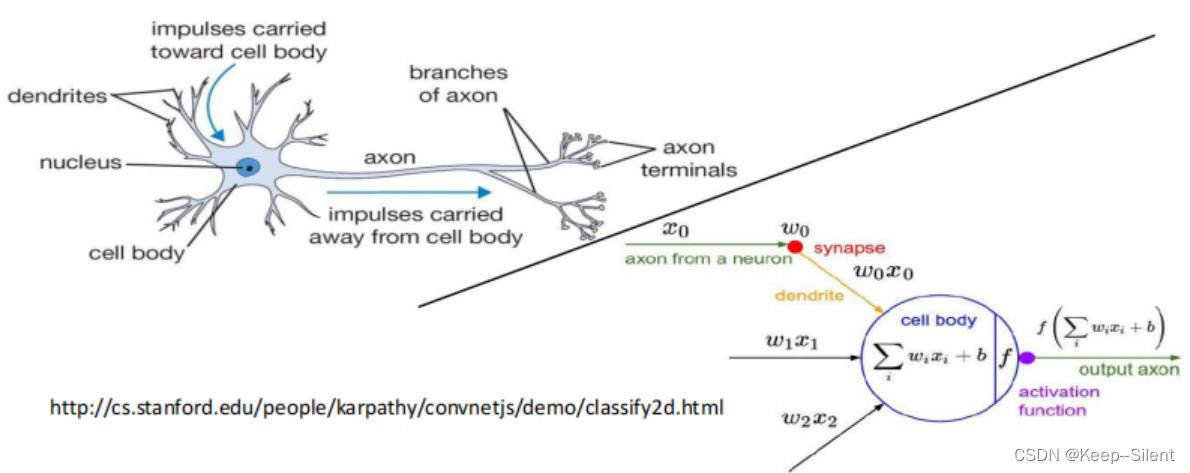
整体架构
- 层次结构
- 神经元
- 全连接
- 非线性

3-神经网络架构细节
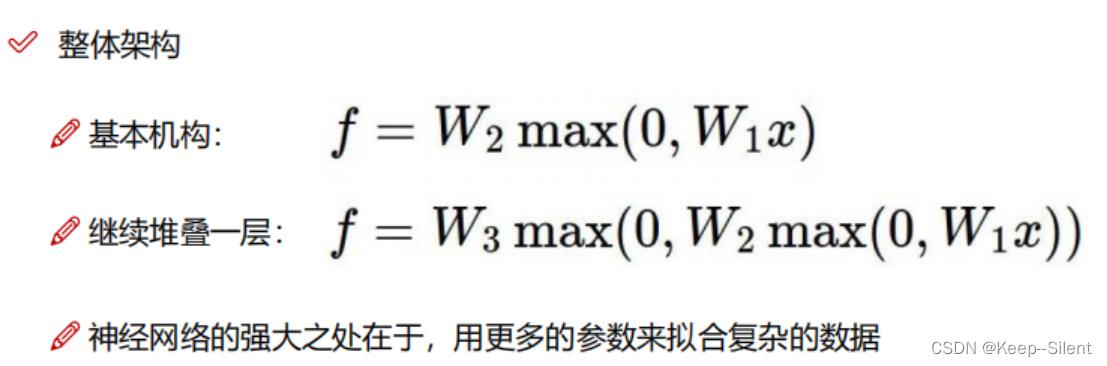
4-神经元个数对结果的影响

5-正则化与激活函数
Sigmoid和Relu
Sigmoid:当数值过大或者过小,梯度消失。
Relu:当前使用得较多
- 数据预处理:
- 中心化
- 正则化

- 参数初始化
- 通常我们都使用随机策略来进行参数初始化
W = 0.01 ∗ n p . r a n d o m . r a n d n ( D , H ) \\mathrmW = 0.01* np.random. randn(D,H) W=0.01∗np.random.randn(D,H)
- 通常我们都使用随机策略来进行参数初始化
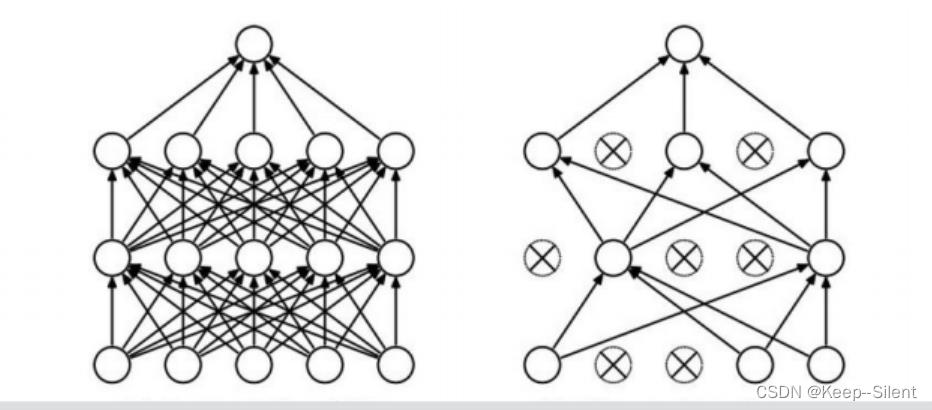
6-神经网络过拟合解决方法
过拟合是神经网络非常头疼的一个大问题:DROP-OUT随机杀死一些神经元
以上是关于神经网络基础的主要内容,如果未能解决你的问题,请参考以下文章