46-文本挖掘:无案牍之劳形
Posted 苏州机器学习互助小组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了46-文本挖掘:无案牍之劳形相关的知识,希望对你有一定的参考价值。
从苏州坐高铁12小时到深圳,其实没有想象中难熬,因为最近在家也不过在书房坐一整天。随着年龄增长,虽然好奇心和新鲜劲不如以前,但对单调枯燥的忍耐力增加了。坐在室内,没有风吹日晒,还有什么好挑剔呢?何况景色也宜人,印象中一直在山区穿行,隧道接连不断,个个坚固不摧,让人想起那首很著名的诗。余光中也写过关于回忆搭乘火车的散文,脚踏实地的感觉总是让人眷恋啊。
上周我们学习了用CountVectorizer生成文本特征向量(即词频),但实际上不一定词频越高的单词重要性越大,有的万金油一般的单词如:is, a等,几乎在每条评论中都会出现,然而对于评价好坏没有决定性影响。今天继续学习文本特征编码的一种常用加权技术:TF-IDF算法。
先回顾一下上周关于CountVectorizer 的代码:
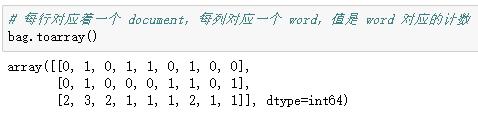
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在某个文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数),以防止它偏向长的文件。

逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
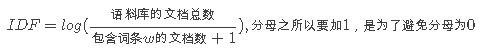
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
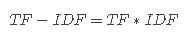
Scikit-learn中实现了TfidfTransformer,它将 CountVectorizer 返回的原始词频转化为tf-idfs:
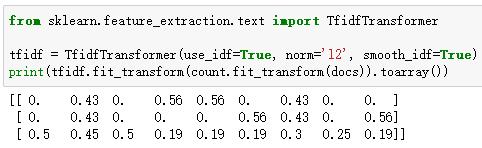
“is”这个词(第2列)是文档3中出现频率最高的词,然而,将特征向量转换成tf-idfs之后,我们看到,“is”这个词对于文档3有一个相对较小的tf-idf(0.45),因为它也包含在文档1和2中,因此不太可能包含任何有用的区分性的信息。
验算可以发现,Scikit-learn中实现的TfidfTransformer和之前定义的不太一样。Scikit-learn中的Tfidf的计算公式如下:
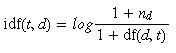
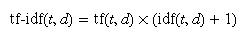
最后一般还会正则化每一个Tfidf值(常用L2正则化):
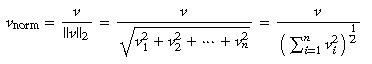
可以验证下"is"在文档3中的Tfidf值:
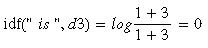
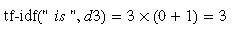
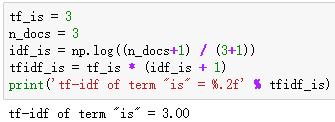
如果对文档3中每个单词求Tfidf值,我们可以得到向量: [3.39, 3.0, 3.39, 1.29, 1.29, 1.29, 2.0 , 1.69, 1.29],L2正则化得到:
是否正则化可以通过TfidfTransformer中的norm参数来指定,下面先不用正则化,然后手动正则化来进一步验证:
下周学习文本的进一步预处理(表情符清洗、文本切分和停词去除)及逻辑回归实现评价文本极性判断,敬请期待:)
以上是关于46-文本挖掘:无案牍之劳形的主要内容,如果未能解决你的问题,请参考以下文章