法学∣舒洪水:司法大数据文本挖掘与量刑预测模型的研究
Posted 华政法学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了法学∣舒洪水:司法大数据文本挖掘与量刑预测模型的研究相关的知识,希望对你有一定的参考价值。
作者单位:西北政法大学反恐怖主义法学院
责任编辑:于改之
全文已略去注释,如需查看,请订阅《法学》
【内容摘要】 大数据时代,计算机数据正以海量速度增长,尤其是非结构化的文字数据最为惊人。利用自动化文本挖掘技术处理非结构化数据,获得有价值的预测或趋势信息,已成为近年来的热门议题。法院判决书是典型的非结构化数据,本研究以中国裁判文书网毒品判决书为文本挖掘对象,利用TF-IDF、N-Gram、关联性分析及CRISP-DM等技术方法,对388份判决书进行自动化分类及数据化转换,并利用统计线性回归方法,实时分析法院判决数据,建构出量刑预测模型。经评估后发现,本研究所提出的判决分类及量刑预测模型均有良好的预测能力。本研究所提出的判决书文本挖掘流程与自动化模型架构,未来可以为司法大数据应用提供参考。
【关键词】 大数据 判决书 文本挖掘 统计回归 量刑预测模型
大数据时代,数据正以前所未有的速度生成,海量数据资源由此产生。大数据资源日渐成为国家与社会的基础性战略资源,推动世界大步迈向数据时代。如何挖掘与运用瞬息万变的海量数据,将它变为对人类社会有用的信息,是当前各行业的关注焦点。数据挖掘(Data Mining)与文本挖掘(Text Mining)是两门处理大数据的关键技术,数据挖掘是处理结构性数据的技术,而文本挖掘是处理非结构性数据的技术。目前,国外大数据技术在犯罪侦查、司法量刑等实务运用方面十分活跃,主要集中在网络毒品犯罪侦查、量刑差异分析、文章作者识别以及量刑指导等方面。
(一)网络毒品犯罪侦查及量刑预测
加拿大贩毒集团通过Caviar Network网站进行海洛因及可卡因等毒品交易,由于案情错综复杂,警方利用数据挖掘技术建构了一套犯罪侦查及量刑预测系统,并运用该系统挖掘了网站信息,形成了贩毒集团的通信流程图(图1)。该图共有110个点,分为红色及蓝色两种,红点是经系统判定有罪的人,点跟点之间通过方向线连接,表示贩毒集团成员之间的网络联络关系,该图同步显示了犯罪集团的核心及首脑人物,这样的一个网络联络图,具有预测贩毒集团成员是否有罪及量刑预测功能。
该系统设定了九种变量作为指标,用来计算贩毒集团成员间与犯罪网络核心的入出分支度与距离远近,然后使用多元线性回归模型作为量刑预测,以Logistic回归分析来预测是否有罪,最后以法院宣判结果验证模型是否准确有效。结果显示,该系统建构网络联络图及方法,进行犯罪侦查及量刑预测模型有效。
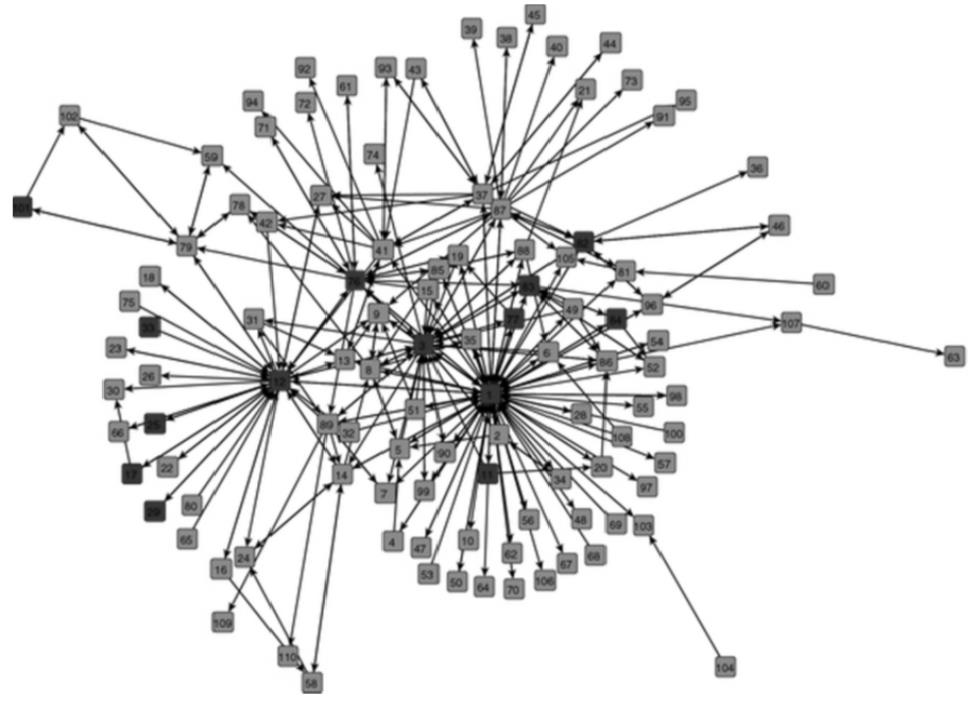
图1 Caviar的网络通信架构图(红点表示犯罪嫌疑人)
(二)不同种族量刑差异分析
2015年,阿德谷(Adegun)通过统计回归分析了毒品被告的不同种族身份是否会影响法院量刑。数据集来源于美国量刑委员会(The United States Sentencing Commission)的联邦量刑监督部门(Monitoring of Federal Sentencing),数据分析发现,来自亚洲、加勒比海、欧洲、中东、北非、南亚和中美洲地区等国家的被告量刑,比墨西哥被告严厉。然而,结合被告国籍、性别与年龄等非法律相关控制变量观察,发现墨西哥被告被判决的刑度反而比加拿大被告来得重。从联邦量刑数据库统计数据发现,法官量刑时基于避免社区罪犯的安全考量,及其假定少数民族所带来的威胁,墨西哥裔的罪犯获判较重。该研究利用三种统计线性回归模型进行分析,以各地区种族、毒品种类等不同变量,观察刑度反应变量后发现,法院在量刑时的确有不同的对待方式。
(三)文章作者识别
以文本挖掘方式建立作家风格(Writing Style)的特征值,是用来区分不同作者写作方式的一种方法。每个人的写作风格都有其独特性,通过作家风格特征值对语料库进行分类及特征抽取,就如生物的行为特征一样,当文本无人宣称所有及有争议时,用来确认判别谁是真正作者。通过分析与计算文本特征,并建构出特征档案法,将文字与作者关系加以关联,是判别文章作者的依据。
从机器学习角度看,文章作者识别问题可以看作一个多类单标签文本分类的难题。一般情况下,作者识别任务包括作者身份验证、抄袭检测、作者分析、作者识别、文体不一致检测等内容,同时,文章作者识别在实时通信犯罪证据分析、法院鉴识犯罪嫌疑人的非供述证据、程序原始码的原创者以及人工智能型代理人(Chat-bots)等方面都有应用。通过Byte Level N-Gram Term Frequency Inverse Token Frequency(BLN-Gram-TF-1TF)对一组图书进行作者识别,与JGAAP方式做比较,可获得较高的正确率。实验中发现,当使用K丽与特征值做档案字数超过300字的分类判断时,准确率可达到96.7%,当N-Gram的N=5时,对于小档案及大档案有较高的准确率,N=3或N=4时,对于档案大小为400~600字有较高的准确率。
(四)美国量刑指导
七十年代,美国法官的量刑有极大的裁量权,法官因个人喜好及种族歧视等因素影响,造成严重量刑不公的现象普遍存在。由于量刑不公而引发的相关问题越来越严重,1984年美国国会通过量刑改革法,授权成立联邦量刑委员会,负责制定联邦量刑指导法则(Federal Sentencing Guidelines),通过量刑标准减少法官类同案件科刑歧异情形,并实现罪刑均衡原则。
美国量刑指导法则长达一千多页,对各种犯罪的量刑规定非常细致。法官在案件审理中以量刑表(表1)为依据,每种罪名均有一个基础犯罪级数(Base Offense Level),犯罪级数共43级,法官可根据该表,依被告犯罪事实调整犯罪级数。其中,在量刑时必须参考被告前科纪录,计算前科级数(共6级),将犯罪级数与前科级数在量刑表中交集后,得到一个刑期方格,法官便可得出被告量刑范围。法官原则上仅能于该范围中加以量刑,而依据量刑改革法要求,每格最高法定刑不得高于最低法定刑度的25%或6个月,以避免同一格内的案件量刑差异过大。以诈欺罪的犯罪级数x计算为例,在量刑指导法则中规定诈欺罪的基础犯罪级数为6级,依据被害人财物损失金额(表2)调整级数。
表1 美国量刑表
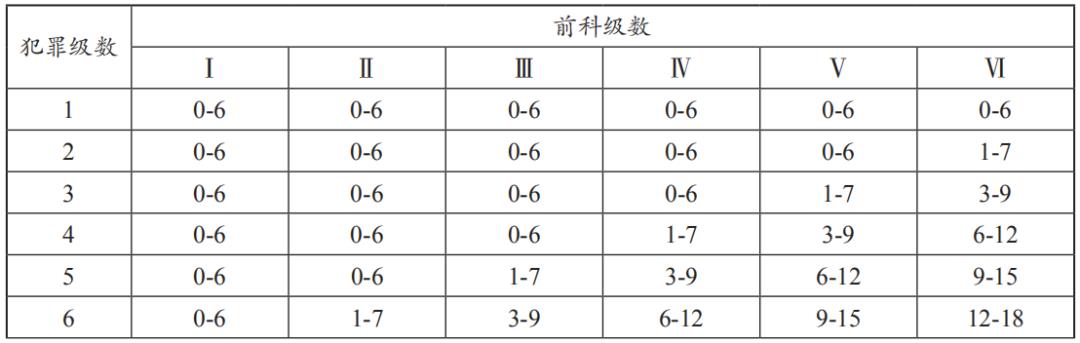
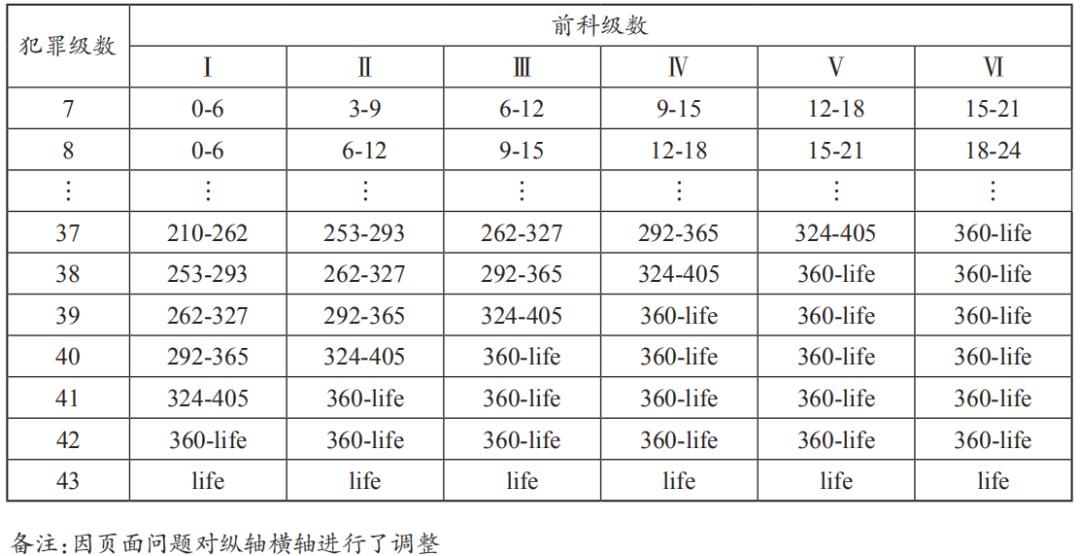
美国量刑指导法则不仅详列法官量刑过程中应审酌事项,并决定每一事项加减级数,法官必须依据该指导法则计算刑期,增加了科刑的可预测性及公平性,原有法官的自由裁量权受到制约。量刑指导法则的优点在于规范所有犯罪的基本级数与应予以加减级数,使法官有较明确、客观的处罚标准,在此制度之下,量刑成为一件非常科学及精密的工作,彻底解决了量刑不公问题。
表2 依据被害人财物损失金额增加级数表
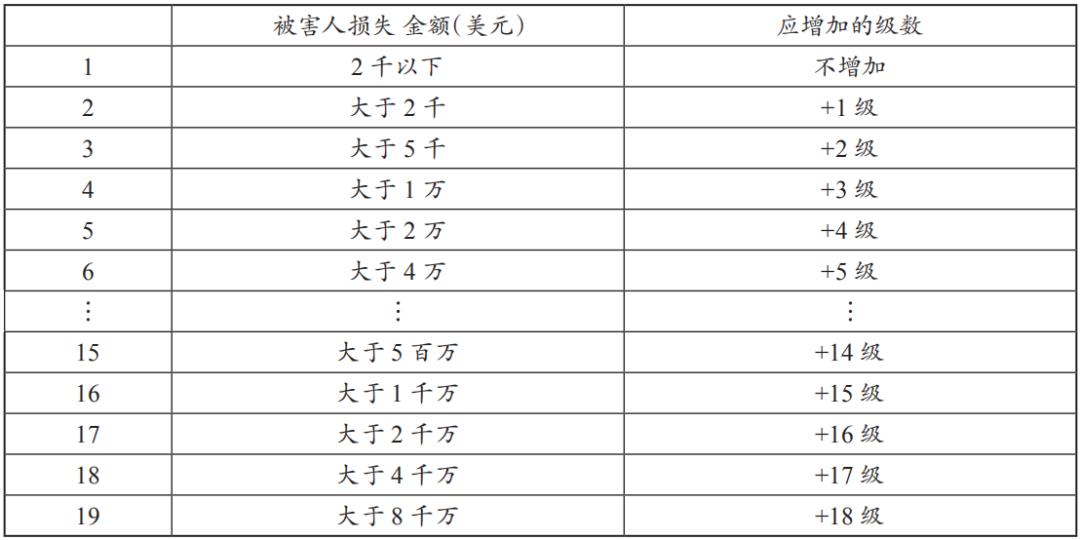
在我国刑事审判活动中,从最高人民法院的指导性案例到《量刑指导意见》,虽有诸多关于对量刑的相关规定,但是存在一定缺陷,比如,主观随意性较大并且操作性较差。美国的量刑规定则较具体、细致、操作性强。从20世纪80年代开始,我国学者们就对量刑理论等问题陆续进行了研究,也出版了不少著作,如邱兴隆、许章润合著的《刑罚学》和胡学相的《量刑的基本理论研究》,但是运用机器学习、文本挖掘技术在司法大数据及其量刑预测相关研究上则是空白。
最高人民法院从2013年起开通了裁判文书网,公开了几乎全部司法判决文书,给我国犯罪侦查、量刑指导等领域提供了海量数据支撑。但是,国内对于司法大数据的实践性运用还相对有限,在一定程度上呈现出“话语热、实践冷”的现象。一方面,应用主体范围有限,主要集中在少数司法机关、司法数据公司;另一方面,应用领域相对较窄、实际运用较少,主要集中在类案检索、法律文书草拟、文书智能纠错等辅助办案方面。尽管部分司法数据研究已经开始使用爬虫软件等抓取数据,但内容分析仍以描述性数据分析为主。除了学者白建军偶尔运用统计方法进行司法数据分析外,基本见不到运用大数据技术或者统计方法进行司法数据分析。因此,通过司法数据挖掘结合统计方法进行的精确定量分析,获得有价值的量刑预测或趋势信息,是当前司法大数据领域迫在眉睫之事宜。
国家禁毒办发布的《2017年中国毒品形势报告》显示,2017年全国禁毒部门破获毒品刑事案件14万起,我国当下正面临着极为严峻的打击贩毒犯罪的紧迫形势。本研究以裁判文书网的贩卖毒品罪判决书为挖掘对象,依据CRISP-DM文本挖掘流程,在中文断词技术(N-Gram)去除多余虚词基础上,运用关键字词权重分析(TF-1DF)及关联性分析法则进行判决书分类及数据转换,再以神经网络与线性回归方法比较建模结果,并将训练数据以相关分析及回归分析来建立量刑预测模型,最后以测试数据集验证模型预测结果是否准确。
二、研究设计与技术背景
(一)研究流程与技术架构
本研究数据挖掘流程及技术方法如图2所示。

图2 研究流程与技术架图
(二)技术背景
1.文本挖掘
数据挖掘及文本挖掘是大数据处理的关键技术。数据挖掘的基础是数值形态的数据,也适用于文字类型的叙述式数据,相对于文本挖掘,数据挖掘具有显著的结构化,例如有规律的表格或数据库;而文本挖掘是没有任何规则、内容长短不一、毫无定义的文字数据,它可以是我们日常生活中的语言,或者是网络文字,因此,文本挖掘是一种对文字和其他非结构化数据的分析过程。
文本挖掘的关键,是将隐藏于文字间的信息切割成可被计算机处理的独立信息单元(断词),其中包括同义字的确认。现有文本挖掘软件中,通常包含了一个同义字库,用来确认同义但不同字的同义字,可被切割出并转换成同一可处理的信息单位。进行文本挖掘之前,必须运用程序来剔除文件中不具有分析价值的文字,然后才可以运用挖掘工具进行分析工作。具有同义字库的文本挖掘软件常被称为具有辨认关键词能力,可用以辨认文章上下文间的语意,进而确认出文字间的关联关系,再运用算法,挖掘出大量文字中所呈现的特殊样式或重要的关联规则。
在大数据技术中,非结构性的文本挖掘比结构化的数据挖掘更具有挑战性,从文字中可以挖掘到人类行为模式的相关知识。近年来,文本挖掘已在信息检索、自动摘要、自动分类、自动归类、关联分析等领域上广泛应用,利用文本挖掘技术进行文件分类并将其用于量刑预测,已逐渐成为一门显学。因此,若能将文本挖掘技术应用到数量庞大的司法文书范畴,对各种电子文书数据进行犯罪侦查及趋势预测,对司法刑事案件的调查、侦查及审判等,将有意想不到的帮助。
2.自动化文件分类
由于计算机不具备人类阅读文件的能力,所以我们必须将文件整理成系统可分析的结构化格式,把文件中非结构化的句子分割成许多字词,再用这些字词做进一步的分析,这就是特征值的选取过程;其次,在机器学习部分,利用已知类别的文件训练数据进行监督式学习,使分类技术能够自动学习文件分类的经验与知识,经训练后归纳出文件分类规则,最后将未知类别的文件当成测试数据,让系统以学习到的规则进行自动化文件分类。
自动化文件分类通常可分为两个步骤:一是目标文件特征值选取,二是利用机器学习进行文件自动化分类。传统文件分类的做法是以人工方式来进行,因该方法主观且毫无效率,所以Joachims认为通过分类技术去学习固有的文件范例,再进行文件分类是比较有效率的方法。而自动化文件分类的概念,即是利用机器学习中的监督式学习方法,从已知类别的文件数据集中加以归纳出分类规则模式,再依据分类模型,给予新文件合适的类别标签。
在文件分类中,多数是使用特征字词所形成的“特征向量模式”表达文件,基因算法是近年来使用较多的方法,而“字库法”则是最常被用以表示文档属性的方法之一,但是该方法容易导致文件的特征维度高,对于分类算法来说,处理这类数据阻碍很大,这种现象叫“维度灾难(Curse of Dimensionality)”。当文件维度增加后,首先,想要找到所有可能属性组合的困难度与所需要的时间将会大幅提高,整个数据空间的指数复杂度增加;其次,高维度的文件数据中,多数特征对于分类并没有帮助,甚至对于分类算法而言反而成为一种杂音,容易导致分类错误。因此,我们必须从原始文件中选取出部分关键字词集合进行特征维度的缩减,进而改善分类算法的效能。
以往许多学者采用各种特征选取方法进行文件分类,多数是以统计方法为基础计算字词出现频率来进行筛选,具体有:文件频率(Document Frequency, DF)、信息获利率(Information Gain, IG)、交互信息(Mutual Information, MI)以及卡方统计量(CHI)等。本研究将利用关联性法则分析判决书中的重要关键字词,用来分类不同贩卖毒品罪判决书的特征值,以作为程序自动分类学习与测试条件。
(三)研究方法
1.文本挖掘中的断词技术
词是最小的有意义且可以自由使用的语言单位。任何语言处理的系统都必须先能分辨文本中的词才能进行下一步的处理,因此,中文自动分词(又称断词技术)工作成了语言处理不可或缺的技术。断词技术可区分为词库法与非词库法(表3):非词库法(Non-Word based)是针对大量的语料库进行文件内容分割,所分字词出现次数若高于门坎值,则认定为一个独立词汇,在辨识新词上,不受传统词库法限制,代表方法为N-Gram;词库法(Word based)则是通过事先建构好的词库,对文件逐字逐行比对,并判断出其所包含的词汇。
表3 词库法与非词库法优缺点比较
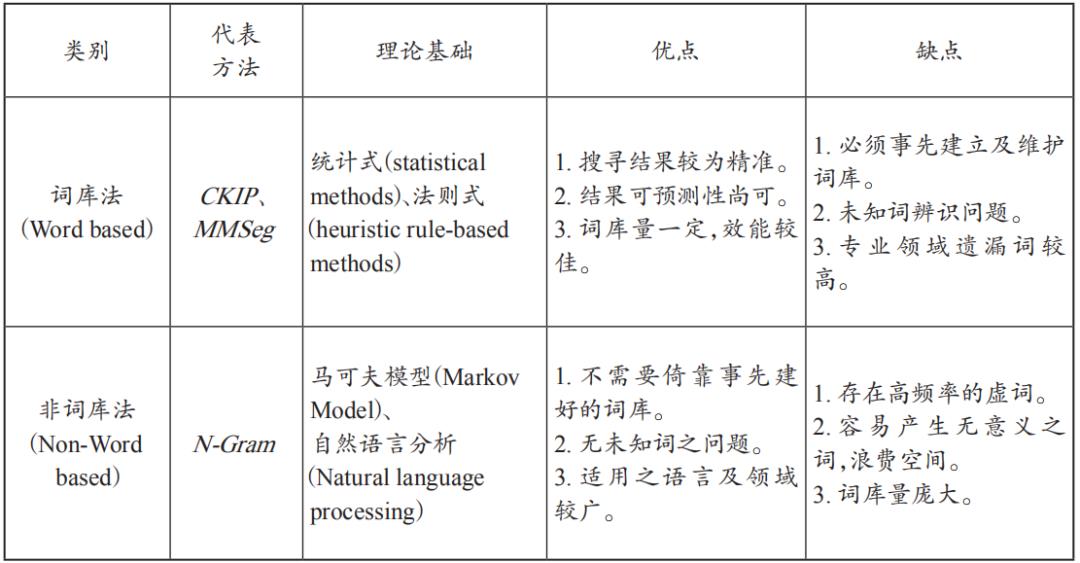
以统计方法断词需通过大量文件或语料库的训练,非词库法(N-Gram)需要取得足够词频的字词,适合大量数据的处理,无须学科专家事先定义词汇,可有效解决词库在撷取复合名词、专有名词及新生词汇的问题。N-Gram模型的主要特点是可以用来观察字词所出现概率,以机械方式反复切割出以N个字为单位的字符串,再从其中找出字词,搜索引擎Google便是以N-Gram为其主要的算法。
N-Gram用于自然语言分析时,其前提是每一个单字皆与前一个单字相关,属于N-1的马可夫模型(Markov Model)。如当N=1时称为uni-gram;N=2时则称为bi-gram;N=3时则称为tri-gram,大于3之后或同时存在多种组合的皆可直接称为N-Gram。若采用bi-gram对于未知词的切割,如“有期徒刑”这样的字词可分别切割为“有期”“期徒”以及“徒刑”等索引字词。利用此算法可以找出判决书中非常重要的法律条文字词,可用以识别及确认判决书的类型及有无减轻刑期情形,对于后续统计回归分析有很大之帮助。
本研究因未事先建立专业的法律词库可供断词时使用,所以采用非词库法进行判决书断词。
2.文本挖掘中的关键字词与权重技术
因为每篇文章字词占整篇文件的重要性是不太相同的,Salton提出了字词频率(Term Frequency, TF)与逆向文件频率(Inverse Document Frequency, IDF)概念。例如“平板计算机”在信息类和科技业文件中出现频率次数较多,但是在政治类或者社会类的文件中则出现的次数较少,就算出现在政治类或社会类的文件中,其重要性也不太相同,因此,通过TF和IDF权衡字词的特征值(重要性)。
TF-IDF(Term Frequency/Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术,属统计方法的一种,用来评估文本中单一字词对于文件的重要程度。字词频率(TF)是表示某一个字词出现的次数,出现次数越多,则表示该字词的重要性越高,即表示它越具代表性。分子是指该字词在该文件中出现的次数,分母则是在该文件中所有字词出现次数之和。然而,由于字词频率的方法只求文字出现的次数,因而可能会将字词频率高但分散在多数文件中或是将字词频率少但集中在少数文件中,可能具有代表性的文字视为不具重要性的字词,因此,通常不会单独使用此指标做判断。例如:“平板计算机”在单一文章中出现20次,而文章里所有字词出现次数之和为100,所以“平板计算机”的TF值为TF=20/100=0.2。
逆向文件频率(IDF)用以计算一篇文章的关键词汇权重值,是一个用来衡量在文件分类中,字词区分能力的重要数据。例如,某一特定字词t的IDF定义为,以总文件数目N当分子,而N中有包含该字词t的文件数目n为分母,如以数学表示方法为IDF=log2(N/n)。如果包含该字词t的文件数目越少(也就是分母n越小),则IDF值越大,说明该字词t具有很好的类别区分能力。例如,文章总篇数100篇(N),其中出现“平板计算机”的篇数为10篇(n),所以IDF值为IDF=log2(100/10)=3.32。综合上述两例,“平板计算机”的TF=0.2,IDF=3.32,所以“平板计算机”在所有文章里面的权重值(TF-IDF)为TF*IDF=0.2*3.32=0.664。
因此TF-IDF是以字词频率为基础,结合文件频率的特性,将出现在少数文件中的字词,视为可能具有区隔能力的文字,利用TF-IDF的特性,有利于过滤掉常见的字词,保留重要的字词。TF-IDF的主要功用适合用来作为文件分类及辨识上作为特征字词(通常是两个以上的中文字)。一般在计算关键词权重时,大多采用词频(TF)与逆向文件频率(IDF)的乘积(TF-IDF),整理TF、IDF及TF-IDF的数学公式如下:

其中表示语料库中的文件总数,包含词语的文件数目(即文件d文件数目),如果该词语不在语料库中,就会导致分母为0,因此,一般情况下分母会使用,以避免此问题发生。
在判决书文本挖掘的过程中,会选取适当的关键字词作为判决书量刑类别分类的依据,并依据不同关键字词组合用来作为区分判决模型类别。
评估字词的重要性准则包含四种方法,与本研究相关的两种方法如下:一是关键词法,以统计方法计算词汇权重,如TF-IDF法,认为字词的重要性与在文章内出现的词频及出现的文章篇数据有相关性;其中,字词的权重与词频成正比,而与文章出现次数成反比,这也是最常使用的方式。二是位置法,考虑字词在文件中所出现位置,一篇文章最重要的部分大多位于文章的句首与句尾。一般来说,文章的重要性可以考虑字词在文章中所出现的频率以及其关键词汇所在位置,以推估其文章的重要性,因此,多采用权重计算方式。字词的权重值的多少,大多利用这些方法互相参照,然后再主观给定权重。依据A.Harris和M.Oussalah等学者的研究方法,在自动摘要初期字词处理阶段,将关联性高的句子,视为相同的句子计算权重,并且依照句子的位置做加权的处理。
本研究利用TF-IDF,针对判决书内容记录出现次数频率较高且能代表该判决内容的字词计算权重,并依据所出现段落位置,给予加权计算,以做为挖掘毒品犯罪判决书内容获取分类关键字词辨识方法,并以此方式进行自动化分类,供统计回归分析数据应用。
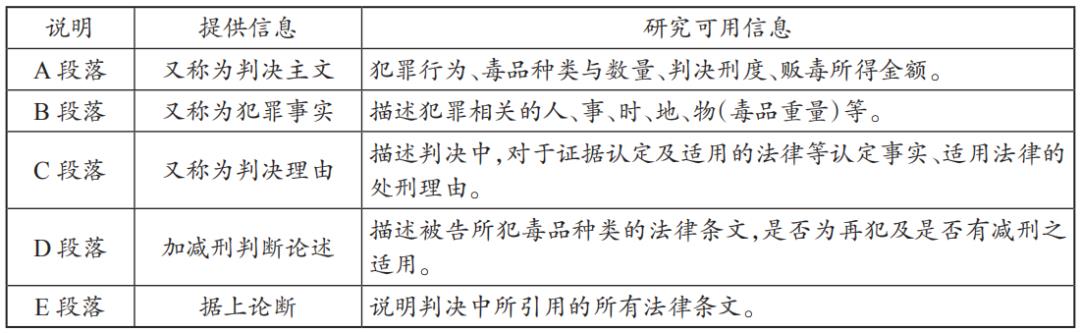
3.判决书分段信息说明
法院判决书是法官审判后,对外表现其心证的最重要司法文书。判决书是非结构化数据,其事实认定与法律适用的表述思路和风格,是由众多风格各异的法律实践者个人或集体完成的,但其基本写作逻辑和格式仍然受到制度与实践层面的严格规范。法官在案件审判中,经由一连串严谨的程序厘清被告犯罪事实是否成立,并遵守法律规范对被告罪行适用法律过程。在这个过程中,利用文字将其心证表达于判决书中,其中重要字词,或者法官在判决书中所使用的法律条文,其重要性远远超越其他类型的文字。
本研究采用的判决书全部来源于中国裁判文书网(http://www.court.gov.cn/zgcpwsw/),按照文本挖掘技术要求,对判决书进行分段(表4),通过文本挖掘技术研究文书中隐藏的对量刑分析有用的信息。
表4 判决书分段信息说明表
4.关联分析技术
关联分析的目的是确认项目或事件之间的相关性,即法律上的因果关系,以便设定关联规则来表示数据间的关系,如分析同一个消费者在同一时间内购买趋势的购物篮分析(Market Basket Analysis)或者是医学上症状与疾病间的关系。运用关联法则进行数据挖掘时,通过分析各交易内的产品项目间同时出现的关系与频率,以获得产品同时会被购买的关联形态。例如,消费者购买手机(X)的同时,在60%的情形下也会购买记忆卡(Y),这种手机与记忆卡同时被购买的关联占所有手机购买交易行为的5.6%,此时手机与记忆卡关联法则可被描述为“购买手机(X)则会购买记忆卡(Y)具有60%的信赖度及5.6%的支持度”。当关联法则的信赖度与支持度以口语的“高”或“低”表示时,关联法则将以模糊逻辑形式被表达。例如,买笔记本电脑(X)则会购买鼠标(Y)的支持度低,但信赖度高。当数据包含许多定性的属性时,以模糊逻辑形式表达的关联法则是必要且可行的,以上例来说,可以训练卖场销售人员在消费者购买手机的同时,以折扣的优惠方式推销手机记忆卡,可以获得不错的销售量。
关联分析技术主要在于发现数据间的联系,可应用在许多领域,目前,国外已经应用到司法数据研究中。运用数据集合,以关联分析产生关联规则后,再进行后续的知识探索工作。在所产生的许多关联规则中,分析人员必须努力地过滤出使用者觉得有用的规则,而这些规则可能是用户事前不知或未期望该规则会出现的。倘若系统找出有别于专家所给予规则中的新规则时,必须对于这些特殊的规则再加以探究。当找到特别且具有高度信心度的关联规则来呈现数据中的特别现象时,将会促进针对该条规则真实情况的研究,以确认规则中前因后果的关系是否存在。
在做关联词分析时,代表相关性高的字词为关联词。例如,当A词出现时,就会有很高的机会出现B词,这时则说A词与B词为关联词。关联词的分析有助于我们从大量文件中发掘出概念的关联性,关联词分析是文件中共同出现几率高的字词的系列分析步骤。本研究将利用此方法来分析判决书中关键字词与刑期之间存有的因果关联性。
5.统计分析方法
本研究以直线回归统计分析方法为主要内容,与神经网络之间比较,何者较为适用量刑预测模型建立。如以法律上因果关系来比喻,在直线回归中,前因的变量x(毒品数量)称为自变量(Independent variable)或预测变量(Predictor variable),后果的变量y(宣告刑期)称为依变量(Dependent variable)或应变量(Response variable)。研究从判决书中抽取量刑计算所需的加重或减轻刑期的关键字词,运用统计回归方法导出量刑方程式。
(四)研究架构
跨产业数据挖掘标准流程(CRoss Industry Standard Process for Data Mining,简称CRISP-DM),是1990年由SPSS以及NCR两大厂商在合作戴姆克赖斯勒-奔驰的数据仓储以及数据挖掘过程中发展出来的,是目前跨产业数据挖掘的标准化流程,已被业界广泛使用。
本研究依据跨产业数据挖掘标准流程,所使用的挖掘步骤及流程为:定义问题(Business Understanding),定义分析数据(Data Understanding),数据前置处理(Data Preparation),建立模型(Modeling),评估模型(Evaluation),应用模型(Deployment)。
定义问题(Business Understanding)。通过判决书文本挖掘,将类型复杂的判决书自动分类,并将分类后的判决书利用统计方法进行回归分析,进而求取回归方程式,建构出量刑预测模式。
定义分析数据(Data Understanding)。在文本挖掘中,所建构模型必须要避免模型过度适配问题(Overfitting),不对训练数据作过多的解释,使模型对训练数据的局部特性解释过多,造成模型过度训练,对其他的测试数据预测能力因而降低。
一般避免模型过度适配的方法有两种,测试数据集验证与十折交叉验证法(10-folds Cross Validation)。使用测试数据集验证即是将完整的数据集切分为两部分,一部分作为训练数据集,另一部分则为测试数据集,以测试数据集验证训练数据集所产生的模型,作为分类的结果。而所谓十折交叉验证法则是把数据集以随机方式区分为N个子集合(N通常为4、5或10),每一次选择其中一个子集合作为训练数据,并轮流作为训练数据集及测试数据集,最后将各次验证结果的正确率取平均值得到交互验证的正确率,作为该模型的分类结果。
本研究使用十折交叉验证法,作为模型结果的效果评估。将完整数据集切分为两部分,一部分为训练数据集作为建立模型使用,但不混入测试数据中,避免发生过度配适问题,另一部分则为测试数据集。训练与测试资料是随机选取,并采用十折交叉验证法,即随机切割资料为十份,再随机取其中九份为训练资料,所余一份作为受测资料,随机重复十次后,以平均精确率决定最佳分类模型以测试数据集验证训练数据集所产生的模型,作为评估模型优劣。研究所需处理的判决书共有388篇为数据集,可分成两大部分,第一部分是训练数据集的80%,有310篇作为训练学习数据集;第二部分是验证测试数据集的20%,有78篇作为验证测试数据集。
(一)研究数据前置处理
利用TF-IDF及N-Gram挖掘2017年310篇贩卖毒品判决书后,将获得的关键字词及信息转换数据后,再以神经网络与线性回归方法比较建模结果,并利用统计回归分析方法求取量刑预测模型公式。
1.判决书断词
利用N-Gram对判决书内容进行字汇断词,将N-Gram的N值设定为2—5。将断词后的结果加以比对(表5),以取得有意义字词去除虚词,减少字词数量,加速后续字词处理与计算TF-IDF便利性。
表5 N-Gram断词结果表
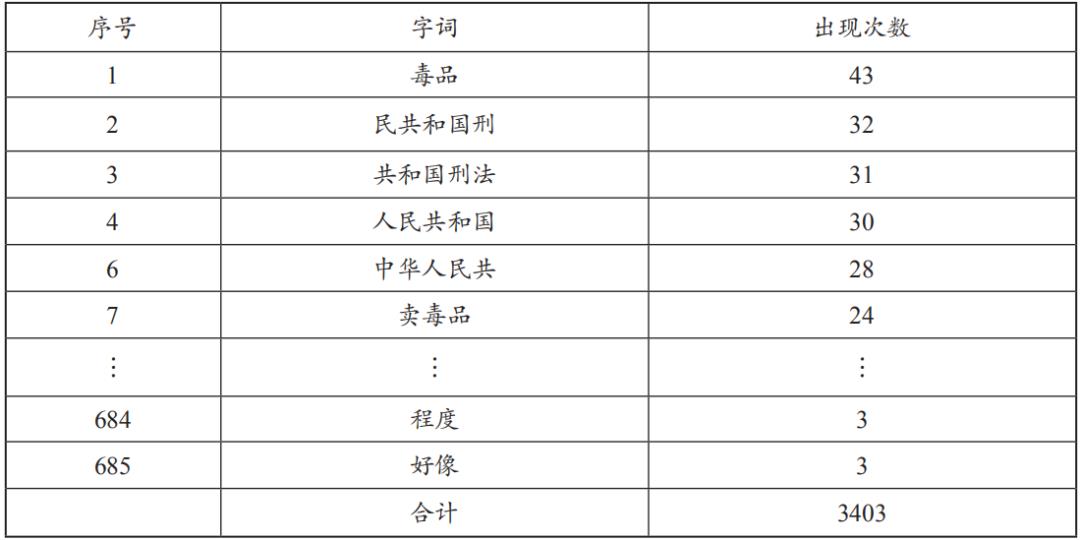
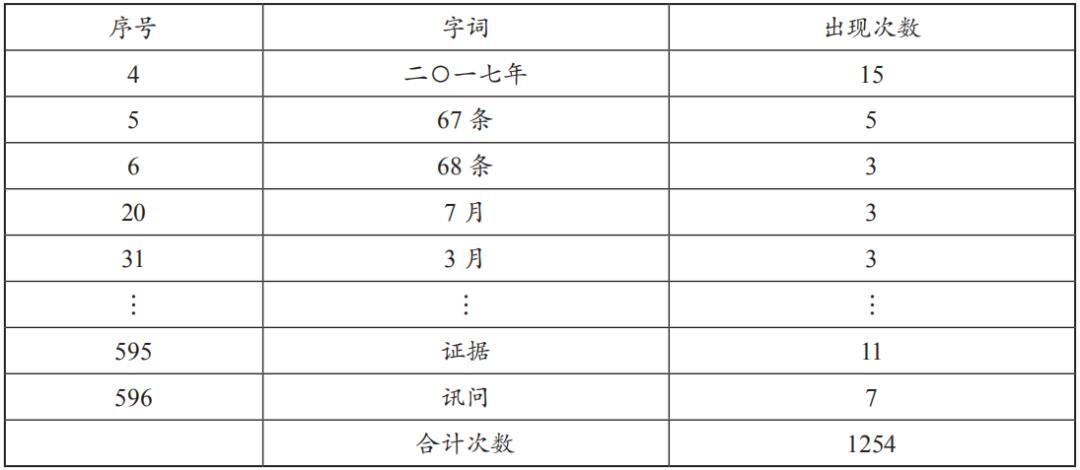
为获得判决书文本挖掘中具有意义的字词,本研究选词规则如下:首先是选出表5中出现次数大于3及长度为2—5字词,然后将两者字词做交集运算,以获得字词表。N-Gram字词表,依据以上规则可缩减及去除表5中无意义或部分重复出现的字词,以利词频(TF)计算,减少虚词带来的干扰,其结果如下(表6)。
表6 N-Gram字词表
2.关联性分析与关键字词选择
关联分析的目的在确认法律上的因果关系,以便设定关联规则来表示数据间的关系。将表6中的各个字词表(加上变数代号,便利本文分析使用)以程序一一搜寻毒品相关刑法法条的内容文字,并分析含有该字词的条文是否会影响量刑刑期的支持度,得出关联分析表(表7)。
表7 法律条文与关键字词的关联分析表
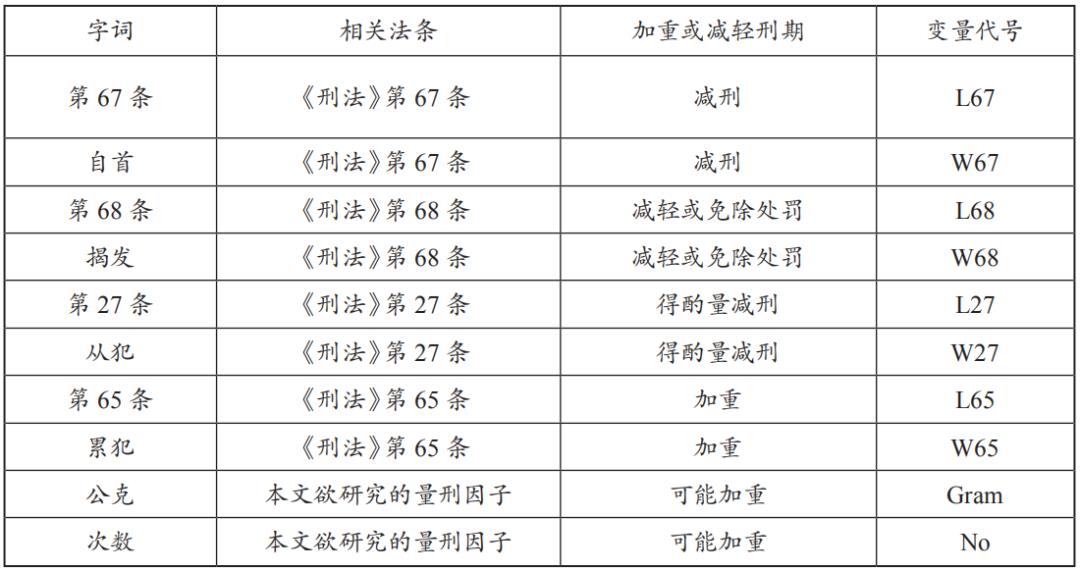
以《刑法》第67条为例,该法条因含有自首两字,因此,在判决书文本挖掘时,法条本身的条文文字(第67条)及“自首”都可能成为影响刑期的关键字词。
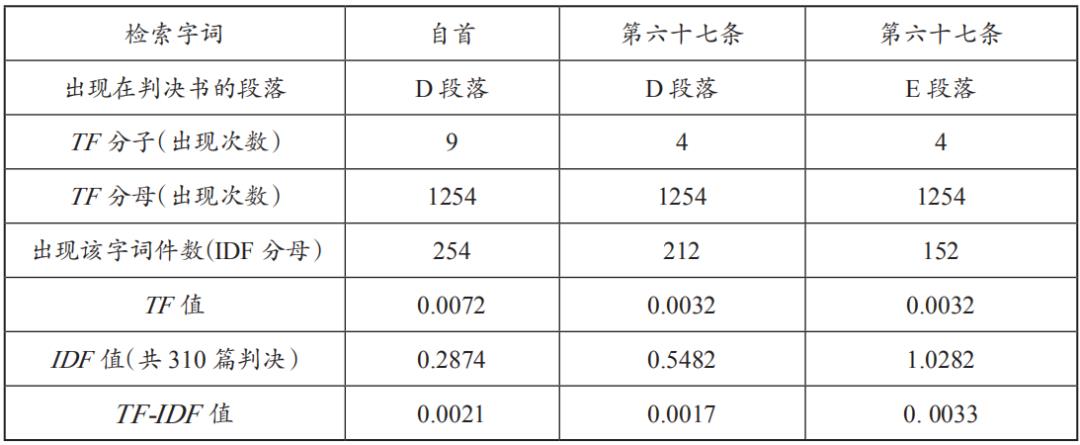
为判此两者谁更有鉴别度,计算出两者的TF、IDF、TF-IDF,得出关键字词的分析结果(表8),由TF-IDF值可知,当该表中最右边检索字词“第67条”出现在判决书段落E时,其TF-IDF的值最高,因此判定字词“第67条”具有鉴别度,为本文关键字词。
表8 《刑法》第67条分析结果表
3.关键字词数据化
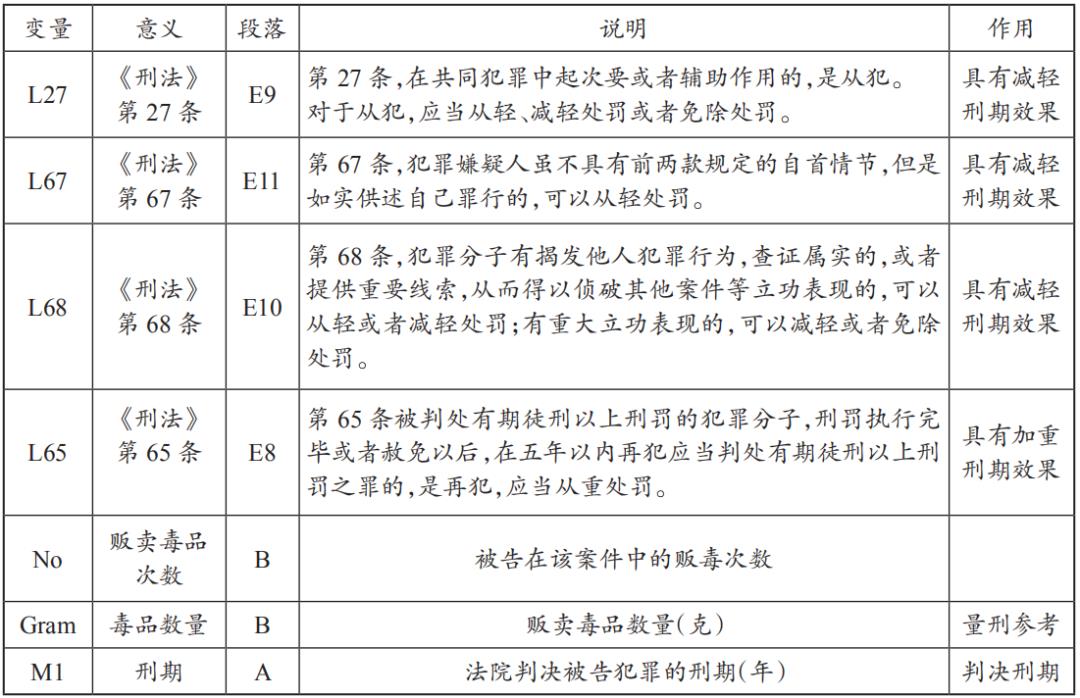
依关联性分析法则及前述判断规则,计算各个字词的TF-IDF值,加以分析310篇毒品判决书集中训练中,关键字词所出现的段落,检视其中可能影响量刑加重或减轻的字词(变量),建立成为判决书关键字词表(变量)(表9),同时将关键字词及其毒品数量等字词转换为数据形态。
表9 判决书关键字词表(变量)
(二)建立量刑预测模型
为评估量刑预测模型影响变量的完整性,同时收集了一二审法院相对应的判决(各168篇),用以评估一二审量刑刑期是否有明显的差异。
首先,为判断诉讼流程的不同与量刑期间是否有明显差异,利用T检验对168篇两组独立样本的检验得出独立样本检验(表10)。
表10 168篇两组独立样本检验
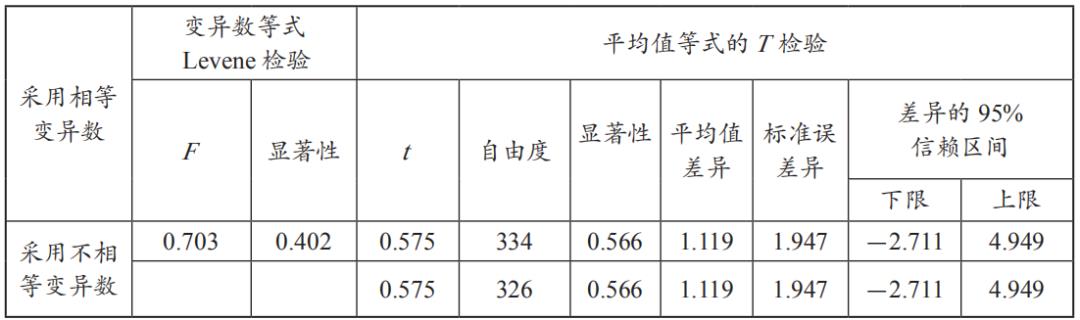
观察Levene检验,其F=0.703,P=0.402,未达显著差异,故两组变异数可视为相等;两组样本为随机选取,其变异数可视为相等,而Levene结果也支持变异数同质的假设,故T检验值以采用相等挖掘变异数这一横列的为准,t=0.575,P=0.566>0.05,未达显著标准。若从差值的95%信赖区间来看,其值域从-2.711至4.949,因包括0值在内,亦可看出两组样本没有显著差距。由以上T检验可得知,毒品案件虽然历经一审二审,但是两者在量刑刑期上并无明显差异,也说明时间变量可加以排除,不列入计算刑期影响因素中。
2. 训练资料处理
以310篇毒品判决为训练数据,先以统计回归方法进行分析,后以综合性数据挖掘工具WEKA软件为建模工具,以训练数据集进行线性回归与神经网络进行数据建模,并比较两者的训练结果作为建模依据。以线性回归方法建模所得出方程式如下:
M1=(-17.4127)*L27+(-29.1377)*L67+(-31.3321)*L68+0.0465*Gram+63.3259
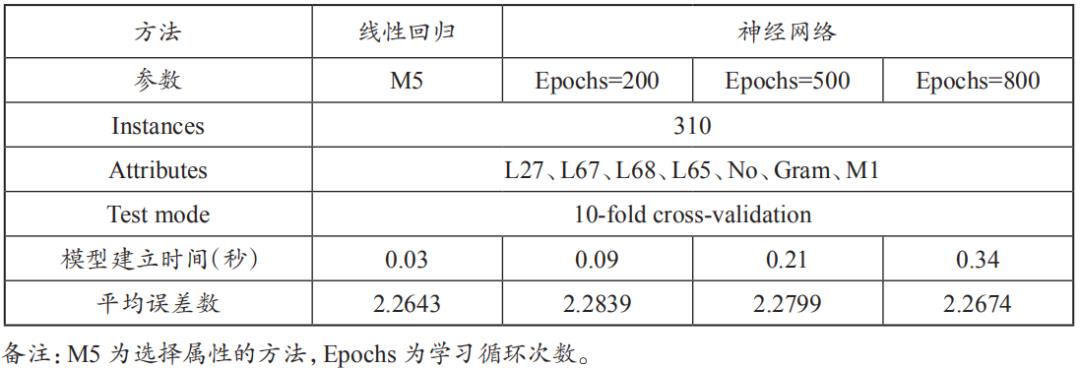
对两种建模方法结果进行比较(表11),线性回归的误差值2.2643,小于神经网络方法。此外,线性回归建构的模型在使用上比较直观且易于解释,在执行效能方面,从模型建立时间观察,线性回归方式比神经网络方法节省。
表11 6项自变量线性回归与神经网络分析结果比较
2.变量的评估与选择
依据上述结果,探讨与评估实际影响刑期的量刑因子。影响量刑因素有L27、L67、L68、L65、No、Gram及不同审级诉讼流程等7个因子,经T检验及回归分析检验后发现,不同审级诉讼流程的因子,观察独立样本检验所得数值,P=0.566>0.05,未达显著标准,显示该因子并非影响量刑的因素;另有关毒品贩卖次数No及L65这两项因子,观察模型系数及回归方程式后,No及L65也不是真正影响量刑的因素。依据以上实验结果,将可能影响量刑因素减少为L27、L67、L68及Gram等四种变量后,再次执行线性回归及神经网络分析后,得出结果(表12)。
表12 4项自变量线性回归与神经网络分析结果比较表
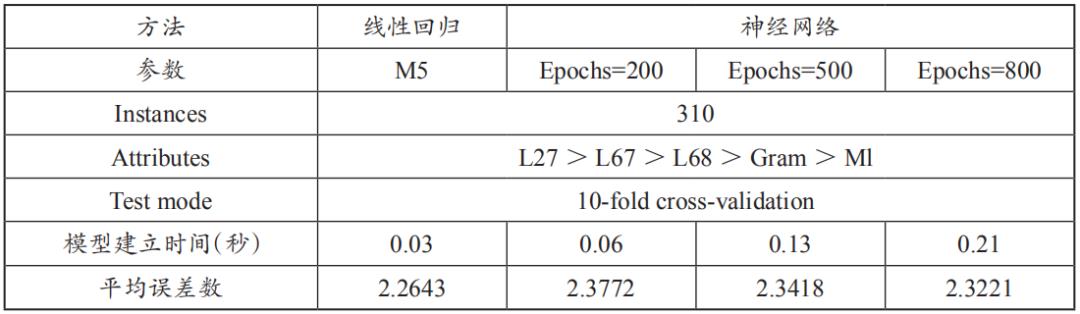
由表12可知,影响量刑的自变量由6个简化成4个后,线性回归结果不变,而对于神经网络(Epochs=800)误差值(2.3221)比表11的神经网络(Epochs=800)误差(2.2674)来得大,同时其误差也大于线性回归分析误差(2.2643)。因此,不论其变量为6个或为4个,以线性回归方式所得的模型误差值均小于神经网络,表示法院判决数据趋近于线性数据,适合以线性回归方法建立模型,而神经网络则较适合用于非线性数据。
3.线性回归模型建立
有关贩卖毒品既遂的L27、L67有罪判决分类条件,汇整如表13所示。
表13 判决书分类模型关键字词表

将训练数据集依据关键字词规则进行案件分类,检视分类结果均正确,经分类后判决分为三种类型,将这三类数据进行统计线性回归建模分析,结果如下。
(1)第一类判决
贩卖毒品依法减轻二次刑期,据上论断段落区仅含有减刑条文,并同时出现关键字词L67、L27,由310篇训练数据集中取出属于第一类判决数据98篇,进行回归分析(表14)。
表14 第一类判决线性回归分析结果

平均误差1.0907(月)
回归方程式
Y=15.876+0.482*Gram············································(1)
观察模型数据,所求出的Gram标准误差(0.0786)比回归系数(0.4815)小,P值小于0.05,代表该系数非常重要,且两变量间具有正相关性,证明该模型公式是一个恰当的方程式。
(2)第二类判决
贩卖毒品依法减轻一次刑期,据上论断段落区仅含有减刑法条,且仅出现关键字词L67,由310篇训练数据集中取出属于第二类判决数据102篇,进行回归分析(表15)。
表15 第二类判决线性回归分析结果

平均误差2.3939(月)
回归方程式
Y=33.104+0.145*Gram············································(2)
观察模型数据,所求出标准误差(0.0324)比回归系数(0.145)小,P值小于0.05,代表该系数非常重要,且两变量间具有正相关性,证明该模型公式是一个恰当的方程式。
(3)第三类判决
贩卖毒品无加减刑的一般判决,据上论断段落区未出现L67、L68、L27、L65等加减刑法条,由310篇训练数据集中取出属于第三类判决数据66篇,将其数值进行回归分析(表16)。
表16 第三类型判决线性回归分析结果

平均误差2.8998(月)
回归方程式
Y=64.141+0.042*Gram············································(3)
观察模型数据,所求标准误差(0.0049)比回归系数(0.042)小,P值小于0.05,代表该系数非常重要,且两变量间具有正相关性,证明该模型公式是一个恰当的方程式。
由于以上三类模型所求的标准误差小于回归系数,以及P值小于0.05,代表该系数非常重要,且变量间具有正相关性,证明线性回归模型公式为恰当的方程式。从以上回归方程式可以发现一个重要趋势,即判决刑期与毒品数量具有正向关系,而毒品数量的影响力(回归系数)随着刑期截距的增加,而有递减趋势。
比较三类判决模型共266篇数据的平均误差2.0393与未分类的266篇数据平均误差2.1666,可证明分类方式所建立量刑模型误差小于以未分类方式所建立模型误差。因此,研究所提出由判决书分类后再进行回归分析的建模方法,可以获得较佳的量刑预测能力。
(三)模型的测试与评估
从裁判文书网随机选取2018年结案的78件贩卖毒品既遂判决书,依模型分类,分别有25件、33件、20件。将分类判决转化为数据,再依据量刑公式计算后,获得模型预测平均刑期与案件实际刑期两者的比较(表17),及其模型预测平均刑期与判决书平均刑期两者比较(表18),证明判决分类及量刑预测模型均有良好的预测能力。
表17 模型预测与实际案件刑期差距数

表18 模型预测与量刑系统刑期差距数

四、结论与建议
(一)结论
本研究以文本挖掘技术及CRISP-DM步骤,经数据前置处理程序,整理影响量刑的重要关键字词,并将判决书内容进行数据化转换,经T检验、神经网络分析及统计线性回归分析后,其结果如下。
①毒品案件经过一审二审程序之后,刑期差距不显著,排除该项因子为影响量刑变量;②研究挖掘出可能影响量刑重要关键字词变量中,经回归分析后,排除L65及No因子为影响量刑变量;③从本研究的判决数据来看,以统计线性回归方式所建立的量刑预测模型较适用于线性数据,神经网络方式较适用于非线性数据;④将判决书分类后再进行线性回归方式建立模型,在误差优于判决书未分类所进行的线性回归方式所建立模型;⑤本研究提出的量刑预测模型,经测试数据集评估显示有良好的预测表现。
(二)建议
本研究所采纳的法院判决书文本挖掘流程与自动化模型架构,未来可以提供司法大数据应用参考。依据不同案件类型,克服司法领域数据的高维特性、紧耦合性等特征,对法院判决进行自动化分类及数据转换,利用统计线性回归方法,实时分析法院判决数据,并建立各类案件的量刑数据库,提高量刑数据库的实时性服务。
此外,建议参照美国建立量刑指导法则,设立司法量刑机构,委托学术研究机构运用大数据技术分析法院判决书,计算出各类犯罪量刑预测模型,制定量刑标准,规范法院对于相似案件的刑期计算标准,真正实现量刑均衡,确保罪刑相适应原则的正确实施,营造公正、透明、可预期的法治环境。

END
以上是关于法学∣舒洪水:司法大数据文本挖掘与量刑预测模型的研究的主要内容,如果未能解决你的问题,请参考以下文章