48-文本挖掘:无案牍之劳形
Posted 苏州机器学习互助小组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了48-文本挖掘:无案牍之劳形相关的知识,希望对你有一定的参考价值。
如果生活让我们觉得痛苦,我们应反省是否违背了自己的意志而生活。规则是外界制定的,而天性是一定要顺应的。如果我们能恰当地顺应天性,那应该没有怅然若失,也没有悒郁难受。扫清痛苦是第一步,接下来的一切都顺理成章。有时候我们应该活得像孩子,饿了吃,困了睡,高兴就笑,伤心就哭。如果我们伤心时强颜欢笑,高兴时疑虑重重,将注定是悲剧的开始。对生活本身做出真实反应,于人于己都是一件好事。保持本色生活,告别患得患失,相当于不战而胜呢:)
今天学习大规模文本挖掘的方式——在线学习及核外学习以及模型的保存。
核外学习
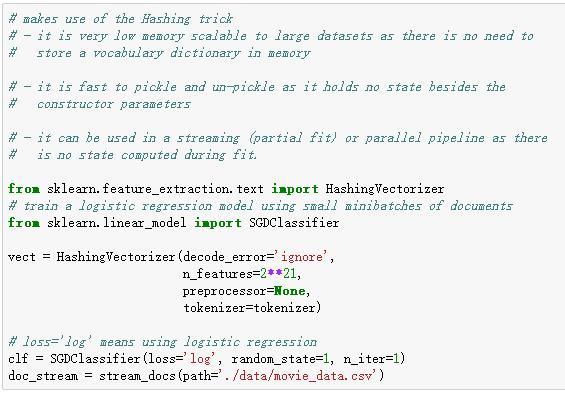
核外学习的任务是指当数据量比内存大得多时如何训练机器学习模型。需要满足以下条件:
1)有固定输出维度的特征提取层;
2)已知所有的类别(在本例中我们只有积极的和消极的评价);
3)支持增量学习的机器学习算法(如scikit-learn partial_fit方法)。
由于讲课原因,对python语法掌握十分纯熟,下面代码看起来和伪代码没什么区别,所以重复真的是智慧之母哦。


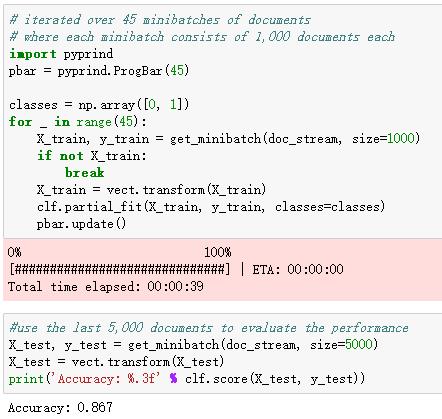
虽然准确率略低于前面(0.872),但训练速度快了很多,而且使用的内存更少。

模型保存
训练模型是昂贵并且耗时的,我们不希望在应用中每次都要重新训练模型,所以我们需要保存模型,并且能在该保存的模型上进行新的预测以及更新。
我们用 pickle 模块来储存模型,将 python object 储存为byte code,可以读取也可以写入。
如上所示,在我们训练好逻辑回归模型后,可以将分类器、停词、分词算法及HashingVectorizer转为序列化的对象保存到本地磁盘上,今后我们可以在web应用程序中使用已保存的训练好的分类器。

接下来,我们将HashingVectorizer保存为一个单独的python文件,这样方便以后直接导入该模块。
执行前面的代码块后,我们需要重新启动IPython Notebook内核,以检查对象是否正确地被序列化。
首先,将当前工作目录切换到movieclassifer文件夹:
可见分类器已被正确地序列化并被成功地用来预测新的评价文本!
下周学习word2vec(词向量模型)及中文新闻分类实例,敬请期待:)
以上是关于48-文本挖掘:无案牍之劳形的主要内容,如果未能解决你的问题,请参考以下文章