[Python从零到壹] 十五.文本挖掘之数据预处理Jieba工具和文本聚类万字详解
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python从零到壹] 十五.文本挖掘之数据预处理Jieba工具和文本聚类万字详解相关的知识,希望对你有一定的参考价值。
欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲述了分类算法的原理知识级案例,包括决策树、KNN、SVM,并通过详细的分类对比实验和可视化边界分析与大家总结。本文将详细讲解数据预处理、Jieba分词和文本聚类知识,这篇文章可以说是文本挖掘和自然语言处理的入门文章。两万字基础文章,希望对您有所帮助。
文章目录
下载地址:
前文赏析:
第一部分 基础语法
- [Python从零到壹] 一.为什么我们要学Python及基础语法详解
- [Python从零到壹] 二.语法基础之条件语句、循环语句和函数
- [Python从零到壹] 三.语法基础之文件操作、CSV文件读写及面向对象
第二部分 网络爬虫
- [Python从零到壹] 四.网络爬虫之入门基础及正则表达式抓取博客案例
- [Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
- [Python从零到壹] 六.网络爬虫之BeautifulSoup爬取豆瓣TOP250电影详解
- [Python从零到壹] 七.网络爬虫之Requests爬取豆瓣电影TOP250及CSV存储
- [Python从零到壹] 八.数据库之MySQL基础知识及操作万字详解
- [Python从零到壹] 九.网络爬虫之Selenium基础技术万字详解(定位元素、常用方法、键盘鼠标操作)
- [Python从零到壹] 十.网络爬虫之Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)
第三部分 数据分析和机器学习
- [Python从零到壹] 十一.数据分析之Numpy、Pandas、Matplotlib和Sklearn入门知识万字详解(1)
- [Python从零到壹] 十二.机器学习之回归分析万字总结全网首发(线性回归、多项式回归、逻辑回归)
- [Python从零到壹] 十三.机器学习之聚类分析万字总结全网首发(K-Means、BIRCH、层次聚类、树状聚类)
- [Python从零到壹] 十四.机器学习之分类算法三万字总结全网首发(决策树、KNN、SVM、分类算法对比)
- [Python从零到壹] 十五.文本挖掘之数据预处理、Jieba工具和文本聚类万字详解
作者新开的“娜璋AI安全之家”将专注于Python和安全技术,主要分享Web渗透、系统安全、人工智能、大数据分析、图像识别、恶意代码检测、CVE复现、威胁情报分析等文章。虽然作者是一名技术小白,但会保证每一篇文章都会很用心地撰写,希望这些基础性文章对你有所帮助,在Python和安全路上与大家一起进步。
前文第一部分详细介绍了各种Python网络数据爬取方法,但所爬取的语料都是中文知识,在第二部分前面的章节也讲述了常用的数据分析模型及实例。这些实例都是针对数组或矩阵语料进行分析的,那么如何对中文文本语料进行数据分析呢?在本章作者将带领大家走进文本聚类分析领域,讲解文本预处理和文本聚类等实例内容。
一.数据预处理概述
在数据分析和数据挖掘中,通常需要经历前期准备、数据爬取、数据预处理、数据分析、数据可视化、评估分析等步骤,而数据分析之前的工作几乎要花费数据工程师近一半的工作时间,其中的数据预处理也将直接影响后续模型分析的好坏。
数据预处理(Data Preprocessing)是指在进行数据分析之前,对数据进行的一些初步处理,包括缺失值填写、噪声处理、不一致数据修正、中文分词等,其目标是得到更标准、高质量的数据,纠正错误异常数据,从而提升分析的结果。
图1是数据预处理的基本步骤,包括中文分词、词性标注、数据清洗、特征提取(向量空间模型存储)、权重计算(TF-IDF)等。
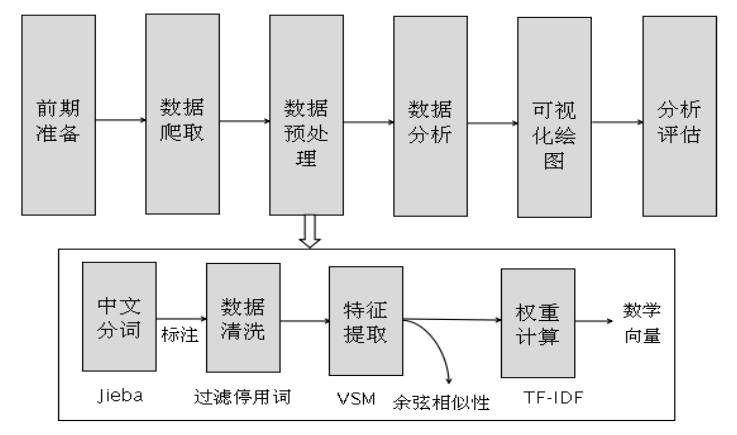
1.中文分词技术及Jieba工具
在得到语料之后,首先需要做的就是对中文语料进行分词。由于中文词语之间是紧密联系的,一个汉语句子是由一串前后连续的汉字组成,词与词之间没有明显的分界标志,所以需要通过一定的分词技术把句子分割成空格连接的词序列。本章介绍了中文常用的分词技术,同时着重讲解了Python常用分词工具Jieba进行分词的实例。
2.数据清洗及停用词过滤
在使用Jieba中文分词技术得到分完词的语料后,可能会存在脏数据和停用词等现象。为了得到更好的数据分析结果,需要对这些数据集进行数据清洗和停用词过滤等操作,这里利用Jieba库进行清洗数据。
3.词性标注
词性标注是指为分词结果中的每个单词或词组标注一个正确的词性,即确定每个词是名词、动词、形容词或其他词性的过程。通过词性标注可以确定词在上下文中的作用,通常词性标注是自然语言处理和数据预处理的基础步骤,Python也提供了相关库进行词性标注。

4.特征提取
特征提取是指将原始特征转换为一组具有明显物理意义或者统计意义的核心特征,所提取的这组特征可以尽可能地表示这个原始语料,提取的特征通常会存储至向量空间模型中。向量空间模型是用向量来表征一个文本,它将中文文本转化为数值特征。本章介绍了特征提取、向量空间模型和余弦相似性的基本知识,同时结合实例进行深入讲解。
5.权重计算及TFIDF
在建立向量空间模型过程中,权重的表示尤为重要,常用方法包括布尔权重、词频权重、TF-IDF权重、熵权重方法等。本章讲述了常用的权重计算方法,并详细讲解了TF-IDF的计算方法和实例。
现在假设存在表1所示的数据集,并存储至本地test.txt文件中,整章内容都将围绕该数据集进行讲解,数据集共分为9行数据,包括3个主题,即:贵州旅游、大数据和爱情。接下来依次对数据预处理的各个步骤进行分析讲解。
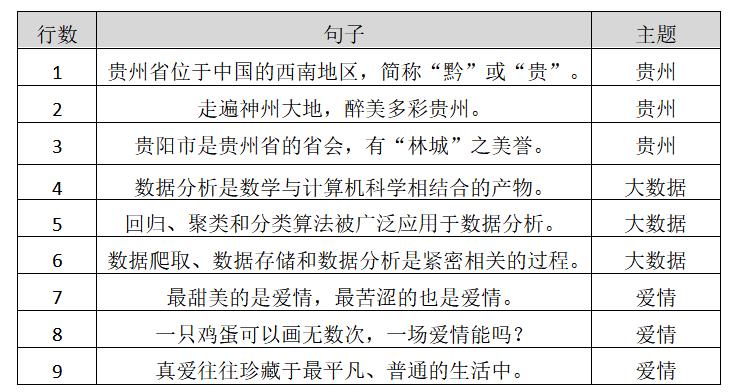
贵州省位于中国的西南地区,简称“黔”或“贵”。
走遍神州大地,醉美多彩贵州。
贵阳市是贵州省的省会,有“林城”之美誉。
数据分析是数学与计算机科学相结合的产物。
回归、聚类和分类算法被广泛应用于数据分析。
数据爬取、数据存储和数据分析是紧密相关的过程。
最甜美的是爱情,最苦涩的也是爱情。
一只鸡蛋可以画无数次,一场爱情能吗?
真爱往往珍藏于最平凡、普通的生活中。
二.中文分词
当读者使用Python爬取了中文数据集之后,首先需要对数据集进行中文分词处理。由于英文中的词与词之间是采用空格关联的,按照空格可以直接划分词组,所以不需要进行分词处理,而中文汉字之间是紧密相连的,并且存在语义,词与词之间没有明显的分隔点,所以需要借助中文分词技术将语料中的句子按空格分割,变成一段段词序列。下面开始详细介绍中文分词技术及Jiaba中文分词工具。
1.中文分词技术
中文分词(Chinese Word Segmentation)指将汉字序列切分成一个个单独的词或词串序列,它能够在没有词边界的中文字符串中建立分隔标志,通常采用空格分隔。中文分词是数据分析预处理、数据挖掘、文本挖掘、搜索引擎、知识图谱、自然语言处理等领域中非常基础的知识点,只有经过中文分词后的语料才能转换为数学向量的形式,继续进行后面的分析。同时,由于中文数据集涉及到语义、歧义等知识,划分难度较大,比英文复杂很多。下面举个简单示例,对句子“我是程序员”进行分词操作。
输入:我是程序员
输出1:我\\是\\程\\序\\员
输出2:我是\\是程\\程序\\序员
输出3:我\\是\\程序员
这里分别采用了三种方法介绍中文分词。
- “我\\是\\程\\序\\员”采用的是一元分词法,将中文字符串分隔为单个汉字;
- “我是\\是程\\程序\\序员”采用二元分词法,将中文汉字两两分隔;
- “我\\是\\程序员”是比较复杂但更实用的分词方法,它根据中文语义来进行分词的,其分词结果更准确。
中文分词方法有很多,常见的包括:
- 基于字符串匹配的分词方法
- 基于统计的分词方法
- 基于语义的分词方法
这里介绍比较经典的基于字符串匹配的分词方法。
基于字符串匹配的分词方法又称为基于字典的分词方法,它按照一定策略将待分析的中文字符串与机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功,并识别出对应的词语。该方法的匹配原则包括最大匹配法(MM)、逆向最大匹配法(RMM)、逐词遍历法、最佳匹配法(OM)、并行分词法等。
正向最大匹配法的步骤如下,假设自动分词词典中的最长词条所含汉字的个数为n。
- ① 从被处理文本中选取当前中文字符串中的前n个中文汉字作为匹配字段,查找分词词典,若词典中存在这样一个n字词,则匹配成功,匹配字段作为一个词被切分出来。
- ② 若分词词典中找不到这样的一个n字词,则匹配失败,匹配字段去掉最后一个汉字,剩下的中文字符作为新的匹配字段,继续进行匹配。
- ③ 循环步骤进行匹配,直到匹配成功为止。
例如,现在存在一个句子“北京理工大学生前来应聘”,使用正向最大匹配方法进行中文分词的过程如下所示。
分词算法:正向最大匹配法
输入字符:北京理工大学生前来应聘
分词词典:北京、北京理工、理工、大学、大学生、生前、前来、应聘
最大长度:6
匹配过程:
-
(1)选取最大长度为6的字段匹配,即“北京理工大学”匹配词典“北京理工大学”在词典中没有匹配字段,则去除一个汉字,剩余“北京理工大”继续匹配,该词也没有匹配字段,继续去除一个汉字,即“北京理工”,分词词典中存在该词,则匹配成功。结果:匹配“北京理工”
-
(2)接着选取长度为6的字符串进行匹配,即“大学生前来应” “大学生前来应”在词典中没有匹配字段,继续从后去除汉字,“大学生” 三个汉字在词典中匹配成功。结果:匹配“大学生”
-
(3)剩余字符串“前来应聘”继续匹配“前来应聘”在词典中没有匹配字段,继续从后去除汉字,直到“前来”。结果:匹配“前来”
-
(4)最后的字符串“应聘”进行匹配。结果:匹配“应聘”
-
分词结果:北京理工 \\ 大学生 \\ 前来 \\ 应聘
随着中文数据分析越来越流行、应用越来越广,针对其语义特点也开发出了各种各样的中文分词工具,常见的分词工具包括:
- Stanford汉语分词工具
- 哈工大语言云(LTP -cloud)
- 中国科学院汉语词法分析系统(ICTCLAS)
- IKAnalyzer分词
- 盘古分词
- 庖丁解牛分词
- …
同时针对Python语言的常见中文分词工具包括:盘古分词、Yaha分词、Jieba分词等,它们的用法都相差不大,由于结巴分词速度较快,可以导入词典如“颐和园”、“黄果树瀑布”等专有名词再进行中文分词等特点,本文主要介绍结巴(Jieba)分词工具讲解中文分词。
2.Jieba中文分词用法
(1) 安装过程
作者推荐大家使用PIP工具来安装Jieba中文分词包。安装语句如下:
pip install jieba
调用命令“pip install jieba”安装jieba中文分词包如图所示。
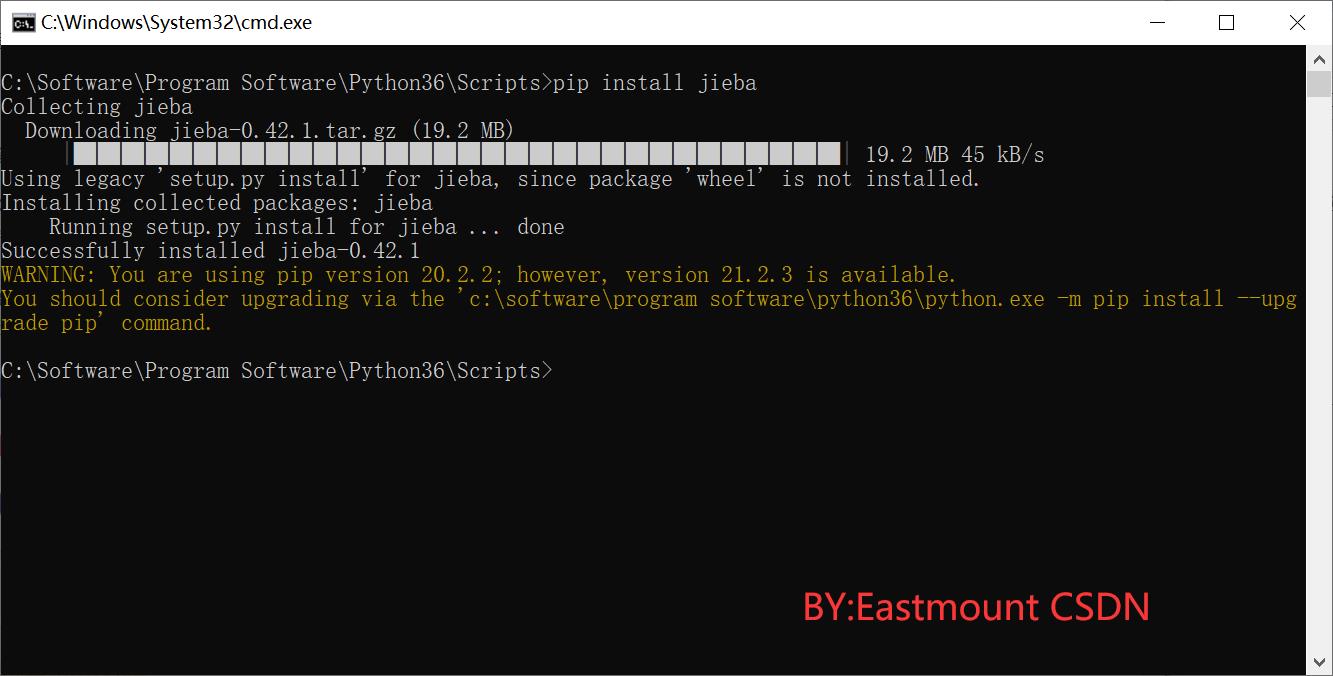
安装过程中的会显示安装配置相关包和文件的百分比,直到出现“Successfully installed jieba”命令,表示安装成功。注意,在安装过程中会遇到各种问题,大家一定要学会独立搜索答案解决这些问题,才能提升您独立解决问题的能力。
同时,如果您使用Anaconda Spyder集成环境,则调用“Anaconda Prompt”命令行模式输入“pip install jieba”命令进行安装。如果您的Python开发环境已经安装了该扩展包,则会提示已经存在Jieba中文分词包,如图所示。

(2) 基础用法
首先读者看一段简单的结巴分词代码。
- jieba.cut(text,cut_all=True)
分词函数,第一个参数是需要分词的字符串,第二个参数表示是否为全模式。分词返回的结果是一个可迭代的生成器(generator),可使用for循环来获取分词后的每个词语,更推荐读者转换为list列表再使用。 - jieba.cut_for_search(text)
搜索引擎模式分词,参数为分词的字符串,该方法适合用于搜索引擎构造倒排索引的分词,粒度比较细。
#coding=utf-8
#By:Eastmount CSDN
import jieba
text = "小杨毕业于北京理工大学,从事Python人工智能相关工作。"
#全模式
data = jieba.cut(text,cut_all=True)
print(type(data))
print(u"[全模式]: ", "/".join(data))
#精确模式
data = jieba.cut(text,cut_all=False)
print(u"[精确模式]: ", "/".join(data))
#默认是精确模式
data = jieba.cut(text)
print(u"[默认模式]: ", "/".join(data))
#搜索引擎模式
data = jieba.cut_for_search(text)
print(u"[搜索引擎模式]: ", "/".join(data))
#返回列表
seg_list = jieba.lcut(text, cut_all=False)
print("[返回列表]: {0}".format(seg_list))
输出结果如下所示。

最终的分词结果比较理想,其中精确模式输出的“小/杨/毕业/于/北京理工大学/,/从事/Python/人工智能/相关/工作/。”比较精准。下面简单叙述结巴中文分词的三种分词模式。
全模式
该模式将语料中所有可以组合成词的词语都构建出来,其优点是速度非常快,缺点是不能解决歧义问题,并且分词结果不太准确。其分词结果为“小/杨/毕业/于/北京/北京理工/北京理工大学/理工/理工大/理工大学/工大/大学///从事/Python/人工/人工智能/智能/相关/工作//”。
精确模式
该模式利用其算法将句子最精确地分隔开,适合文本分析,通常采用这种模式进行中文分词。其分词结果为“小/杨/毕业/于/北京理工大学/,/从事/Python/人工智能/相关/工作/。”,其中“北京理工大学”、“人工智能”这些完整的名词被精准识别,但也有部分词未被识别,后续导入词典可以实现专有词汇识别。
搜索引擎模式
该模式是在精确模式基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。其结果为“小/杨/毕业/于/北京/理工/工大/大学/理工大/北京理工大学/,/从事/Python/人工/智能/人工智能/相关/工作/。”。
Python提供的结巴(Jieba)中文分词包主要利用基于Trie树结构实现高效的词图扫描(构建有向无环图DAG)、动态规划查找最大概率路径(找出基于词频的最大切分组合)、基于汉字成词能力的HMM模型等算法,这里不进行详细叙述,本书更侧重于应用案例。同时结巴分词支持繁体分词和自定义字典方法。
- ==load_userdict(f) ==
(3) 中文分词实例
下面对表1中的语料进行中文分词。代码为依次读取文件中的内容,并调用结巴分词包进行中文分词,然后存储至本地文件中。
#coding=utf-8
#By:Eastmount CSDN
import os
import codecs
import jieba
import jieba.analyse
source = open("test.txt", 'r')
line = source.readline().rstrip('\\n')
content = []
while line!="":
seglist = jieba.cut(line,cut_all=False) #精确模式
output = ' '.join(list(seglist)) #空格拼接
print(output)
content.append(output)
line = source.readline().rstrip('\\n')
else:
source.close()
输出如图所示,可以看到分词后的语料。

三.数据清洗
在分析语料的过程中,通常会存在一些脏数据或噪声词组干扰我们的实验结果,这就需要对分词后的语料进行数据清洗(Data Cleaning)。比如前面使用Jieba工具进行中文分词,它可能存在一些脏数据或停用词,如“我们”、“的”、“吗”等。这些词降低了数据质量,为了得到更好的分析结果,需要对数据集进行数据清洗或停用词过滤等操作。本节主要介绍数据清洗概念、中文数据清洗技术及停用词过滤,并利用Jieba分词工具进行停用词和标点符号的清洗。
1.数据清洗概述
脏数据通常是指数据质量不高、不一致或不准确的数据,以及人为造成的错误数据等。作者将常见的脏数据分为四类:
- 残缺数据
该类数据是指信息存在缺失的数据,通常需要补齐数据集再写入数据库或文件中。比如统计9月份30天的销售数据,但期间某几天数据出现丢失,此时需要对数据进行补全操作。 - 重复数据
数据集中可能存在重复数据,此时需要将重复数据导出让客户确认并修正数据,从而保证数据的准确性。在清洗转换阶段,对于重复数据项尽量不要轻易做出删除决策,尤其不能将重要的或有业务意义的数据过滤掉,校验和重复确认的工作是必不可少的。 - 错误数据
该类脏数据常常出现在网站数据库中,是指由于业务系统不够健全,在接收输入后没有进行判断或错误操作直接写入后台数据库造成的,比如字符串数据后紧跟一个回车符、不正确的日期格式等。这类错误可以通过去业务系统数据库用SQL语句进行挑选,再交给业务部门修正。 - 停用词
分词后的语料并不是所有的词都与文档内容相关,往往存在一些表意能力很差的辅助性词语,比如中文词组“我们”、“的”、“可以”等,英文词汇“a”、“the”等。这类词在自然语言处理或数据挖掘中被称为停用词(Stop Words),它们是需要进行过滤的。通常借用停用词表或停用词字典进行过滤。
数据清洗主要解决脏数据,从而提升数据质量,它主要应用于数据仓库、数据挖掘、数据质量管理等领域。读者可以简单将数据清洗定位为:只要是有助于解决数据质量问题的处理过程就被认为是数据清洗,不同领域的数据清洗定义有所不同。总之,数据清洗的目的是保证数据质量,提供准确数据,其任务是通过过滤或者修改那些不符合要求的数据,从而更好地为后面的数据分析作铺垫。
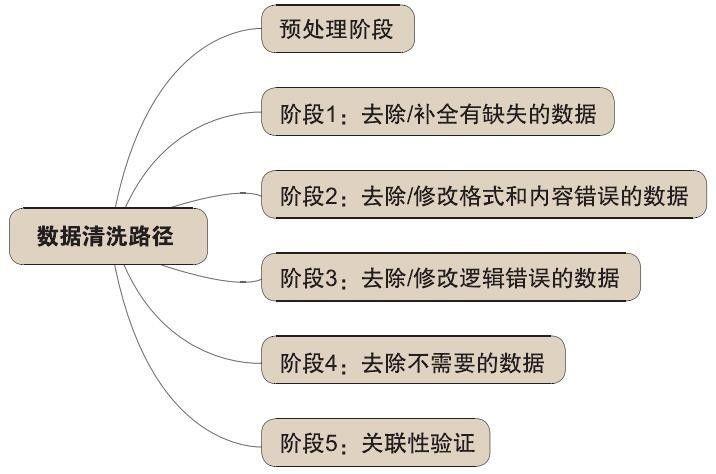
为了解决上述问题,将数据清洗方法划分为:
- 解决残缺数据
对于空值或缺失数据,需要采用估算填充方法解决,常见的估算方法包括样本均值、中位数、众数、最大值、最小值等填充,比如选取所有数据的平均值来填充缺失数据。这些方法会存在一定的误差,如果空值数据较多,则会对结果造成影响,偏离实际情况。 - 解决重复数据
简单的重复数据需要人为识别,而计算机解决重复数据的方法较为复杂。其方法通常会涉及到实体识别技术,采用有效的技术识别处相似的数据,这些相似数据指向同一实体,再对这些重复数据进行修正。 - 解决错误数据
对于错误数据,通常采用统计方法进行识别,如偏差分析、回归方程、正态分布等,也可以用简单的规则库检测数值范围,使用属性间的约束关系来校对这些数据。 - 解决停用词
停用词概念由Hans Peter Luhn提出,并为信息处理做出了巨大的贡献。通常存在一个存放停用词的集合,叫做停用词表,停用词往往由人工根据经验知识加入,具有通用性。解决停用词的方法即利用停用词词典或停用词表进行过滤。比如“并”、“当”、“地”、“啊”等字都没有具体的含义,需要过滤,还存在一些如“我们”、“但是”、“别说”、“而且”等词组也需要过滤。
2.中文语料清洗
前面已将Python爬取的中文文本语料进行了分词处理,接下来 需要对其进行数据清洗操作,通常包括停用词过滤和特殊标点符号去除等,而对于空值数据、重复数据,作者更建议大家在数据爬取过程中就进行简单的判断或补充缺失值。下面对表1所提供的中文语料(包括贵州、大数据和爱情三个主题)进行数据清洗实例操作。
(1) 停用词过滤
上图是使用结巴工具中文分词后的结果,但它存在一些出现频率高却不影响文本主题的停用词,比如“数据分析是数学与计算机科学相结合的产物”句子中的“是”、“与”、“的”等词,这些词在预处理时是需要进行过滤的。
这里作者定义一个符合该数据集的常用停用词表的数组,然后将分词后的序列,每一个字或词组与停用词表进行比对,如果重复则删除该词语,最后保留的文本能尽可能地反应每行语料的主题。代码如下:
#coding=utf-8
#By:Eastmount CSDN
import os
import codecs
import jieba
import jieba.analyse
#停用词表
stopwords = {}.fromkeys(['的', '或', '等', '是', '有', '之', '与',
'和', '也', '被', '吗', '于', '中', '最'])
source = open("test.txt", 'r')
line = source.readline().rstrip('\\n')
content = [] #完整文本
while line!="":
seglist = jieba.cut(line,cut_all=False) #精确模式
final = [] #存储去除停用词内容
for seg in seglist:
if seg not in stopwords:
final.append(seg)
output = ' '.join(list(final)) #空格拼接
print(output)
content.append(output)
line = source.readline().rstrip('\\n')
else:
source.close()
其中stopwords变量定义了停用词表,这里只列举了与我们test.txt语料相关的常用停用词,而在真实的预处理中,通常会从文件中导入常见的停用词表,包含了各式各样的停用词,读者可以去网上搜索查看。
核心代码是for循环判断分词后的语料是否在停用词表中,如果不在则添加到新的数组final中,最后保留的就是过滤后文本,如图所示。

(2) 去除标点符号
在做文本分析时,标点符号通常也会被算成一个特征,从而影响分析的结果,所以我们需要把标点符号也进行过滤。其过滤方法和前面过滤停用词的方法一致,建立一个标点符号的数组或放到停用词stopwords中,停用词数组如下:
stopwords = {}.fromkeys(['的', '或', '等', '是', '有', '之', '与',
'和', '也', '被', '吗', '于', '中', '最',
'“', '”', '。', ',', '?', '、', ';'])
同时将文本内容存储至本地result.txt文件中,完整代码如下:
# coding=utf-8
#By:Eastmount CSDN
import os
import codecs
import jieba
import jieba.analyse
#停用词表
stopwords = {}.fromkeys(['的', '或', '等', '是', '有', '之', '与',
'和', '也', '被', '吗', '于', '中', '最',
'“', '”', '。', ',', '?', '、', ';'])
source = open("test.txt", 'r')
result = codecs.open("result.txt", 'w', 'utf-8')
line = source.readline().rstrip('\\n')
content = [] #完整文本
while line!="":
seglist = jieba.cut(line,cut_all=False) #精确模式
final = [] #存储去除停用词内容
for seg in seglist:
if seg not in stopwords:
final.append(seg)
output = ' '.join(list(final)) #空格拼接
print(output)
content.append(output)
result.write(output + '\\r\\n')
line = source.readline().rstrip('\\n')
else:
source.close()
result.close()
输出结果如图7所示,得到的语料非常精炼,尽可能的反应了文本主题,其中1-3行为贵州旅游主题、4-6为大数据主题、7-9位爱情主题。

四.特征提取及向量空间模型
本小节主要介绍特征提取、向量空间模型和余弦相似性的基础知识,并用表21.1所提供的语料进行基于向量空间模型的余弦相似度计算。
1.特征规约
经过网络爬取、中文分词、数据清洗后的语料通常称为初始特征集,而初始特征集通常都是由高维数据组成,并且不是所有的特征都很重要。高维数据中可能包含不相关的信息,这会降低算法的性能,甚至高维数据会造成维数灾难,影响数据分析的结果。
研究发现,减少数据的冗余维度(弱相关维度)或提取更有价值的特征能够有效地加快计算速度,提高效率,也能够确保实验结果的准确性,学术上称为特征规约。
特征规约是指选择与数据分析应用相关的特征,以获取最佳性能,并且处理的工作量更小。特征规约包含两个任务:特征选择和特征提取。它们都是从原始特征中找出最有效的特征,并且这些特征能尽可能地表征原始数据集。
(1) 特征提取
特征提取是将原始特征转换为一组具有明显物理意义或者统计意义的核心特征,所提取的这组特征可以尽可能地表示这个原始语料。特征提取分为线性特征提取和非线性特征提取,其中线性特征提取常见的方法包括:
- PCA主成分分析方法。该方法寻找表示数据分布的最优子空间,将原始数据降维并提取不相关的部分,常用于降维,参考前面聚类那篇文章。
- LDA线性判别分析方法。该方法寻找可分性判据最大的子空间。
- ICA独立成分分析方法。该方法将原始数据降维并提取出相互独立的属性,寻找一个线性变换。
非线性特征提取常见方法包括Kernel PCA、Kernel FDA等。
(2) 特征选择
特征选择是从特征集合中挑选一组最具统计意义的特征,从而实现降维,通常包括产生过程、评价函数、停止准则、验证过程四个部分。传统方法包括信息增益(Information Gain,简称IG)法、随机产生序列选择算法、遗传算法( Genetic Algorithms,简称GA )等。
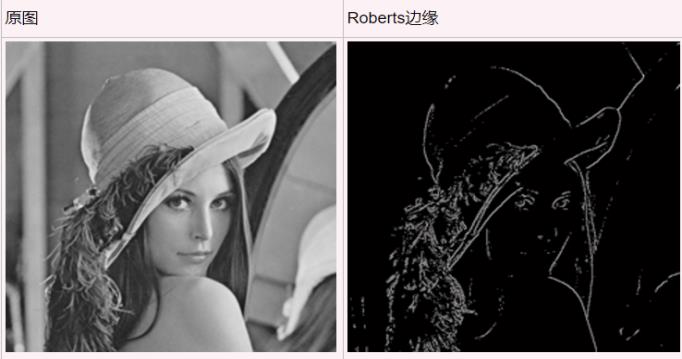
下图是图像处理应用中提取Lena图的边缘线条特征的实例,可以利用一定量的特征尽可能的描述整个人的轮廓,它和数据分析中的应用也是相同的原理。
2.向量空间模型
向量空间模型(Vector Space Model,简称VSM)是通过向量的形式来表征一个文档,它能够将中文文本转化为数值特征,从而进行数据分析。作为目前最为成熟和应用最广的文本表示模型之一,向量空间模型已经广泛应用于数据分析、自然语言处理、中文信息检索、数据挖掘、文本聚类等领域,并取得了一定成果。
采用向量空间模型来表示一篇文本语料,它将一个文档(Document)或一篇网页语料(Web Dataset)转换为一系列的关键词(Key)或特征项(Term)的向量。
- 特征项(Trem)
特征项是指文档所表达的内容由它所含的基本语言单位(字、词、词组或短语)组成,在文本表示模型中,基本语言单位即称为文本的特征项。例如文本Doc中包含n个特征项,表示为:
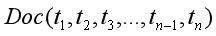
- 特征权重(Trem Weight)
特征权重是指为文档中的某个特征项ti(1≤ i ≤n)赋予权重wi,以表示该特征项对于文档内容的重要程度,权重越高的特征项越能反应其在文档中的重要性。文本Doc中存在n个特征项,即:{t1, t2, t3, … , tn-1, tn},它是一个n维坐标,接着需要计算出各特征项ti在文本中的权重wi,为对应特征的坐标值。按特征权重文本表示如下,其中,WDoc称为文本Doc的特征向量。
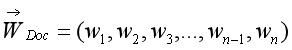
- 文档表示
得到了特征项和特征权重后,需要表示一篇文档,则利用下面这个公式。其中,文档Doc共包含n个特征词和n个权重。ti是一系列相互之间不同的特征词,i=1,2,…,n。wi(d)是特征词ti在文档d中的权重,它通常可以被表达为ti在d中呈现的频率。
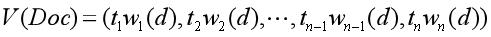
特征项权重W有很多种不同的计算方法,最简单的方法是以特征项在文本中的出现次数作为该特征项的权重,第五部分将详细叙述。
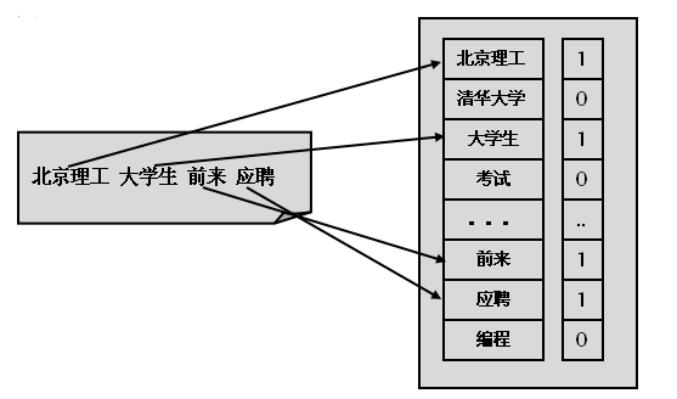
从上图可以看到,将文档存储为词频向量的过程,转换为{1,0,1,0,…,1,1,0}形式。特征项的选取和特征项权重的计算是向量空间模型的两个核心问题,为了使特征向量更能体现文本内容的含义,要为文本选择合理的特征项,并且在给特征项赋权重时遵循对文本内容特征影响越大的特征项的权值越大的原则。
3.余弦相似度计算
当使用上面的向量空间模型计算得到两篇文章的向量后,则可以计算两篇文章的相似程度,两篇文章间的相似度通过两个向量的余弦夹角Cos来描述。文本D1和D2的相似度计算公式如下:
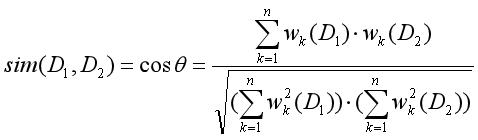
其中,分子表示两个向量的点乘积,分母表示两个向量的模的乘积。通过余弦相似性计算后,得到了任意两篇文章的相似程度,可以将相似程度越高的文档归类到同一主题,也可以设定阈值进行聚类分析。该方法的原理是将语言问题转换为数学问题来解决实际问题。
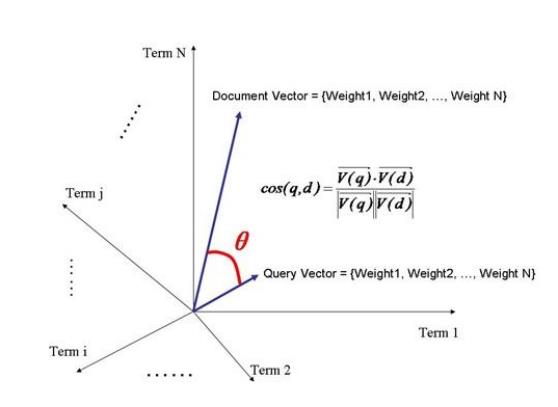
下图是向量空间模型图,它展示了文档Term1、Term2、…、TermN之间的余弦相似度计算方法,如果两篇文档越相似,则其夹角θ越小,Cos值越接近于1,当两篇文档完全相似时,此时的夹角为0°,Cos值为1。这也展示了余弦相似性的原理知识。
下面我们借用两个句子来计算其与“北京理工大学生前来应聘”的余弦相似程度。假设存在三个句子,需要看哪一个句子和“北京理工大学生前来应聘”相似程度更高,则认为主题更为类似。那么,如何计算句子A和句子B的相似性呢?
句子1:北京理工大学生前来应聘
句子2:清华大学大学生也前来应聘
句子3: 我喜欢写代码
下面采用向量空间模型、词频及余弦相似性计算句子2和句子3分别与句子1的相似性。
第一步:中文分词。
句子1:北京理工 / 大学生 / 前来 / 应聘
句子2:清华大学 / 大学生 / 也 / 前来 / 应聘
句子3: 我 / 喜欢 / 写 / 代码
第二步:列出所有词语,按照词出现的先后顺序。
北京理工 / 大学生 / 前来 / 应聘 / 清华大学 / 也 / 我 / 喜欢 / 写 / 代码
第三步:计算词频。如表所示。
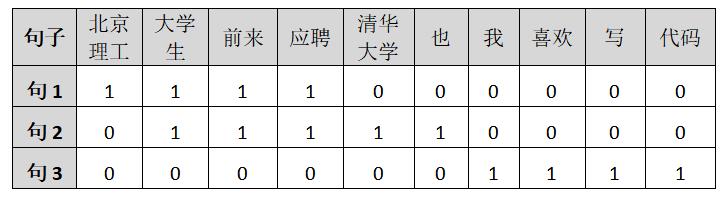
第四步:写出词频向量。
句子1:[1, 1, 1, 1, 0, 0, 0, 0, 0, 0]
句子2:[0, 1, 1, 1, 1, 1, 0, 0, 0, 0]
句子3:[0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
以上是关于[Python从零到壹] 十五.文本挖掘之数据预处理Jieba工具和文本聚类万字详解的主要内容,如果未能解决你的问题,请参考以下文章
[Python从零到壹] 六十五.图像识别及经典案例篇之图像霍夫变换详解
[Python从零到壹] 四十五.图像增强及运算篇之图像灰度非线性变换详解
[Python从零到壹] 五十五.图像增强及运算篇之图像平滑(均值滤波方框滤波高斯滤波)
[Python从零到壹] 三十五.图像处理基础篇之OpenCV绘制各类几何图形