“深度学习一点也不难!” Posted 2021-04-19 CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“深度学习一点也不难!”相关的知识,希望对你有一定的参考价值。
通常情况下,机器学习尤其是深度学习的使用往往需要具备相当的有利条件,包括 一个大型的数据集,设计有效的模型,而且还需要训练的方法——但现在, 利用迁移学习就可以消除掉这些瓶颈 。
以下为译文:
在不久之前,为了有效地使用深度学习,数据科学团队需要:
一种新颖的模型架构,很可能需要自己设计;
大型数据集,很可能需要自己收集;
大规模训练模型的硬件或资金。
这些条件和设施成为了限制深度学习的瓶颈,只有少数满足这些条件项目才能应用深度学习。
我们看到用户开始试用基于深度学习的新一代产品,而且与以往不同的是,这些产品使用的是以前没有出现过的任何一种模型架构。
这种增长背后的驱动力是迁移学习(transfer learning)。
从广义上讲,迁移学习的思想是专注于存储已有问题的解决模型(例如识别照片中的花朵),并将其利用在其他不同但相关问题上(例如识别皮肤中的黑素瘤)。
迁移学习有多种方法,但其中一种方法——微调法(finetuning)得到了广泛采用。
在这种方法中,团队采用预先训练好的模型,然后通过删除或重新训练模型的最后一层,将其用于新的相关任务。例如,AI Dungeon是一款开放世界的文字冒险游戏,因其AI生成的生动形象的故事而广为传播:
注意,AI Dungeon不是Google研究实验室开发的项目,只是一名工程师构建的黑客马拉松项目。
AI Dungeon的创建者Nick Walton并没有从零开始设计模型,而是采用了最新的NLP模型(OpenAI GPT-2),然后对其进行微调来设置自己的冒险文字。
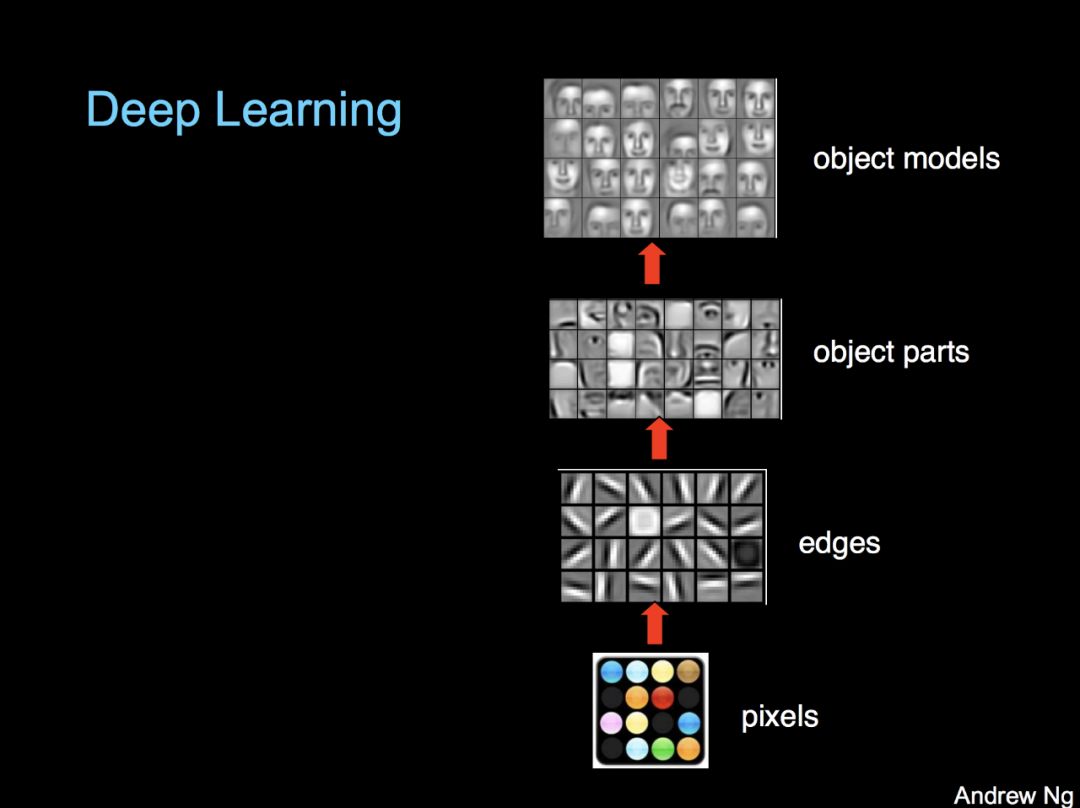
这种方法完全可行的原因是,在神经网络中,最初几层主要负责简单、通用的特征,而最后几层主要负责与任务有关的分类/回归。Andrew Ng 用一个图像识别模型的例子,以可视化的方式介绍了各层与任务本身的相关性:
事实证明,基础层学习的通用知识通常可以很好地迁移到其他任务上、。在AI Dungeon的示例中,GPT-2对通用英语有良好的理解,只需要对最后几层进行一些重新训练,即可在冒险游戏中给出优异的表现。
每位工程师都可以通过这种流程,在几天之内部署一个模型,以在新的领域实现最新的结果。
本文开头我提到了使用机器学习(尤其是深度学习)需要具备的有利条件。你需要一个大型的数据集,需要设计有效的模型,而且还需要训练的方法。
这意味着一般而言,某些领域的项目或缺乏某些资源的项目就无法开展。
通常,深度学习需要大量带标签的数据,但在许多领域中,这些数据根本不存在。然而,迁移学习可以解决这个问题。
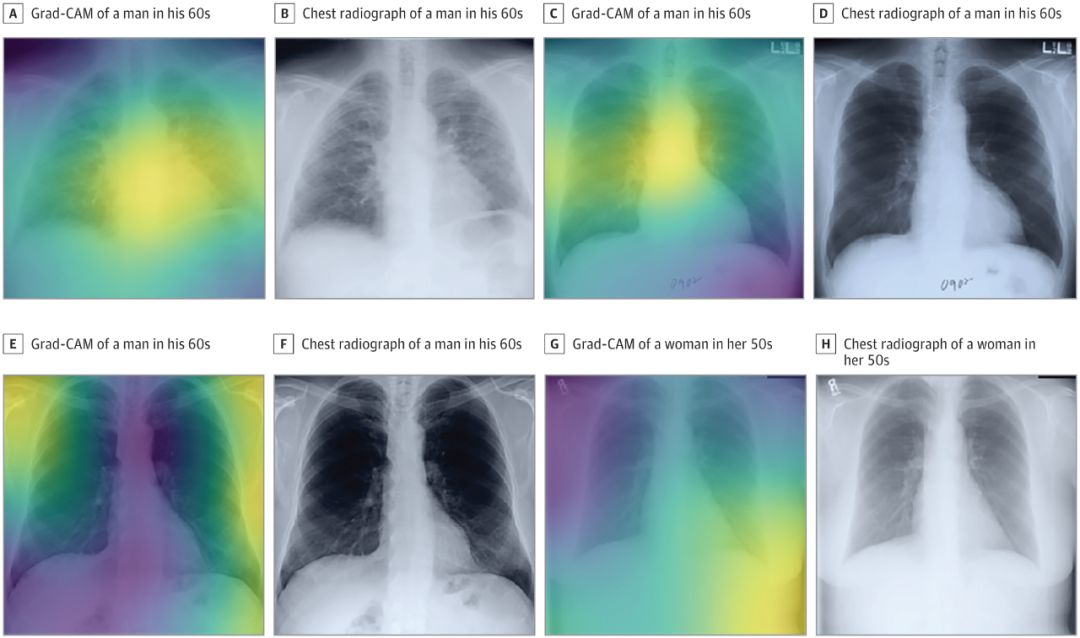
例如,哈佛医学院附属团队最近部署了一个模型,该模型可以“根据胸部X光片,预测长期的死亡率,包括非癌性死亡”。
他们只有5万张带标签图像的数据集,不足以从头开始训练CNN(卷积神经网络)。于是,他们采用了预先训练好的的Inception-v4模型(该模型在拥有超过1400万张图像的ImageNet数据集上进行了训练),并使用迁移学习和轻微的架构调整,让模型适应了他们的数据集。
最终,他们的CNN成功地使用每位患者的一张胸部图像,生成了与患者的实际死亡率相关的风险评分。
在大量数据上训练模型面临的难题不仅仅是获取大型数据集,还有资源和时间的问题。
例如,当Google开发最尖端的图像分类模型Xception时,他们训练了两个版本:一个在ImageNet数据集(1400万张图像)上,另一个在JFT数据集(3.5亿张图像)上。
即使他们在训练中采用了60个NVIDIA K80 GPU,并进行了各种优化,但每次ImageNet实验的运行都需要3天的时间。而JFT实验耗时一个多月。
如今,经过预训练的Xception模型已经发布了,各个团队可以通过微调更快地实现自己的模型。
例如,伊利诺伊大学和阿贡国家实验室的一个团队最近训练了一个模型,将星系的图像分类为螺旋形或椭圆形:
尽管只有3万5千张带标签的图像数据集,但他们仍能够使用NVIDIA GPU,在短短8分钟内对Xception进行微调。
这样得到模型在GPU上运行时,能够以每分钟超过2万个星系的惊人速度,并以99.8%的成功率对星系进行分类。
当初Google花费数月在60个GPU上训练一次Xception模型时,可能他们并不在乎成本。但是,对于没有那么多预算的团队来说,训练模型是非常现实的问题。
例如,当OpenAI首次公布GPT-2的结果时,由于担心滥用,他们只发布了模型架构,却未发布完整的预训练模型。
之后,布朗大学的一个团队按照论文陈述的架构和训练过程试图重现GPT-2,并命名为OpenGPT-2。他们花了大约5万美金进行了训练,但性能仍不及GPT-2。
5万美金的投入却未能训练出性能过关的模型,对于没有充裕资金的生产软件团队来说都是巨大的风险。
当初Nick Walton构建AI Dungeon时,他对GPT-2进行了微调。OpenAI已经投入了大约27,118,520页文本和数千美元来训练模型,所以Walton坐享其成就可以了。
他使用了一个非常小的来自choiceyourstory.com的文本集,并对Google Colab的模型(该模型完全免费)进行了微调。
回顾软件工程,我们会发现生态系统的“成熟”过程通常都有极其相似的模式。
首先是一门新语言的出现
,而且还拥有令人兴奋的功能,然后人们将这门语言用于某些特别的场景,或者用于研究项目和业余爱好。在这个阶段,任何使用这门语言的人都必须从零开始构建所有的基础实用程序。
接下来,社区会开发库和项目,将常见的实用程序抽象化,直到这些工具的功能足够强大,足够稳定,能用于生产。
在这个阶段,使用这门语言来构建软件的工程师不必再担心发送HTTP请求或连接到数据库等问题(所有这些都已被抽象化),只需专心构建产品即可。
换句话说,Facebook构建React,Google构建Angular,而工程师们则可以利用这些框架来构建产品。而这一过程在机器学习中就是迁移学习。
随着OpenAI、Google、Facebook和其他科技巨头发布强大的开源模型
,面向机器学习工程师的“工具”会越来越强大,越来越稳定。
机器学习工程师不再需要花时间使用PyTorch或TensorFlow从头开始构建模型,他们可以利用开源模型并通过迁移学习来构建产品。
机器学习软件的新时代即将到来。如今,机器学习工程师只需专心思考如何将这些模型投入生产。
原文:https://towardsdatascience.com/deep-learning-isnt-hard-anymore-26db0d4749d7
作者:Caleb Kaiser,创始团队成员@Cortex Labs。
【End】
以上是关于“深度学习一点也不难!”的主要内容,如果未能解决你的问题,请参考以下文章
深度学习入门好文,强烈推荐! ! !
深度学习“深度学习”-概念篇
什么是深度学习?深度学习能用来做什么?
深度学习入门 2022 最新版 深度学习简介
深度学习简介
深度学习之一:神经网络与深度学习