利用文本挖掘提高Airbnb收益预测的精确度,我们得到了这样一个结论
Posted 大数据应用
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用文本挖掘提高Airbnb收益预测的精确度,我们得到了这样一个结论相关的知识,希望对你有一定的参考价值。
原文链接:https://towardsdatascience.com/improving-airbnb-yield-prediction-with-text-mining-9472c0181731
翻译:Cindy 秦昕
简介
Airbnb是一个广受欢迎的全球民宿预订平台。对于房东而言,把闲置的度假房屋、房间甚至是床位出租来赢得额外的收入,是一个何乐而不为的选择。然而,新加入的房东很难知道他们能够从中赚取多少收益。他们也不清楚自己精心设计和装饰的房子,和普通的租房相比,究竟价值几何。
要帮助房东解决这一问题,我们可以通过建模来预测Airbnb listing的潜在收益。这一模型考虑加入描述性文本来得到一个更丰富、定性的listing模型。我们选取伦敦Airbnb为分析对象。
具体的分析和代码请参考:
https://github.com/joaeechew/udacity_capstone
本文用四个部分来解释文本挖掘如何帮助我们更准确地预测Airbnb的收益。
数据探索:关于数据集和描述性观点的探讨
文本挖掘:语料库分析和主题模型
训练机器学习模型:特征工程、模型选择和调整
结论和可视化:文本数据可视化和一些结论
1
数据获取
为了创建这一模型,我们使用Inside Airbnb( http://insideairbnb.com/get-the-data.html) 上的数据集。该数据集包括了详细的listing信息,例如房间数(no. of rooms)、位置(location)、文本描述(text description)、价格(price)、评价数(no. of reviews)等。

数据集样本
我们特别选取2016.10.03-2017.03.04这段时间详细的伦敦listing数据。一个有效的listing的定义是在这个时间段内该租房至少得到过一次评价。其余的listings都被移除。清理之后的数据集包括9722行和16列数据。
2
如何衡量潜在的收益
建立这一模型我们还需要定义一个概念Yield,代表可能的未来收益。我们把Yield定义为该租房一整年获得的收入。我们利用Inside Airbnb的‘SanFrancisco模型(http://insideairbnb.com/about.html )’来计算Yield:
平均租住时间*价格*每月评价数*评价率
在伦敦,平均租住时长是3晚。我们用一个相对保守的50%的评价率来将评价数转化为估计的订单量。
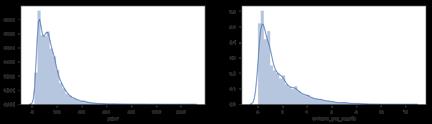
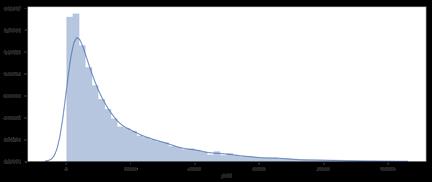
价格、每月评价量、年收益Yield的分布图
通过分析价格、评价量和最终yield的分布,大部分伦敦的listings都低于100英镑/晚,且月订单量的范围在1-4。这显示出当租住率在10%-50%(取决于选中的评价率)时,Airbnb上平均每个listing年收入为15739英镑。若是排名前1/4 的listings,这个数字能上升到21480。事实上,伦敦市中心的中等水平的租金是7800英镑,这说明了如果Airbnb listings得到有效的管理,租金的溢价将十分可观。
现在我们得到了处理之后的数据集,接下来我们要将描述文本转变成适用于机器学习模型的数据类型。
listings描述的样本
在自然语言处理(NLP)中,描述文本的集合通常被称作语料库(corpus)。这个集合被转化成一个文档-词条矩阵(document-termmatrix),在这个矩阵中,每个listing都是作为一个含有词条矩阵的文档。使用NLTK和gensim包可以做到这一点。
为了减少词语的数量并专注于每个文档有价值的点,我们去除非英语和停用词(stopwords)。这些词被词形还原,并且用RegEx 分割器(tokenizer)忽略掉非字母数字的字符串。剩下的词被转化成一个文档-词条矩阵的表达词袋(alist of word_id, word_frequency 2-tuples)。
接着我们用隐含狄利克雷分布LDA(Latent Dirichletallocation)来探索语料库中的主题,根据主题对语料库进行分类,并应用到回归模型当中。
(隐含狄利克雷分布简称LDA(Latent Dirichletallocation),是一种主题模型,它可以将文档集中的每篇文档主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。)
下图显示的是使用pyLDAvis包可视化后的主题模型。在图中,圆圈的范围表示的是每个主题的受欢迎的程度,而右侧条形的长度代表一个特定主题里的词条比例。例如,主题1是最受欢迎的主题,在主题1中,“walk”是估计出的最受欢迎的词条(红色部分)。
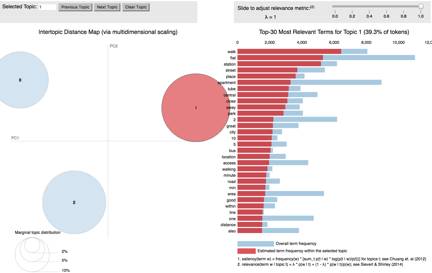
https://cdn.rawgit.com/joaeechew/udacity_capstone/481e85b0/lda.html
我们将文档词条聚类为3个主题,每个主题之间不存在重合,这便于对每个listing进行分类。依据每个主题中出现最多的词条,listings的主题可以被分类为:
主题1——位置(location):关注带有“location”、“walk”、“station”和“central”等词条的地理位置。关注地理位置的交通便利程度的游客会被主题1吸引。
主题2——奢华程度(luxury): 关注带有“kitchen”、“modern”、“private”和“space”等词条的现代公寓。主题2对于预算较高的、关注空间舒适度和私密性(在伦敦通常价格昂贵)的游客更具吸引力。
主题3——预算(budget):关注“bed”、“room”、“shower”和“clean”等词条。预算一般只需要解决基本住宿的游客可能更关注主题3。
在这里,每个listing将被归类到一个确定的主题之下。
这一部分,我们将利用处理之后的数据集训练机器学习算法。我们可以了解预测收益的最终模型是如何建立的。
1
误差度量
误差度量可以指导算法中的权重设置,使得模型达到一个误差最小的最优预测函数。
这里我们使用均方误差(mean squared error,MSE)来衡量模型的精确性。均方误差计算的是预测收益和实际收益之间的误差平方的平均数。其数学公式如下:
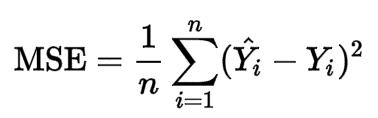
通常我们使用均方误差来衡量回归模型的的误差。举例来说,10000的均方误差表明收益模型存在100(10000的平方根)英镑的误差。均方误差一般是非负数,值越接近零,说明模型越准确。
2
模型选择
有了明确的误差度量,我们可以训练多个模型,最终选择表现最好的一个。通过训练和测试每个模型,我们可以来检测一下是否越复杂的模型,预测的误差越小。
以下模型复杂度由小到大:
A. 线性回归:用简单的线性方法模拟数据集中的变量(如房间数、入住人数)和因变量“收益Yield”之间的关系。
B. 决策树:用更复杂的模型来模拟非线性关系。在树的结构当中,每个内部节点对应数据集中的一个对象(如房间数),每个叶子节点表示对象的值(如大于2间房)。
C. 随机森林:随机森林是建立在多个决策树基础上的更复杂的模型。随机森林是一组独立的决策树的集合,因此其学习的能力更强。独立的决策树由事件和对象的随机样本组成,最终返回森林的结果是组合预测的平均值。
正如我们所预测的,随即森林的均方误差最小。这表明我们的数据集存在众多非线性关系,只能通过更复杂的模型来描述。
3
特征工程与LDA主题模型
尽管我们成功使用结构化数据建立起一个预测模型,我们的最终目的是探索文本挖掘是否能够帮助提高对收益预测的精确度。我们通过比较含有和不含listing主题的模型的误差大小,来验证这一点。
当不考虑listing主题时,得到的最好结果是均方根误差(root MSE)等于14579英镑。而考虑描述性主题时,得到的最小的均方根误差降低到14560英镑。确认考虑listing主题会提高预测精确度之后,我们使用scikit-learn的GridSearchCV调整最终参数,均方根误差进一步下降到14250英镑。
尽管看上去精确度没有增加多少,但我们要知道的是,随着精确度的增加,想要剔除误差会越来越困难。
更重要的是我们的假设得到了验证,即文本挖掘能够提供有价值的信息,同时也提示我们可以进一步探索NLP来获取这些信息。
使用树类模型的另一个好处是我们能够看到数据集中每个对象的重要程度。这也显示出了使用listing主题的价值。

Listing模型中所有主题的重要程度加总为2.5%——大于租房类型、床位数、床型的重要程度(分别为1.3%,1.8%,0.11%)。这表明非结构化的描述性文本包含的信息要多于Airbnblisting的仅结构化数据包含的信息, 而这些信息可以用NLP技术来对其进行挖掘。
除了提高预测能力,Airbnb listing描述的文本挖掘还提供了更深层的结论。我们构造一个关于location、luxury、budget3个主题的气泡图,可以将伦敦Airbnb的市场划分为不同种类的listings,每种listing有着不同的均价和预订率。
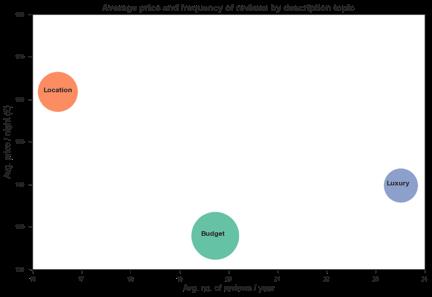
每个主题根据划分部分的平均数来绘制,气泡的大小代表listing的数量
根据气泡大小,“budget”部分listing的数量最大,随后是“location”和“luxury”。这点是合理的,因为“budget”类的listing总是更受青睐。
如果看平均价格,“location”以162英镑居首,随后是“luxury”的140英镑和“budget”的128英镑。这表明地理位置依然是租房市场的重中之重。
有趣的一点是,尽管好的位置有着最高的均价,“luxury”主题的评价数却最多。正如前面所述,评价数是订单率的代表,说明有“luxury”主题的listing可能获得高于平均的收益。
Airbnb的客户主要群体是喜欢旅行的千禧一代,他们更喜欢选择特别的租房。这也许能解释为何Airbnb上的“luxury”主题如此受欢迎。而那些更关注“location”的商业旅客倾向住在旅馆,以及关注“budget”的旅客倾向于选择有基本设施和更低价格的旅馆。
总结:
NLP可以挖掘非结构化文本中的信息,而文本挖掘能够释放很多有价值的信息。正如上面的主题模型不仅能够提高对收益预测的精确度,还引出关于Airbnb市场的不同部分的有趣结论。
非结构化数据为更好的数据分析打开了大门。除了描述文本数据,下一步,我们还可以关注Airbnb上的图像数据,并探索如何通过深度学习算法从中提取更多有用的信息。
您或许还想看看



点击“阅读原文”查看数据应用学院核心课程
以上是关于利用文本挖掘提高Airbnb收益预测的精确度,我们得到了这样一个结论的主要内容,如果未能解决你的问题,请参考以下文章