R语言之文本挖掘--分词
Posted 人工智能爱好者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言之文本挖掘--分词相关的知识,希望对你有一定的参考价值。
4月20日Sim老师在Hellobi Live直播授课《手把手教你做文本处理》,阅读全文课报名。老司机带你快速上手文本处理!
当前对文本挖掘的需求越来越多,而基于文本挖掘又可以实现舆情监控、文本分类、关联分析和趋势预测等。
本文主要使用李舰发布的中文分词包Rwordseg。该包引用了@ansj开发的ansj中文分词工具,基于中科院的ictclas中文分词算法,无论是分词准确度、自定义词典的方便程度还是运行的效率都大大地超过了rmmseg4j。该包使用rJava调用Java分词工具Ansj,因此需要进行rJava的设置才可以使用。
文中使用到Rwordseg包和tmcn包,这两个包目前不在R的镜像中,可以通过如下两种方式获得这两个包。
1、通过R语言本身获得,详细步骤见下图:
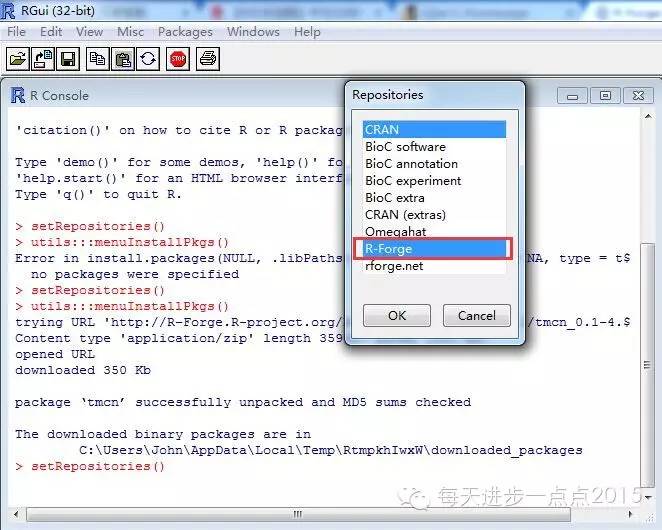
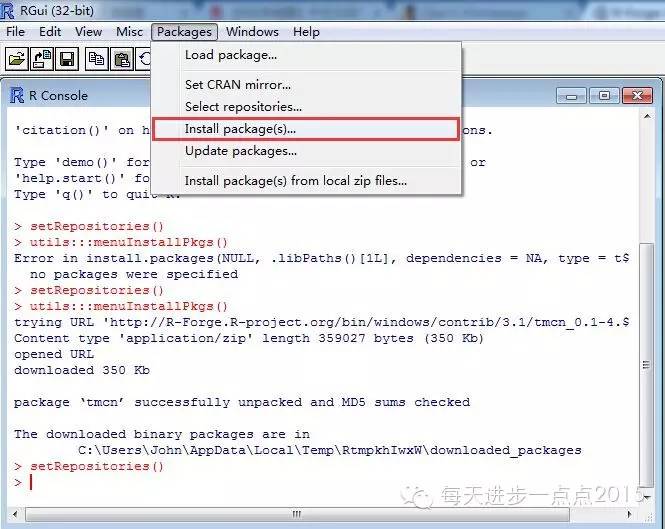
https://r-forge.r-project.org/R/?group_id=1054
https://r-forge.r-project.org/R/?group_id=1571
应用:
本文分析的对象为一篇新闻,来源于环球网的《习近平出席中美企业家座谈会》这篇文章,看看习大大这次访美都有哪些动向?
本文主要对这篇文章做如下两个工作:分词和绘制文字云。
#读取数据
news <- readLines('news.txt', encoding = 'UTF-8')
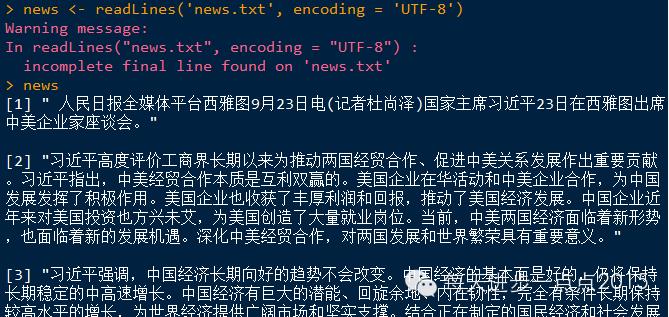
由于Rwordseg包中的segmentCN函数对某些词无法准确分词,需要自定义字典、指定人名识别及指定停止词。
#首先将台湾大学定义的字典导入到系统中,该字典中含有正面及负面的简体词和繁体词共22173个。
data(NTUSD)
positive_simple <- NTUSD[[1]]
negtive_simple <- NTUSD[[2]]
positive_tradition <- NTUSD[[3]]
negtive_tradition <- NTUSD[[4]]
insertWords(positive_simple)
insertWords(negtive_simple)
insertWords(positive_tradition)
insertWords(negtive_tradition)
#其次将自定义的词导入系统
dir <- c('中美','两国','阿里巴巴','改革开放','腾讯','微软',
'双汇','亚马逊','星巴克','企业家','发展中','中国梦')
insertWords(dir)
#再者还需要指定人名识别

发现默认情况下,segmentCN函数并没有识别人名。
将人名识别设为TURE后,发现能够将名字准确分割出来。
#最后为分词函数segmentCN指定停止词,这样就不会把这些词识别为有效词
stopwords <- c('大','上','高','好','中','新','更','梦')
stopword <- stopwordsCN(stopwords = stopwords, useStopDic = TRUE)
当然这些准备工作是在探索文本内容的基础上完成的,这里只是想说明一下本文的思路。
使用segmentCN函数看一下分词效果:

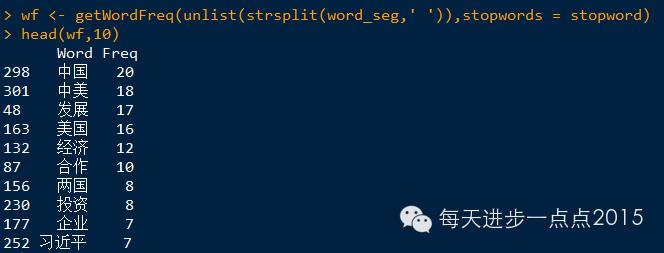
词频分析
绘制文字云
从图中发现,本次习总书记访问美国,仍然强调的是中美之间的经济发展问题。
由于工作需要,自己刚开始研究文本挖掘,本文只是做了个文本的分词,关于文本挖掘还有许多知识需要学习,例如文本的聚类、关联规则、预测等。接下来的日子里将和文本挖掘扯上很大的关系啦。。。。
最后总结一下本文所涉及到的R包和函数:
tm包
insertWords()
tmcn包
getWordFreq()
Rwordseg包
getOption()
segment.options()
stopwordsCN()
segmentCN()
wordcloud包
wordcloud()
以上是关于R语言之文本挖掘--分词的主要内容,如果未能解决你的问题,请参考以下文章