自然语言处理之词频-逆文本词频(TF-IDF)详解
Posted LSGO软件技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理之词频-逆文本词频(TF-IDF)详解相关的知识,希望对你有一定的参考价值。
1 LSGO软件技术团队
贡献人:LSGO船长
如果喜欢这里的内容,你能够给我最大的帮助就是转发,告诉你的朋友,鼓励他们一起来学习。
If you like the content here, the greatest help you can give me is forwarding, so tell your friends and encourage them to learn together.
前言
在文本挖掘预处理中,在向量化后一般都伴随着TF-IDF的处理。什么是TF-IDF,为什么一般需要加这一步预处理呢?这里就对TF-IDF的原理做一个总结。
文本向量化存在的不足
在将文本分词并向量化后,就可以得到词汇表中每个词在文本中形成的词向量,比如上篇文章中,我们将下面4个短文本做了词频统计:
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
不考虑停用词,处理后得到的词向量如下:
[[0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 1 0 0]
[0 0 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0]
[1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1]]
如果直接将统计词频后的19维特征做为文本分类的输入,会发现有一些问题。比如第一个文本,我们发现"come","China"和“Travel”各出现1次,而“to“出现了两次。似乎看起来这个文本与”to“这个特征更关系紧密。但是实际上”to“是一个非常普遍的词,几乎所有的文本都会用到,因此虽然它的词频为2,但是重要性却比词频为1的"China"和“Travel”要低的多。如果向量化特征仅仅用词频表示就无法反应这一点,TF-IDF可以反映这一点。
TF-IDF概述
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由TF和IDF两部分组成。
TF就是前面说到的词频,之前做的向量化也就是做了文本中各个词的出现频率统计。关键是后面的这个IDF,即“逆文本频率”如何理解。上面谈到几乎所有文本都会出现的"to"其词频虽然高,但是重要性却应该比词频低的"China"和“Travel”要低。IDF就是来反映这个词的重要性的,进而修正仅仅用词频表示的词特征值。
概括来讲, IDF反映一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低,比如上文中的“to”。而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。比如一些专业的名词如“Machine Learning”。极端情况是一个词在所有的文本中都出现,那么它的IDF值应该为0。
上面是从定性上说明的IDF的作用,那么如何对一个词的IDF进行定量分析呢?这里直接给出一个词x的IDF的基本公式如下:
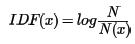
其中,N代表语料库中文本的总数,而N(x)代表语料库中包含词x的文本总数。为什么IDF的基本公式应该是是上面这样的而不是像N/N(x)这样的形式呢?这涉及到信息论相关的一些知识了(感兴趣的朋友建议阅读吴军博士的《数学之美》第11章)。
在一些特殊情况下上面的公式会有一些小问题,比如某一个生僻词在语料库中没有,则分母为0, IDF就没有意义了。所以常用的IDF我们需要做一些平滑,使语料库中没有出现的词也可以得到一个合适的IDF值。平滑的方法有很多种,最常见的IDF平滑后的公式之一为:
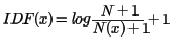
进而可以计算某一个词的TF-IDF值:
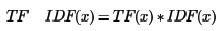
其中TF(x)指词x在当前文本中的词频。
TF-IDF实战
在scikit-learn中,有两种方法进行TF-IDF的预处理。
第一种方法是在用CountVectorizer类向量化之后再调用TfidfTransformer类进行预处理。第二种方法是直接用TfidfVectorizer完成向量化与TF-IDF预处理。
第一种方法,CountVectorizer+TfidfTransformer的组合,代码如下:
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
vectorizer=CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
print tfidf
输出的各个文本各个词的TF-IDF值如下:
第二种方法,使用TfidfVectorizer,代码如下:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
re = tfidf2.fit_transform(corpus)
print re
输出的各个文本各个词的TF-IDF值和第一种的输出完全相同。
小结
TF-IDF是非常常用的文本挖掘预处理基本步骤,但如果预处理中使用了Hash Trick,则一般就无法使用TF-IDF了,因为Hash Trick后已经无法得到哈希后各特征的IDF值。使用IF-IDF并标准化后,就可以使用各个文本的词特征向量作为文本的特征,进行分类或者聚类分析。
当然TF-IDF不只用于文本挖掘,在信息检索等很多领域都有使用,因此值得好好的理解这个方法的思想。
经过6年多的发展,LSGO软件技术团队在地理信息系统、数据统计分析、计算机视觉领域积累了丰富的研发经验,也建立了人才培养的完备体系。
本团队希望能与其他科研团队进行交流合作,并共同成长进步。
本微信公众平台长期系统化提供有关机器学习、软件研发、教育及学习方法、数学建模的知识,并将以上知识转化为实践。拒绝知识碎片化、耐心打磨技能、解决实际问题是我们的宗旨和追求。
欢迎关注,请扫描二维码:
以上是关于自然语言处理之词频-逆文本词频(TF-IDF)详解的主要内容,如果未能解决你的问题,请参考以下文章
机器学习入门-文本数据-构造Tf-idf词袋模型(词频和逆文档频率) 1.TfidfVectorizer(构造tf-idf词袋模型)
机器学习入门-文本数据-构造Tf-idf词袋模型(词频和逆文档频率) 1.TfidfVectorizer(构造tf-idf词袋模型)