干货|详解自然语言处理之TF-IDF模型和python实现
Posted 自然语言处理技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货|详解自然语言处理之TF-IDF模型和python实现相关的知识,希望对你有一定的参考价值。
TF-IDF (term frequency-inverse document frequency)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术,比较容易理解的一个应用场景是当我们手头有一些文章时或者微博评论,我们希望计算机能够自动地进行关键词提取。而TF-IDF就是可以帮我们完成这项任务的一种统计方法。它能偶用于评估一个词语对于一个文集或一个语料库中的其中一份文档的重要程度。这个方法又称为"词频-逆文本频率"。
1. 文本向量化存在的不足
在将文本分词并向量化后,就可以得到词汇表中每个词在文本中形成的词向量,比如下面5个短文本做了词频统计:

不考虑停用词,处理后得到的词向量如下:

如果直接将统计词频后的13维特征做为文本分类的输入,会发现有一些问题。
比如第五个文本,我们可以现"come", "China" 和“Travel”各出现1次,而“to“出现了两次。似乎看起来这个文本与“to”这个特征关系更紧密。但是实际上“to”是一个非常普遍的词,几乎所有的文本都会用到,因此虽然它的词频为2,但是重要性却比词频为1的“China” 和“Travel”要低的多。如果向量化特征仅仅用词频表示就无法反应这一点,TF-IDF可以反映这一点。
2. TF-IDF原理概述
在一份给定的文件里,词频(term frequency, TF)指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
综上TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF,TF为词频,IDF反文档频率。
上面是从定性上说明的TF-IDF的作用,那么如何对一个词的IDF进行定量分析呢?这里直接给出一个词x的IDF的基本公式如下
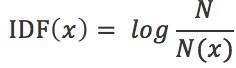
其中,N代表语料库中文本的总数,而N(x)代表语料库中包含词x的文本总数。
在一些特殊的情况下上面的公式会有一些小的问题,比如某一个生僻词在语料库中没有,则分母变为0,IDF就没有意义了,所以常用的IDF需要做一些平滑,使得语料库中没有出现的词也可以得到一个合适的IDF值,平滑的方法有很多种,小修之前为大家介绍过,最常见的IDF平滑公式之一为:
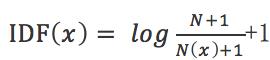
进而可以计算某一个词的TF-IDF值:
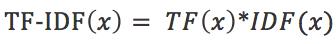
其中TF(x)是指词x在当前文本的词频。这个数字是对词数的归一化,以防止它偏向长的文件。对于某一特定文件里的词语x来说,它的重要性可表示为:
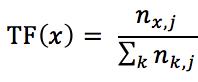
以上式子中分子为x词在第j个文件中出现的次数,而分母是在第j个文件中所有字词的出现词数之和。
3. TF-IDF算法python实现
有很多方法可以计算TF-IDF的预处理,比如genism和scikit-learn包中,这里使用scikit-learn中的两种方法进行TF-IDF的预处理
第一种方法为CountVectorizer+TfidfTransformer的组合方式进行,代码如下所示:

输出的各个词的TF-IDF值如下:
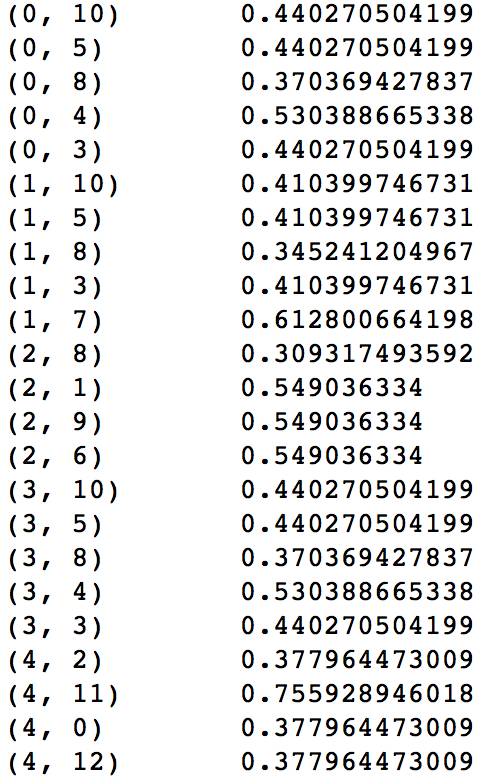
在(index1,index2)中:index1表示为第几个句子或者文档,index2为所有语料库中的单词组成的词典的序号,之后的数字为该词所计算得到的TF-IDF的结果值
第二种方法为:直接调用TfidfVectorizer,代码如下:

输出来的结果是一样的。
可以说TF-IDF是非常常用的文本挖掘的预处理的步骤,使用TF-IDF并进行标准化后,就可以使用各个文本的词特征向量作文文本的特征,进行分类或者聚类分析。
参考:
[1] 统计学习方法,李航
[2] scikit-learn 官方网站
自然语言处理技术
自然语言处理技术为您推送精品阅读
每天一个知识点,健康生活每一天
以上是关于干货|详解自然语言处理之TF-IDF模型和python实现的主要内容,如果未能解决你的问题,请参考以下文章