49-文本挖掘:无案牍之劳形
Posted 苏州机器学习互助小组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了49-文本挖掘:无案牍之劳形相关的知识,希望对你有一定的参考价值。
不管多么珍惜,春天总是匆匆过去。去深圳出差,错过了苏州的樱花盛开,还好赶上杜鹃花的尾巴。现在初夏,不知一周后回苏州,是否香樟树的清香已不再,而迎接我的是热辣夏日。人在岁月流逝中总是无法从容,因人不是全知全能的,各人只能享受自己的一小份而已。再次来到帝都,风光不与去年同。在北京南站某餐馆,扬州炒饭被淡定地标为加州炒饭,我爱我家也不再家长里短地卖小区,而是云淡风轻地贴出海外置业的广告(如美国芝加哥学区房)。酒店门口的石狮子在初夏的槐荫里神清气爽,对我的一惊一乍置之一哂。如果野心不够充沛,在帝都很难活下去吧。
今天学习word2vec:一种训练词向量的方法(可以理解为特征工程中的特征降维方法之一:特征提取)。
word2vec也叫word embeddings,中文名“词向量”,作用就是将自然语言中的字词转为计算机可以理解的稠密向量(Dense Vector)。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder。
杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
宁波 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
比如上面的这个例子,在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。但是使用One-Hot Encoder有以下问题。一方面,城市编码是随机的,向量之间相互独立,看不出城市之间可能存在的关联关系。其次,向量维度的大小取决于语料库中字词的多少。如果将世界所有城市名称对应的向量合为一个矩阵的话,那这个矩阵过于稀疏,并且会造成维度灾难。
使用Vector Representations可以有效解决这个问题。Word2Vec可以将One-Hot Encoder转化为低维度的连续值,也就是稠密向量,并且其中意思相近的词将被映射到向量空间中相近的位置。
如果将embed后的城市向量通过PCA降维后可视化展示出来,那就是这个样子。
我们可以发现,华盛顿和纽约聚集在一起,北京上海聚集在一起,且北京到上海的距离与华盛顿到纽约的距离相近。也就是说模型学习到了城市的地理位置,也学习到了城市地位的关系(特征提取)。
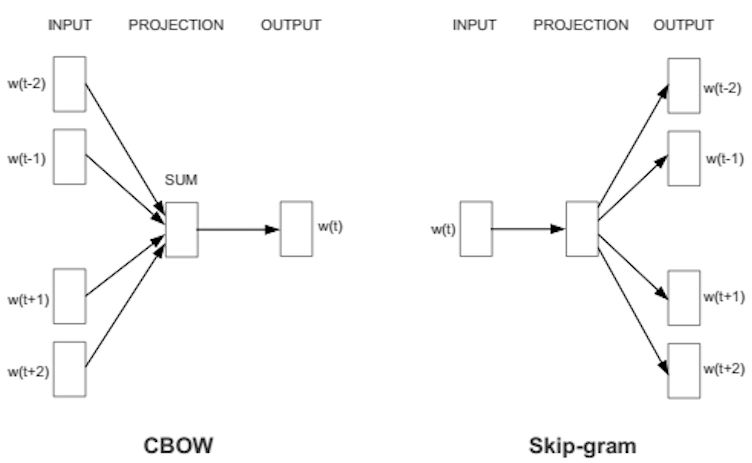
训练 Word2Vec 的思想,是利用一个词和它在文本中的上下文的词,这样就省去了人工去标注。它有 Continuous Bag-of-Words model (CBOW) and the Skip-Gram model 两种变式,前者是用一个词序列窗口中的其他词来预测中心词,后者则是用中心词来预测其他词。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
对同样一个句子:Hangzhou is a nice city。我们要构造一个语境与目标词汇的映射关系,其实就是input与label的关系。
这里假设滑窗尺寸为1:
CBOW可以制造的映射关系为:[Hangzhou,a]—>is,[is,nice]—>a,[a,city]—>nice
Skip-Gram可以制造的映射关系为(is,Hangzhou),(is,a),(a,is), (a,nice),(nice,a),(nice,city)
如果还不懂可以看这篇文章:http://www.sohu.com/a/128794834_211120。
下面看看如何在python代码中使用:

gensim 训练词向量时可以喂入一个 iterator:

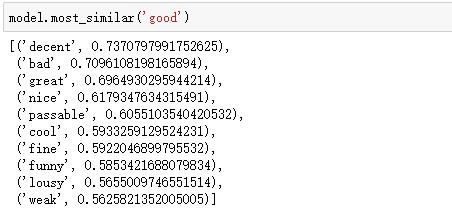
简单查看词向量的结果:
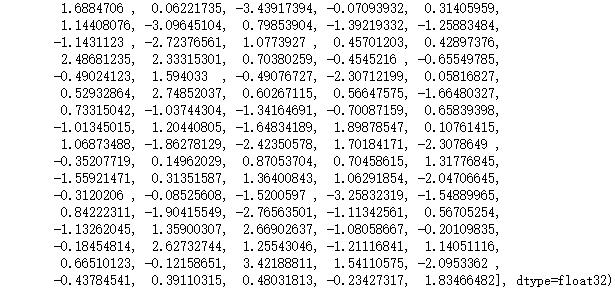
获得词对应的词向量:

存储/读取模型:

利用训练好的词向量来进行情感分析:
下周学习中文新闻分类的综合案例,敬请期待:)
以上是关于49-文本挖掘:无案牍之劳形的主要内容,如果未能解决你的问题,请参考以下文章