「算法笔记」一文摸秃二分查找
Posted 梅川酷子的裤子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「算法笔记」一文摸秃二分查找相关的知识,希望对你有一定的参考价值。
0、引言
经过一段时间的算法学习,我们觉得从二分查找开始再合适不过。
对于二分查找,你是否也对循环条件该怎么写产生焦虑,是否也对要分奇数偶数情况讨论感到抓狂,是否纠结于取mid时到底是向下取整还是向上取整。
别慌,我们和你一起仔细分析二分查找,从二分查找到经典代码到两种变种再到大一统代码,争取吃透二分查找,让天下没有难写的算法。
本文结构:
·什么是二分查找
·二分查找的通用代码以及为什么这么写
·二分查找的应用场景
·本节精简小抄以及所关联的leetcode题号
1、什么是二分查找
我们先讲个通俗易懂的故事。
这天,室友回到宿舍给你展示他新买的AirPods,并让你猜多少钱,你说:“那官网不都写了吗,1246”。室友摇摇头说高了,你再给个数,623。室友说:“怎么可能啊兄弟,我这新的,你搁这腰斩呢。”你没好气的回复道:“623也不是,1246也不是,这中间从623到1246总共622个价格,全部猜一遍猜到天亮吗,劳资还要打王者。”
室友笑道:“小笨蛋,你不会用二分查找吗?你先猜一半,再猜一半,再猜一半...” 你悟了,先猜 (623 + 1246) / 2 = 934。室友:”高了“。你再猜(934 + 623) / 2 = 778.5。室友摸了摸你的小脑袋:“真聪明,几下就猜中了呢。”
如你所见,这种每次取一半去猜答案,多了就减,少了就加的方法就是二分查找。如果傻乎乎的从1,2,3,4,5...开始遍历查找,要查到猴年马月?
二分查找的思路很简单,但写起来却有诸多的细节可供把玩品味。引用KMP算法发明者的一句话:Although the basic idea of binary search is comparatively straightforward, the details can be surprisingly tricky(虽然二分查找的思路很简单,但是细节要你命)。
看客们若想理解性记忆把控这些细节,请随着我们的思路往下走。
2、通用代码以及Why
def binarySearch(nums, target):left = 0right = len(nums) - 1 #-------1while left <= right: #-------2mid = left + (right - left) // 2 #-------3if nums[mid] == target:return midelif nums[mid] < target:left = mid + 1 #-------4elif nums[mid] > target:right = mid - 1 #-------4return -1
#1:
让left = 0, right = len(nums) - 1实际上是把二分搜索的索引区间限制在闭区间[left, right]。
比如对于数组nums=[2,3,5,6,10,11,12,13,15]来说,这样的写法对应的搜索索引区间就是[0,8]。
当然,你可能会经常忘记写“-1”,而写成“right = len(nums)”,此时对应的搜索索引区间就是左闭右开区间 [left, right),也即[0,9),注意,是一个右括号。这种写法不是不行,但后续的代码要做出对应的修改,后文会讲。
#2:
left <= right的终止条件是left = right + 1,这很好理解。那如果我忘了写等于号,写成”left < right“,那对应的终止条件是什么呢?
对,就是left = right。那这有什么含义上的区别呢?很简单,画个图你就明白了。
对于[left, right]这种闭区间的情况,在终止条件是left = right + 1,最终搜索结束时,左右指针停留如图所示:
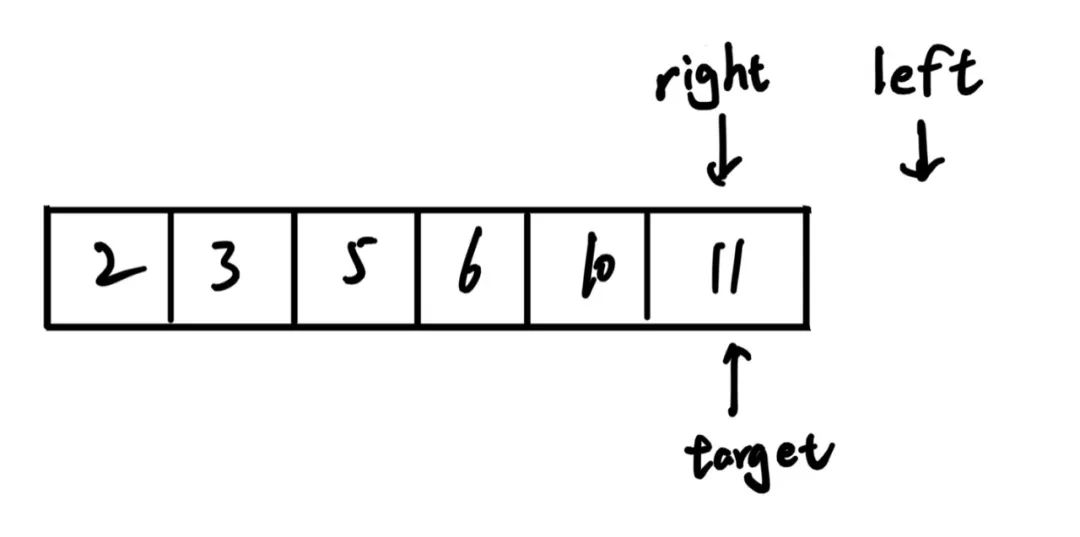
可见,结束时,左右指针可以遍历完数组中的所有元素,二分搜索正确运行。
在终止条件是left = right,最终搜索结束后,左右指针停留如图所示:
可见,在循环结束时,还剩index = left = right这一个索引指向的元素没有被查看,二分搜索漏元素了!
此时,细心的读者会问,那我采用刚刚的[left, right)写法,结合这个left = right的终止条件,不就能遍历数组中的所有元素了嘛?
嘿,我要摸摸你的小脑袋,真聪明。没错,这是对的。在这种情况下,沿用刚刚例子中的数组nums,则此时的right=9,搜索的索引区间为[0,9),那最后停止时,left = right = 9,也就遍历完了索引为0,1,2,3,4,5,6,7,8的元素,即nums中的所有元素,二分搜索算法得以正常运行!
#3:
取中点值的标准写法,这必须记住。因为直接写成mid = (left + right) // 2会导致溢出。
#4:
很好理解,因为我们的初始搜索区间是[left, right],算出mid,且mid不是我们要的target后,下一个搜索区间是[left, mid - 1] 和 [mid + 1, right]。不包含mid是因为mid已经被检验过了,不是我们想要的答案。那么,显而易见,当mid大于target时,要让 right = mid - 1以进入mid左边的搜索区间。相应的,当mid大于target时,要让left = mid + 1以进入mid右边的搜索区间。
至此,经典的二分搜索算法我们已经剖析完成。但这个算法已经完美了吗?
具体而言,对于nums = [1,2,2,2,3,4]的情况,含有多个重复元素,且2刚好就是我们要找的target。那此时题目要我返回最左边的2,该怎么办?要我返回最右边的2,又该怎么办?
根据这种差别,我们将二分搜索算法分为“最左目标二分查找”,以及“最右目标二分查找”。
2.1 最左目标二分查找
按惯例,先上标准代码:右划查看注释
def binarySearch(nums, target):left = 0right = len(nums)while left < right:mid = left + (right - left) // 2if nums[mid] == target:right = mid #--------1elif nums[mid] < target:left = mid + 1elif nums[mid] > target:right = mid #--------2return right
#1:
可以注意到,标准代码采取了左闭右开区间[left, right)和终止条件left = right的写法。这段代码之所以能找到最左目标,精髓就在这个#1,每次找到target进行更新时,mid都将区间分为”[left, mid), mid, [mid + 1, right)”,令right = mid就可以顺利的进入左边的区间。
更形象的,这个”mid)” 就像卡身位一样将搜索卡入左边的搜索区间。同理,若mid不等于(或大于)我们要找的target,也是将区间通过”mid)”的写法卡入左边更小的搜索区间。
更更详细一点,有读者可能还是想问这里为什么不像上一段代码一样写成right = mid - 1。好,那我们假设#1改成right = mid - 1,那每次更新时,搜索区间就会被划分成[left, mid - 1), mid , [mid + 1, right)。注意,“mid - 1)” 和“mid”之间还有一个”[mid - 1]” 没有被检验过,因此就出现了漏检的情况。
读者理解了#1处,也就很容里理解#2处了。
#*:
有人可能会问,我能不能用 right = len(nums) - 1, 终止条件: left = right + 1的写法来写最左目标二分查找呢。
先说结论,经过我们的尝试,建议不要这样做。那我们一起看看这样做会出现什么情况。代码如下:右划查看注释
def binarySearch(nums, target):left = 0right = len(nums) - 1while left <= right:mid = left + (right - left) // 2if nums[mid] == target:right = mid #--------1elif nums[mid] < target:left = mid + 1elif nums[mid] > target:right = mid #--------2return right
如果读者亲自运行这段代码就会发现,最后会一直死循环。
原因很简单,因为每次更新,mid将搜索区间划分成[left, mid], [mid + 1, right]。当循环到到后面,搜索区间就会变成[left, 最左target(也等于mid等于right)],因为mid = left + (right - left) // 2向下取整,所以mid取到挨着最左target的左边的值(其实此时,mid和left取值相同),此值小于最左target,根据第9行代码,此时left要+1。这就是问题所在,这left + 1不就等于right,不就等于最左target了嘛?那我的下一个mid不就是 (自己+自己) / 2还等于自己,那mid也不更新,right也不更新,left也不更新,也就是left永远<=right,跳不出循环。
所以,我们不介意这么写。
2.2 最右目标二分查找
废话不多说,上代码:右划查看注释
def binarySearch(nums, target):left = 0right = len(nums)while left < right:mid = left + (right - left) // 2if nums[mid] == target:left = mid + 1 #--------1elif nums[mid] < target:left = mid + 1elif nums[mid] > target:right = midreturn left - 1 #--------2
#1:
同样的,能让这段代码找到最右target的精髓也在此处。如我们在最左目标查找中分析的那样,每次更新时,mid将搜索区间划分成[left, mid), mid ,[mid + 1, right)。当mid小于或等于我们的target时,要让left = mid + 1才能顺利的进入右边的搜索区间,去不断的寻找最右target。但!也正是因为left = mid + 1,所以才会出现#2处这样的代码。放在下一段分析。
#2:
仔细想想,当mid = 最右target时,我们又让left = mid + 1,此时left = right,循环终止。但left已经指向了最右target的下一个元素,因此要返回left - 1。
2.3 大一统二分查找
经过上面三种代码的熏陶,你是否已经所有所思,但还是感觉记忆起来需要费点儿劲,需要分清楚while的终止条件,还要分清楚right什么时候等于len(nums)什么时候等于len(nums) - 1。没关系,我们在此给出一种万能代码。
查找目标:右划查看注释
def binarySearch(nums, target):left = 0right = len(nums) - 1while left + 1 < right:mid = left + (right - left)//2if nums[mid] == target:return midelif nums[mid] < target:left = midelif nums[mid] > target:right = midif nums[right] == target:return rightif nums[left] == target:return leftreturn -1
最左目标查找:右划查看注释
def binarySearch(nums, target):left = 0right = len(nums) - 1while left + 1 < right:mid = left + (right - left)//2if nums[mid] == target:left = midelif nums[mid] < target:left = midelif nums[mid] > target:right = midif nums[right] == target:return rightif nums[left] == target:return leftreturn -1
最右目标查找:右划查看注释
def binarySearch(nums, target):left = 0right = len(nums) - 1while left + 1 < right:mid = left + (right - left)//2if nums[mid] == target:right = midelif nums[mid] < target:left = midelif nums[mid] > target:right = midif nums[left] == target: #-------1return leftif nums[right] == target: #-------2return rightreturn -1
代码很统一,读者到这里应该能理解,这种写法的搜索区间是闭区间[left, right],那么终止条件是什么呢?
没错,就是left + 1 = right,当循环终止时,left和right挨着,这其中的一个就是我们想要的答案,无论是单纯的目标,最左目标还是最右目标。需要注意的是,当循环结束时,多做了两个判断#1和#2。画个图来告诉你为什么要多两个判断(以最右目标查找为例):
如图所示,最后终止时,left和right指针无论是如黑色所示还是如红色所示,其中之一指向的就是我们要的target,那么我们按从右向左的顺序,即先判断right再判断left,不就可以找出最右的目标了嘛。这样看来,最左目标查找的写法是不是也一目了然?
虽然大一统代码很容易记忆,但面试中遇到二分查找,考察的恰恰就是这些细节问题。因此,不能光记忆大一统代码,前面的代码也要做到能自由切换。
3、应用场景
二分查找最明显的特点就是将搜索的复杂度从遍历搜索O(n)降到O(logn),要知道,logn是一个非常牛逼的数量级。比如2的32次方,大概等于42亿,如果遍历的话,要算到哪年去?但使用logn,也就是算32次而已。
二分查找只是一种折半的思想,通过我们的刷题观察,凡是题目中对时间复杂度出现logn的要求,都可以应用这种折半思想。由此可见,二分查找的应用十分广泛,这也是为什么我们从二分查找开始。
但需要注意的是,二分查找只适用于顺序表,也就是数组,且应用于有序(递增or递减)的数据。
4、精简小抄及leetcode
笔记至此,我们能完全掌握二分查找了。一起到leetcode拿下对应的习题吧:
leetcode:35. 搜索插入位置
leetcode:34. 在排序数组中查找元素的第一个和最后一个位置
如果你觉得我们的文章还不错的话,不妨点个关注收藏转发什么的,你的支持就是我们坚持开源,免费,的最大动力,感谢 以上是关于「算法笔记」一文摸秃二分查找的主要内容,如果未能解决你的问题,请参考以下文章