R语言再保险合同定价案例研究
Posted 拓端数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言再保险合同定价案例研究相关的知识,希望对你有一定的参考价值。
原文链接:http://tecdat.cn/?p=13617
再保险案例研究目的是为业务中断索赔定价一些非比例再保险合同。考虑以下数据集,
> db=read.xls(+ "PE.xls",+ sheet=1)Content type 'application/vnd.ms-excel' length 183808 bytes (179 Kb)open URL==================================================downloaded 179 Kb
至于任何(标准)保险合同,定价中有两个部分
预期的索赔数量
个人索赔的平均费用
在这里,我们没有协变量(但是可以使用某些变量,例如行业的种类,地理位置等)。
让我们从每年的预期索赔数开始。这是每天的频率
是很久以前的数据,但是,这也是一件好事,因为十年后,我们可以预期大多数索赔已经解决。为了绘制上面的图,我们使用
> date=db$DSUR> D=as.Date(as.character(date),format="%Y%m%d")> vD=seq(min(D),max(D),by=1)> sD=table(D)> d1=as.Date(names(sD))> d2=vD[-which(vD%in%d1)]> vecteur.date=c(d1,d2)> vecteur.cpte=c(as.numeric(sD),rep(0,length(d2)))> base=data.frame(date=vecteur.date,cpte=vecteur.cpte)> plot(vecteur.date,vecteur.cpte,type="h",xlim=as.Date(as.character(+ c(19850101,20111231)),format="%Y%m%d"))
然后,我们可以使用(标准)Poisson回归来预测每日业务中断索赔的数量,例如,在2010年的任何一天(假设我们必须在几年前对再保险合同进行定价)
pred2010 =predict(regdate,newdata=nd2010,type="response")sum(pred2010)[1] 159.4757
观察使用旧数据有弊端,因为如果我们按时进行回归(包括一些可能的趋势),我们将面临更多不确定性。
假设我们在给定的一年中平均有160项声明。
plot(D,db$COUTSIN,type="h")
现在让我们集中讨论这些索赔的费用。我们的数据集中有2,400个索赔要求适合模型(或至少估计了再保险合同可能给我们造成的损失)。假设我们想为我们的大额索赔购买再保险合同。在16年的时间里,该可执行文件的费用应接近1500万。
quantile(db$COUTSIN,1-32/2400)/1e698.66667%15.34579abline(h=quantile(db$COUTSIN,1-32/2400),col="blue")
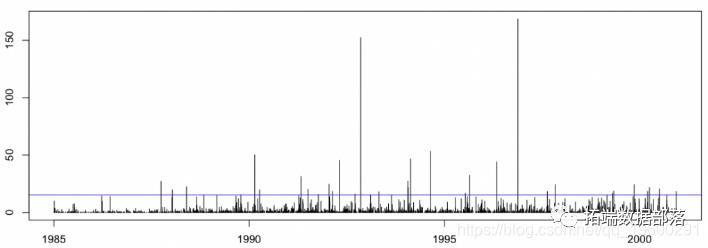
因此,考虑一些免赔额为1500万的再保险合同。让我们假设再保险公司同意这种免赔额,但承保范围为3500万。
第一个想法是查看我们投资组合中的第一个成本,即该赔偿的经验平均值。
检查一些损失
> indemn(5)[1] 0indemn(20)[1] 5indemn(50)[1] 35
现在,如果计算再保险公司在16年内的平均还款额,
mean(indemn(db$COUTSIN/1e6))[1] 0.1624292
因此,根据索赔,再保险公司将平均支付162,430。每年有160项索赔,纯保费应接近2600万
mean(indemn(db$COUTSIN/1e6))*160[1] 25.98867
(同样,对于3,500万份保险,平均每年应发生两次的某些索赔)。正如我们看到的,再保险的标准模型是帕累托分布(或更具体地说,是广义帕累托分布),
这里有三个参数
阈值(我们将其视为固定阈值,但会看到其对再保险定价的影响)
比例参数
尾部指数
策略是考虑一个低于我们免赔额的门槛,例如1200万。然后,假设损失超过1200万,我们就可以拟合广义Pareto分布,
> gpd.PLxi beta7.004147e-01 4.400115e+06
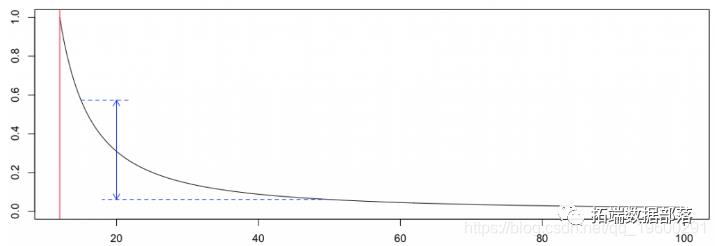
在这里,鉴于索赔超过1200万,平均还款额接近600万
> E(15e6,50e6,gpd.PL[1],gpd.PL[2],12e6)[1] 6058125
现在,我们必须考虑达到1200万的概率
mean(db$COUTSIN>12e6)[1] 0.02639296
因此,如果总结一下,我们每年平均有160项索赔
> p[1] 159.4757
只有2.6%将超过1200万
mean(db$COUTSIN>12e6)[1] 0.02639296
因此,每年发生1200万以上的频率为4.2
p*mean(db$COUTSIN>12e6)[1] 4.209036
对于超过1200万的索赔,平均还款额为
> E(15e6,50e6,gpd.PL[1],gpd.PL[2],12e6)[1] 6058125
因此,纯溢价应接近
p*mean(db$COUTSIN>12e6)*E(15e6,50e6,gpd.PL[1],gpd.PL[2],12e6)[1] 25498867
接近我们获得的经验值。实际上,也可以查看阈值参数的影响,很明显,中间值可以更改。
我们可以将纯溢价绘制为该阈值的函数,
> seuils=seq(1e6,15e6,by=1e6)> plot(seuils,Vectorize(esp)(seuils),type="b",col="red")
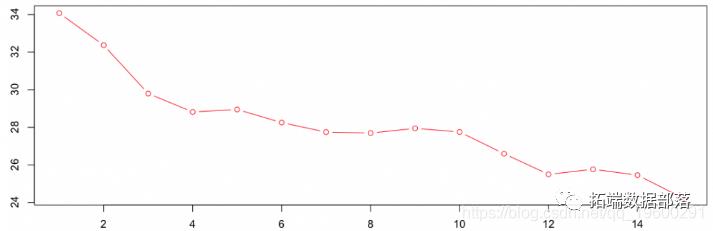
对于较大的阈值,该值在24到26之间。同样,这是第一步,我们可以为更高的再保险层定价,例如可抵扣额为5000万的再保险合同(我们之前有低于该门槛的索赔的再保险合同),而承保额为5000万。拥有参数模型变得有趣,该模型应该比经验平均值更健壮。
点击标题查阅往期内容
更多内容,请点击左下角“阅读原文”查看报告全文


![]()
案例精选、技术干货 第一时间与您分享
长按二维码加关注
更多内容,请点击左下角“阅读原文”查看报告全文
以上是关于R语言再保险合同定价案例研究的主要内容,如果未能解决你的问题,请参考以下文章