小白入门文本挖掘之基础篇
Posted 数据大学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白入门文本挖掘之基础篇相关的知识,希望对你有一定的参考价值。
一、什么是文本挖掘
文本挖掘指的是从文本数据中获取有价值的信息和知识,它是数据挖掘中的一种方法。文本挖掘中最重要最基本的应用是实现文本的分类和聚类,前者是有监督的挖掘算法,后者是无监督的挖掘算法。
文本挖掘是一个多学科混杂的领域,涵盖了多种技术,包括数据挖掘技术、信息抽取、信息检索,机器学习、自然语言处理、计算语言学、统计数据分析、线性几何、概率理论甚至还有图论。
二、文本挖掘有什么用
1、文本分类
文本分类是一种典型的机器学习方法,一般分为训练和分类两个阶段。文本分类一般采用统计方法或机器学习来实现。
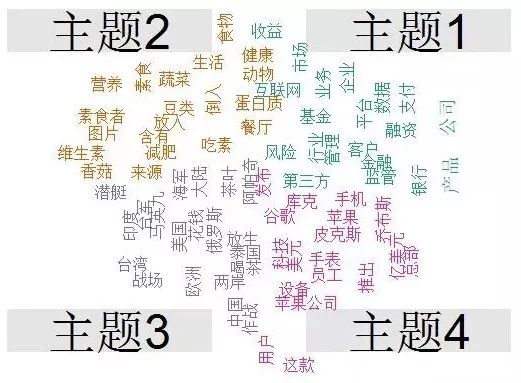
2、文本聚类
文本聚类是一种典型的无监督式机器学习方法,聚类方法的选择取决于数据类型。
首先,文档聚类可以发现与某文档相似的一批文档,帮助知识工作者发现相关知识;其次,文档聚类可以将一类文档聚类成若干个类,提供一种组织文档集合的方法;再次,文档聚类还可以生成分类器以对文档进行分类。
文本挖掘中的聚类可用于:提供大规模文档内容总括;识别隐藏的文档间的相似度;减轻浏览相关、相似信息的过程。
3、信息检索
主要是利用计算机系统的快速计算能力,从海量文档中寻找用户需要的相关文档。

4、信息抽取
信息抽取是把文本里包含的信息进行结构化处理,变成表格一样的组织形式。输入信息抽取系统的是原始文本,输出的是固定格式的信息。
5、自动文摘
利用计算机自动的从原始文档中提取出文档的主要内容。互联网上的文本信息、机构内部的文档及数据库的内容都在成指数级的速度增长,用户在检索信息的时候,可以得到成千上万篇的返回结果,其中许多是与其信息需求无关或关系不大的,如果要剔除这些文档,则必须阅读完全文,这要求用户付出很多劳动,而且效果不好。
自动文摘能够生成简短的关于文档内容的指示性信息,将文档的主要内容呈现给用户,以决定是否要阅读文档的原文,这样能够节省大量的浏览时间。简单地说自动文摘就是利用计算机自动地从原始文档中提取全面准确地反映该文档中心内容的简单连贯的短文。

自动文摘具有以下特点:
(1)自动文摘应能将原文的主题思想或中心内容自动提取出来。
(2)文摘应具有概况性、客观性、可理解性和可读性。
(3)可适用于任意领域。
按照生成文摘的句子来源,自动文摘方法可以分成两类,一类是完全使用原文中的句子来生成文摘,另一类是可以自动生成句子来表达文档的内容。后者的功能更强大,但在实现的时候,自动生成句子是一个比较复杂的问题,经常出现产生的新句子不能被理解的情况,因此目前大多用的是抽取生成法。
6、自动问答
自动问答是指对于用户提出的问题,计算机可以自动的从相关资料中求解答案并作出相应的回答。自动问答系统一般包括 3 个组成部分:问题分析、信息检索和答案抽取。
7、机器翻译
利用计算机将一种源语言转变为另一种源语言的过程。

8、信息过滤
指计算机系统可以自动的进行过滤操作,将满足条件的信息保留,将不满足条件的文档过滤掉。信息过滤技术主要用于信息安全领域。
9、自动语音识别
自动语音识别就是将输入计算机的自然语言转换成文本表示的书面语。

三、文本挖掘操作步骤
1、获取文本
现有文本数据导入,或者通过如网络爬虫等技术获取网络文本,主要是获取网页html的形式。我们要把网络中的文本获取文本数据库(数据集)。编写爬虫程序,抓取到网络中的信息。

2、文本预处理
指剔除噪声文档以改进挖掘精度,或者在文档数量过多时仅选取一部分样本以提高挖掘效率。
例如网页中存在很多不必要的信息,比如说一些广告,导航栏,html、js代码,注释等等并不需要的信息,可以删除掉。如果是需要正文提取,可以利用标签用途、标签密度判定、数据挖掘思想、视觉网页块分析技术等等策略抽取出正文。

3、文本的语言学处理
(1)分词
经过上面的步骤,我们会得到比较干净的素材。文本中起到关键作用的是一些词,甚至主要词就能起到决定文本取向。比如说一篇文章讲的是政治还是经济,肯定是对文章中的中心词进行分析得到的结果。 所以接下来的步骤就是分词。
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多。
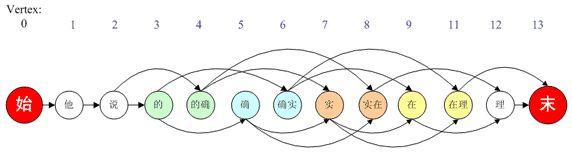
现在针对中文分词,出现了很多分词的算法,有最大匹配法、最优匹配法、机械匹配法、逆向匹配法、双向匹配法等等。
(2)词性标注
同时也可以使用词性标注。通过很多分词工具分出来的出会出现一个词,外加该词的词性。比如说啊是语气助词。

(3)去除停用词
比如说句号、是、的等词,没有什么实际的意义。然而这些词在所有的文章中都大量存在,并不能反应出文本的意思,可以处理掉。当然针对不同的应用还有很多其他词性也是可以去掉的,比如形容词等。
4、文本的数学处理-特征提取
我们希望获取到的词汇,既能保留文本的信息,同时又能反映它们的相对重要性。如果对所有词语都保留,维度会特别高,矩阵将会变得特别稀疏,严重影响到挖掘结果。所以这就需要特征提取。
特征选取的方式有4种:
(1)用映射或变换的方法把原始特征变换为较少的新特征;
(2)从原始特征中挑选出一些最具代表性的特征;
(3)根据专家的知识挑选最有影响的特征;
(4)用数学的方法进行选取,找出最具分类信息的特征,这种方法是一种比较精确的方法,人为因素的干扰较少,尤其适合于文本自动分类挖掘系统的应用。
5、分类聚类
经过上面的步骤之后,我们就可以把文本集转化成一个矩阵。我们能够利用各种算法进行挖掘,比如说如果要对文本集进行分类,分类常用的方法有:简单贝叶斯分类法,矩阵变换法、K-最近邻参照分类算法以及支持向量机分类方法等。
聚类方法通常有:层次聚类法、平面划分法、简单贝叶斯聚类法、K-最近邻聚类法、分级聚类法等。
6、数据可视化
最后一步当然就是数据结构的可视化展示,通过合适的可视化图形生动形象展示,让读者听众更容易理解你所要表达的信息。
文本可视化最常用的图形就是词云。



四、文本挖掘工具
1、python语言jieba、gensim、sklearn、WordCloud和matplotlib包
2、R语言jieba、tm、tmcn、Rwordseg和wordcloud包
3、SAS text miner
4、SPSS Text Mining
数据分析进阶
就在数据大学堂
以上是关于小白入门文本挖掘之基础篇的主要内容,如果未能解决你的问题,请参考以下文章
文本挖掘在量化投资中的应用之(28篇最全券商研报)+(2个策略程序)
[Python从零到壹] 十五.文本挖掘之数据预处理Jieba工具和文本聚类万字详解