一文详解自然语言处理任务之共指消解
Posted 机器学习算法与自然语言处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文详解自然语言处理任务之共指消解相关的知识,希望对你有一定的参考价值。
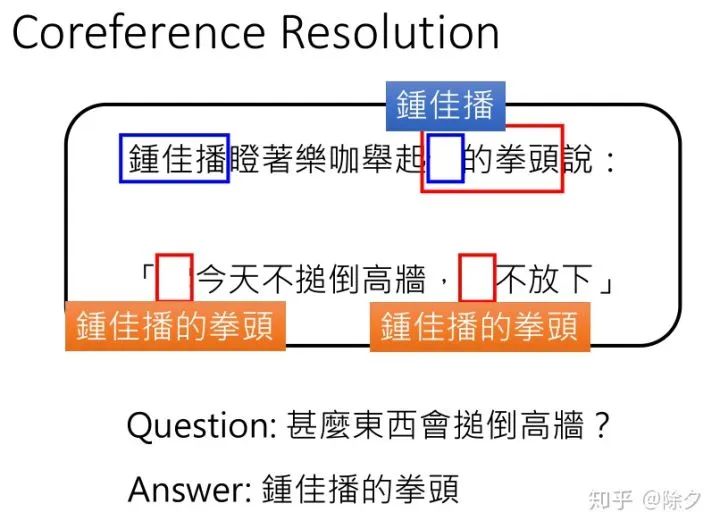
共指解析的目标是要找出文中指代相同的代指。图中的"它"指的是什么呢?它是指拳头,"他"的拳头是谁的拳头呢?指的是钟佳播的全头。如果是一个 QA 模型,它就只会从字面意思去回答问题。把会锤倒高墙的东西变成代词"它",而不是这个"它"实际指代的对象。

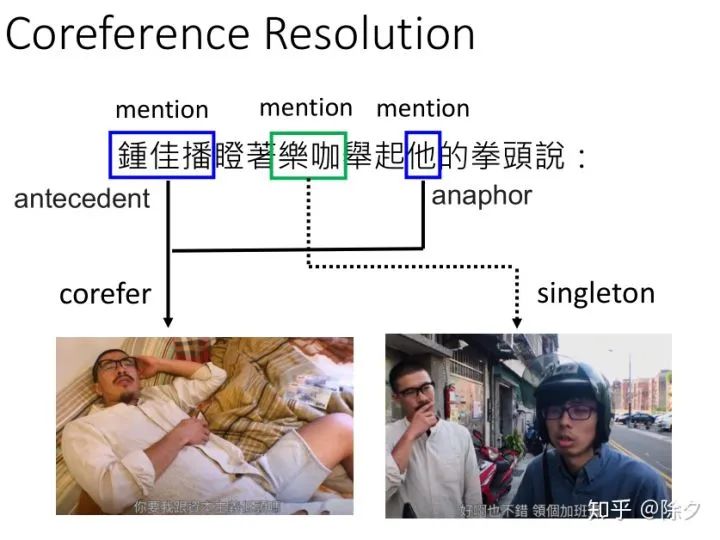

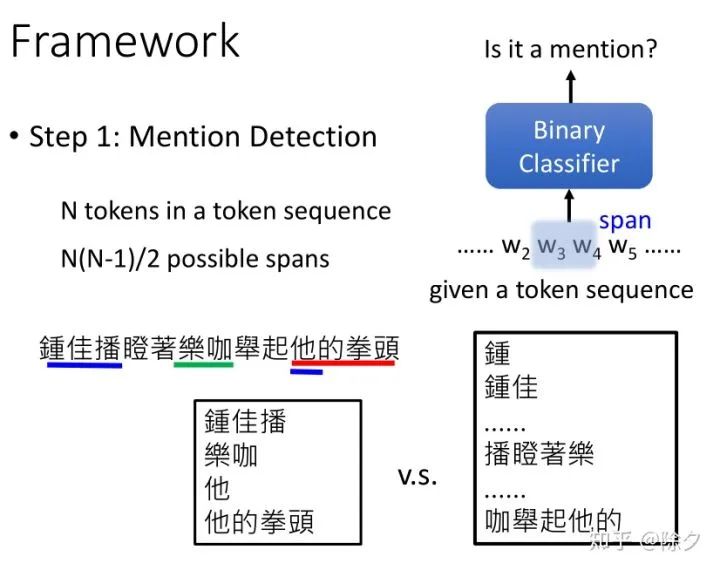
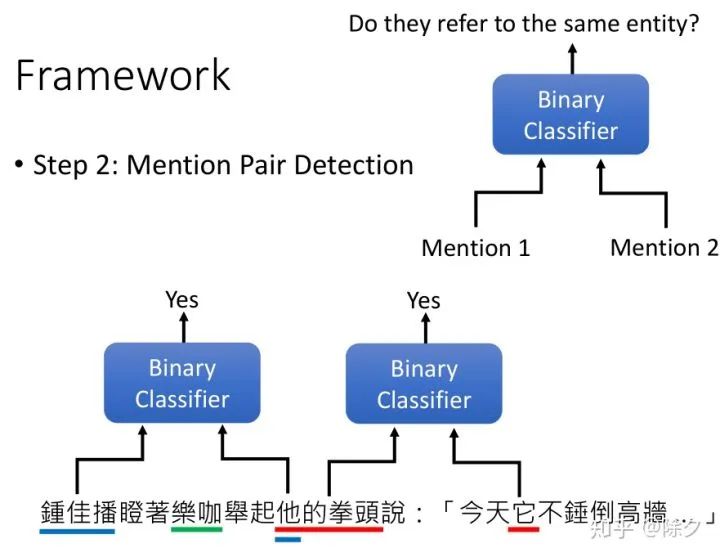
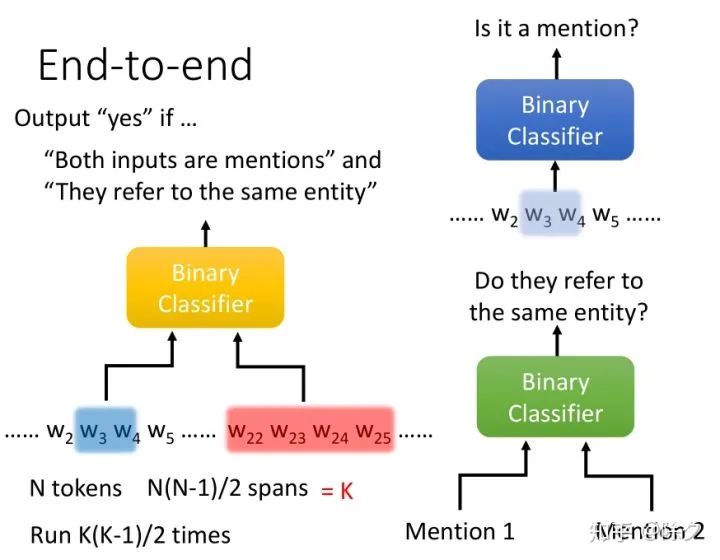
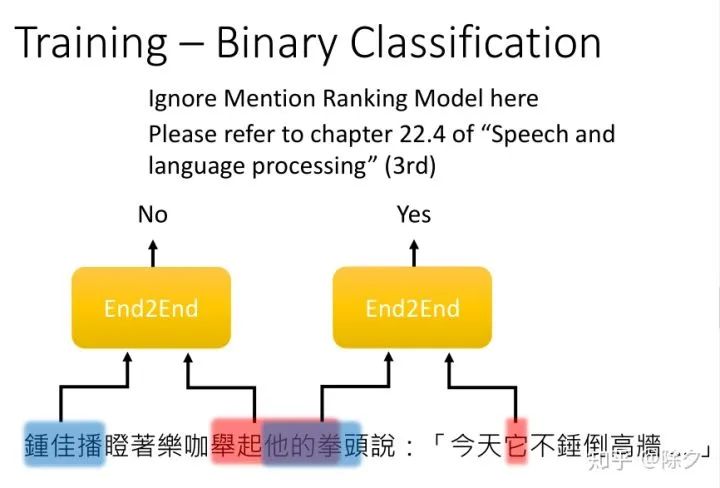
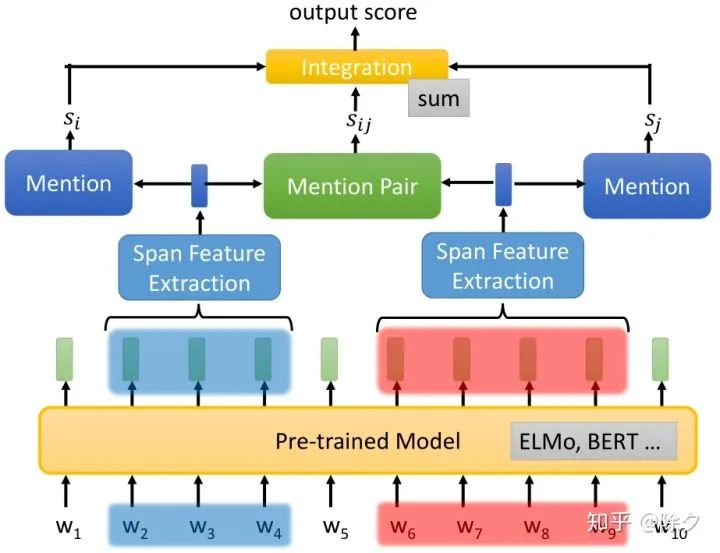
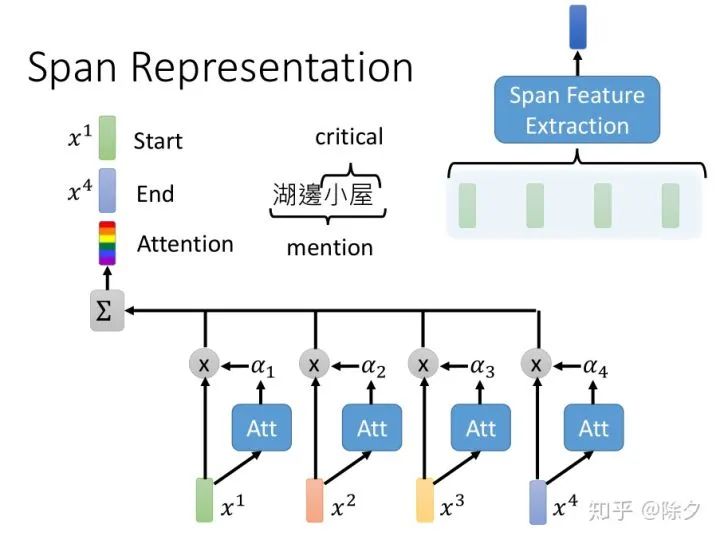
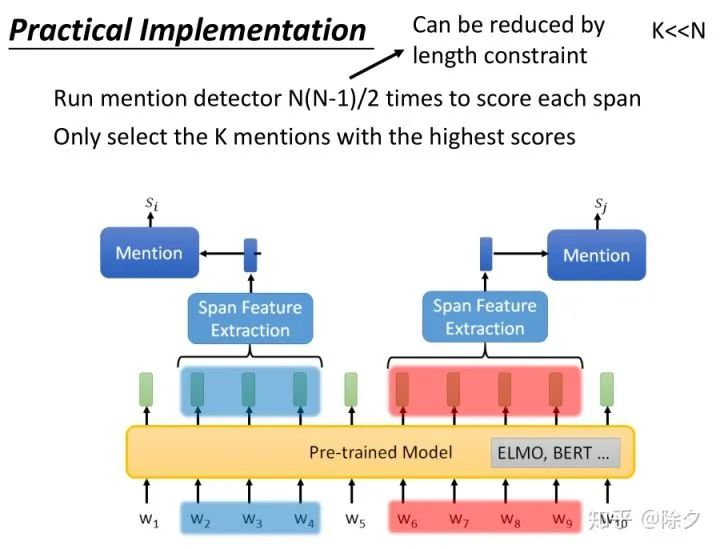


李宏毅 《人类语言处理 2020》Deep Learning for Coreference Resolution
[Lee, et al., EMNLP’17] Kenton Lee, Luheng He, Mike Lewis, Luke Zettlemoyer, End-to-end Neural Coreference Resolution, EMNLP, 2017
[Su, et al., ACL’19] Hui Su, Xiaoyu Shen, Rongzhi Zhang, Fei Sun, Pengwei Hu, Cheng Niu, Jie Zhou, Improving Multi-turn Dialogue Modelling with Utterance ReWriter, ACL, 2019
[Wu, et al., ACL’20] Wei Wu, Fei Wang, Arianna Yuan, Fei Wu, Jiwei Li, Coreference Resolution as Query-based Span Prediction, ACL, 2020
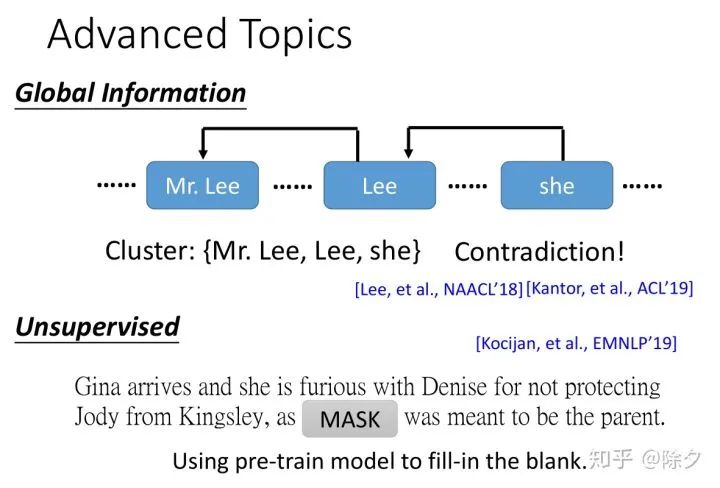
[Lee, et al., NAACL’18] Kenton Lee, Luheng He, and Luke Zettlemoyer, Higher- order coreference resolution with coarse-to-fine inference, NAACL, 2018
[Joshi, et al., EMNLP’19] Mandar Joshi, Omer Levy, Luke Zettlemoyer, Daniel Weld, BERT for Coreference Resolution: Baselines and Analysis, EMNLP, 2019
[Kantor, et al., ACL’19] Ben Kantor, Amir Globerson, Coreference Resolution with Entity Equalization, ACL, 2019
[Kocijan, et al., EMNLP’19] Vid Kocijan, Oana-Maria Camburu, Ana-Maria Cretu, Yordan Yordanov, Phil Blunsom, Thomas Lukasiewicz, WikiCREM: A Large Unsupervised Corpus for Coreference Resolution, EMNLP, 2019
重磅!忆臻自然语言处理-Pytorch交流群已成立
我们为大家整理了Pytorch中文版官方教程,
添加小助手领取,还可以进入官方交流群!
注意:请大家添加时修改备注为 [学校/公司 + 姓名 + 方向]
例如 —— 哈工大+张三+对话系统。
号主,微商请自觉绕道。谢谢!
推荐阅读:

以上是关于一文详解自然语言处理任务之共指消解的主要内容,如果未能解决你的问题,请参考以下文章
库教程论文实现,这是一份超全的PyTorch资源列表(Github 2.2K星)
一份超全的PyTorch资源列表(Github 2.2K星)