知识详解+Python实现|文本挖掘中的预处理方法
Posted 数据科学DataScience
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识详解+Python实现|文本挖掘中的预处理方法相关的知识,希望对你有一定的参考价值。
在文本挖掘的预处理过程中,原始文本需要经过分词、去除标点、去停用词、向量化表示、TF-IDF处理等诸多流程,本文将专注TF-IDF矩阵的构建过程,向大家介绍Scikit-learn包中的两个将原始文档转换为TF-IDF矩阵的模块Tfidftransformer和Tfidfvectorizer。在文章中您将了解到文本的词袋模型表示、两个TF-IDF矩阵构建模块的使用及其差异,最后在中文语境下进行完成一个简单的文本预处理流程。
词袋模型是最基本的将句子转化为向量表示的模型,它不考虑句子中单词的顺序,只考虑词表(vocabulary)中单词在这个句子中的出现次数。下面给出一个词袋模型的例子:
1"the cat saw the mouse"
2 "the mouse ran away from the house"
对于这两个句子,我们要用词袋模型把它转化为向量表示,这两个句子形成的词表为:
1['away', 'cat', 'from', 'house', 'mouse', 'ran', 'saw', 'the']
则其对应的词袋模型向量为:
1 ['away', 'cat', 'from', 'house', 'mouse', 'ran', 'saw', 'the']
2s1 = [ 0 1 0 0 1 0 1 2 ]3s2 = [ 1 0 1 1 1 1 0 2 ]
在scikit-learn中的CountVectorizer()函数实现了BOW模型,具体实现步骤包括:
首先我们对CountVectorizer进行初始化,均使用其默认参数(默认会将所有单词转为小写、去除单字符单词等)。在实际使用过程中也可以传入stopword参数自定义停用词列表,min_df参数限制最小词频,ngram_range 参数考虑词组等进行个性化设置。
之后CountVectorizer对输入的所有文档生成词表,并计算每一个文档中各个单词出现的次数,即完成词袋模型BOW的构建,输出5行(5个文档)6列(16个唯一单词,默认排除单字符单词‘a’)的矩阵。
最后,可以通过类函数get_feature_names()访问生成的词表,以及输出生成的词频矩阵。也可以传入全新的文档进行文本向量的构建,但限于test、doc、string等单词不在词表中,生成的向量会产生误差,实际情况若在大量文本中构建词表,全新文档的向量构建会更精确。
1import pandas as pd
2from sklearn.feature_extraction.text import CountVectorizer
3docs=["The house had a tiny little mouse",
4 "the cat saw the mouse",
5 "the Mouse ran away from the house",
6 "the cat finally ate the mouse",
7 "the end of the mouse story"
8 ]
9# 调用CountVectorizer生成文档-词频矩阵
10cv = CountVectorizer()
11word_count_vector = cv.fit_transform(docs)
12# 输出矩阵维度
13print(word_count_vector.shape)
14# 输出提取的词表
15print(cv.get_feature_names())
16# 输出各个文档的词频向量
17print(word_count_vector.toarray())
18# 用已有的CountVectorizer计算全新的文档
19print(cv.transform(['the test doc string']).toarray())
输出结果如下:
1(5, 16)
2['ate', 'away', 'cat', 'end', 'finally', 'from', 'had', 'house', 'little', 'mouse', 'of', 'ran', 'saw', 'story', 'the', 'tiny']
3[[0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 1]
[0 0 1 0 0 0 0 0 0 1 0 0 1 0 2 0]
[0 1 0 0 0 1 0 1 0 1 0 1 0 0 2 0]
[1 0 1 0 1 0 0 0 0 1 0 0 0 0 2 0]
[0 0 0 1 0 0 0 0 0 1 1 0 0 1 2 0]]
4[[0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0]]
第一部分我们构建了词袋模型BOW,能够简便的将文本转换为向量,但其也存在一定的缺点,如没有考虑单词之间的顺序,无法确定关键词等。词袋模型仅能够根据高频词来确定关键词,TF-IDF方法通过逆文本频率对词频进行加权处理,在关键词识别上有一定的进步。
TF(Term Frequency,词频)的公式为:
IDF(inverse document frequency,逆文本频率)的公式为(分母加1防止除零错误):

TF-IDF的公式为:
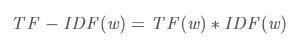
在scikit-learn中的Tfidftransformer()和TfidfVectorizer()函数实现了TF-IDF模型。Tfidftransformer()函数需要输入上文生成的文档-词频矩阵(即词袋模型的结果),具体实现步骤如下:
1# 初始化TfidfTransformer
2tfidf_transformer = TfidfTransformer(smooth_idf=False, use_idf=True)
3# 输入词袋模型矩阵word_count_vector计算IDF
4tfidf_transformer.fit(word_count_vector)
5# 计算TF-IDF
6count_vector = cv.transform(docs)
7tf_idf_vector = tfidf_transformer.transform(count_vector)
8# 计算第一个文档的TF-IDF值,并降序打印
9feature_names = cv.get_feature_names()
10first_document_vector = tf_idf_vector[0]
11df = pd.DataFrame(first_document_vector.T.todense(), index=feature_names, columns=["tfidf"])
12df.sort_values(by=["tfidf"], ascending=False)[:8]
Tfidftvectorizer()函数的使用要简单的多,代码也要短的多,可以一次性计算词频、IDF和TF-IDF值,具体实现步骤如下:
1# 初始化TfidfVectorize,传入原始文档集并计算TF-IDF
2from sklearn.feature_extraction.text import TfidfVectorizer
3tfidf_vectorizer = TfidfVectorizer()
4tfidf_vectorizer_vectors = tfidf_vectorizer.fit_transform(docs)
5# 降序打印第一个文档的TF-IDF值
6first_vector_tfidfvectorizer = tfidf_vectorizer_vectors[0]
7df = pd.DataFrame(first_vector_tfidfvectorizer.T.todense(), index=tfidf_vectorizer.get_feature_names(), columns=["tfidf"])
8df.sort_values(by=["tfidf"], ascending=False)[:8]
9# 也可以分别调用fit和transform来实现TFIDF的方法
10tfidf_vectorizer = TfidfVectorizer()
11fitted_vectorizer = tfidf_vectorizer.fit(docs)
12tfidf_vectorizer_vectors = fitted_vectorizer.transform(docs)
Tfidftransformer与Tfidftvectorizer最后的输出结果均如下所示。可以看到只有部分单词有TF-IDF得分,是因为第一个文档本身出现的单词都具有TFIDF得分,但在集合中出现的其他词也被列出来,得分为零。就我们的第一个文档而言,其TD-IDF得分具有明显的意义,跨文档的单词越普遍,其得分越低(如little、tiny),单词越独特,得分就越高(如the、mouse)。
03
Tfidftransformer VS. Tfidfvectorizer
两个函数之间的主要区别如下:
(1)使用Tfidftransformer时,需要先使用CountVectorizer计算词频,然后再计算逆文档频率(IDF)值,最后得到TD-IDF值。
(2)使用Tfidfvectorizer时,我们可以一次性完成三个步骤,其在后台使用相同的数据集计算词频,IDF值和TF-IDF值。
如何挑选使用的函数:
(1)如果需要在接下来的任务中继续使用词频向量时,请使用Tfidftransformer。
(2)如果仅需要在“训练”数据集中的文档上计算TF-IDF时,请使用Tfidfvectorizer。
(3)如果您需要在“训练”数据集之外的文档上计算TF-IDF时,请使用任意一个,两者都可以。
04
中文处理流程
1# 构建中文文档集
2docs=["如果需要在不同任务中使用词频(术语计数)向量时,请使用Tfidftransformer",
3 "如果需要在“训练”数据集中的文档上计算tf-idf分数时,请使用Tfidfvectorizer。",
4 "如果您需要在“训练”数据集之外的文档上计算tf-idf分数时,请使用任意一个,两者都可以。"]
5# 文本预处理流程
6# 构建停用词、中英文标点列表
7stop_word_list = ['的','呀','这','那','就','的话','如果']
8import string
9punctuation_list = list(string.punctuation+'.,;《》?!“”‘’@#¥%…&×()——+【】{};;●,。&~、|s::')
10stop_word_list.extend(punctuation_list)
11# 分词:中文jieba包 英文nltk包
12# TF-IDF中文输入文档格式应与英文保持一致,用空格连接分词结果,如["今天 天气 很好","明天 去 打球"]
13import jieba
14docs_token = []
15for doc in docs:
16 docs_token.append(" ".join([word for word in jieba.lcut(doc) if word not in stop_word_list]))
17
18# CountVectorizer
19cv = CountVectorizer()
20word_count_vector = cv.fit_transform(docs_token)
21# TfidfTransformer
22tfidf_transformer = TfidfTransformer().fit(word_count_vector)
23# 计算TF-IDF
24count_vector = cv.transform(docs_token)
25tf_idf_vector = tfidf_transformer.transform(count_vector)
26# 计算第一个文档的TF-IDF值,并降序打印
27feature_names = cv.get_feature_names()
28first_document_vector = tf_idf_vector[0]
29df = pd.DataFrame(first_document_vector.T.todense(), index=feature_names, columns=["tfidf"])
30df.sort_values(by=["tfidf"], ascending=False)
31
32# TfidfVectorizer
33tfidf_vectorizer = TfidfVectorizer()
34tfidf_vectorizer_vectors = tfidf_vectorizer.fit_transform(docs_token)
35first_vector_tfidfvectorizer = tfidf_vectorizer_vectors[0]
36df = pd.DataFrame(first_vector_tfidfvectorizer.T.todense(), index=tfidf_vectorizer.get_feature_names(), columns=["tfidf"])
37df.sort_values(by=["tfidf"], ascending=False)
输出结果如下(部分截取):
原文作者:Kavita Ganesan
原文标题:How to Use Tfidftransformer & Tfidfvectorizer?
原文来源:https://kavita-ganesan.com/tfidftransformer-tfidfvectorizer-usage-differences
原文代码:https://github.com/kavgan/nlp-in-practice/tree/master/tfidftransformer
注:本文经师兵范和朝乐门进行了补充、扩展、翻译、排版和校对。
以上是关于知识详解+Python实现|文本挖掘中的预处理方法的主要内容,如果未能解决你的问题,请参考以下文章