链表和有序二叉树插入元素时真的比数组快吗?
Posted 脚本之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了链表和有序二叉树插入元素时真的比数组快吗?相关的知识,希望对你有一定的参考价值。
脚本之家
你与百万开发者在一起



公司有位C++标准委员会的顾问大佬,一年会有几次视频讲座,分享一些编程要点或者经验。很多时候都是C++很基础的方面,但是他的讲解视频真的很深入浅出,有时候会“打破”一些理所应当的观点,这篇文章就是让我觉得很有趣,并且意想不到的地方,在这里分享一下。
1. 非关联容器
std::vector
和
std::list
。在后续的说明中,所有的实验都是基于这两个容器,但是其适用于任何基于节点的数据结构,不只是C++标准库中的。开始之前,都知道这两种数据结构在内存的中的存储形式是不同的,数组在内存中地址是连续的,链表的内存地址是非连续的(如下图)。
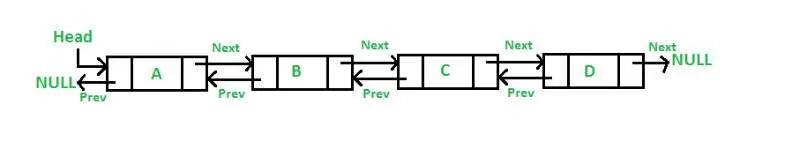
在数组中插入一个元素,需要将插入位置后面的元素向后移动,时间复杂度是O(N);但是向双向链表中插入一个元素需要分配一个节点,并设置4个指针,时间复杂度是O(1)。自然,对于很大的常数N,在链表中插入要快速的多。
读取元素比较
对于这两种容器,按顺序读取所有元素的时间复杂度是O(N)。但是,数组的读取速度仍旧比链表快。缓存(cache)和预取(prefetch)机制对数组读取是有利的,但是对链表的读取没有任何帮助。
从理论上来说,以上的说法是正确的,但在现代计算机上,真正的性能是如何的?我们可以通过实验来验证,通过不停地修改N的值,该程序可以得到在数组和双向链表的中间值右边插入数值0所消耗的时间。所用机器配置如下图:
#include<iostream>#include<vector>#include<list>#include<algorithm>#include<random>#include<ctime>usingnamespace std;constsize_t N = 50000;int main(){doublestart_t, end_t;std::vector<size_t> vec(N);std::list<size_t> lst(N);//The vector and list has same N elementsfor(size_t i = 0; i < vec.size(); ++i){vec[i] = i + 1;lst.push_back(i + 1);}//insert 100 right before the the first occurence of 3start_t= clock();vec.insert(std::find(vec.begin(), vec.end(), 3), 100); //Tvend_t= clock();std::cout << "vector cost time: "<< ((end_t- start_t) * 1000000) << " ns"<< std::endl;start_t= clock();lst.insert(std::find(lst.begin(), lst.end(), 3), 100); // Tlend_t= clock();std::cout << "list cost time: "<< ((end_t- start_t) * 1000000) << " ns"<< std::endl;return0;}
很明显,这样的线性搜索对于两种容器来说都是O(N),正如我们已经看到的,向vector插入一个元素是一个O(N)操作,向list插入一个元素是O(1)操作。向数组插入元素时,把少量的元素向右移动代价是很小的,毫无疑问应该期待Tv < Tl;但是当N是多少时,移动元素的代价会使Tl < Tv? 应该存在这样的一个临界值N。下面的表格是插入元素的实验结果:
| Size | std::vector | std::list | list/vector |
|---|---|---|---|
| 10000 | 0ns | 0ns | null |
| 50000 | 0ns | 1e+06ns | null |
| 100000 | 0ns | 2e+06ns | null |
| 1000000 | 6e+06ns | 2.1e+07ns | 3.5 |
| 10000000 | 5.5e+07ns | 2.03e+08ns | 3.69 |
| 100000000 | 5.79e+08ns | 2.169e+09ns | 3.746 |
| 500000000 | 3.6342e+10ns | 2.7049e+11ns | 5.638 |
我们发现,没有这样的一个临界值N,使得在双向链表中插入元素比数组快。线性内存访问模式会使用CPU的pre-fetcher,其作为一个无限大小的LN+1缓存。但是指针节点的数据结构没有这点好处,所以总是更慢一点。所以,如果你的关心迭代速度,就不要使用基于节点的容器,大多数情况下,程序更关注迭代速度。实际上,不管是插入或者删除操作,当你试图去寻找正确的位置,这时程序就需要迭代。所以,一般不要使用链表。
但是,在写程序时,总是会有适合链表的时刻(虽然很少):
1.用分离链表法去解决hash冲突的时候,对于相同的hash key值,使用链表来存储,将新的节点插入链表的头部;2.如果需要引用稳定性,则可能需要一个链表,因为节点不会移动。如果指向一个节点,并对除了所指向的节点之外的任何内容执行插入或擦除操作,该指针将保持有效。3.实现一个软件LRU或MRU缓存,通常使用链表,并有指针指向缓存的所有元素。当使用其中一个时,将其从链表中拉出,并将其放在开头或结尾。
别的一般情况下,相比std::list,更倾向于选择std::array和std::vector。
2. 关联容器
“关联容器”是一个来自c++标准的术语。关联容器通常称为映射或字典。它们将一组键一对一地关联到一组值上。换句话说,您可以将一个键及其关联值插入到容器中,然后通过传递该键请求该值。在C++ STL中,包括std::map和std::set。这两个容器都以红黑树的方式实现,因此可以按照键排序的顺序遍历元素。
std::map is a sorted associative container that contains key-value pairs with unique keys. Keys are sorted by using the comparison function Compare. Search, removal, and insertion operations have logarithmic complexity. Maps are usually implemented as red-black trees.
从c++ 11开始,还有散列关联容器std::unordered_map和std::unordered_set。顾名思义,这些元素没有按顺序排列。
这里,我们讨论有序的,其底层结构是红黑树的容器,内存存储结构如下图:
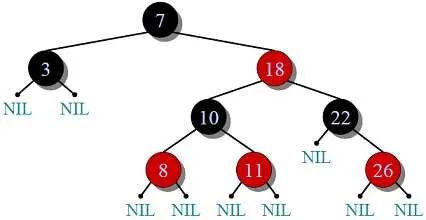
在有序数组和树中,查找一个特定值的时间复杂度是O(log(N)),并且由于在任何二叉搜索中都要在内存中跳跃,所以数组的速度并没有加快。
将一个元素插入到已排序的数组中需要先进行搜索,然后再进行插入(包括将后面的所有元素后移),时间消耗为O(log(N) + N)或者说O(N)。插入到树中需要搜索、分配,可能还需要重新平衡树,时间复杂度是O (log (N))。对于较大的N,在树中插入自然要快得多。
需要注意的是,由于插入时间的xx性,填充一个排序数组是O(N * N),填充红黑树是O(N * log(N))。对于两个容器,按顺序读取所有元素的时间是O(N)。同样,读取数组中的值要快得多。事实上,树中的迭代速度甚至比链表中的还要慢。下面的测试代码是基于vector_vs_map稍作改动。
#include<iostream>#include<map>#include<vector>#include<algorithm>#include<ctime>constsize_t N = 1000000;volatilesize_t acc = 0;typedef std::vector<std::pair<size_t, size_t>> vecss;typedef std::map<size_t, size_t> mapss;struct firstPairComp{booloperator()(const vecss::value_type& lhs, const vecss::value_type& rhs){return lhs.first < rhs.first;}};void insert_in_vec(const std::vector<size_t>& orderVec){vecss vals;vals.reserve(N);doublestart_t, end_t;start_t= clock();for(size_t i = 0; i < N; ++i){vecss::value_type val(orderVec[i], rand());std::pair<vecss::iterator, vecss::iterator> res =std::equal_range(vals.begin(), vals.end(), val, firstPairComp());vals.insert(res.second, val);}end_t= clock();std::cout << "vector insert cost time: "<< ((end_t- start_t) * 1000000) << " ns"<< std::endl;}void find_in_vec(const std::vector<size_t>& orderVec){vecss vals;vals.reserve(N);for(size_t i = 0; i < N; ++i){vecss::value_type val(orderVec[i], rand());std::pair<vecss::iterator, vecss::iterator> res =std::equal_range(vals.begin(), vals.end(), val, firstPairComp());vals.insert(res.second, val);}doublestart_t, end_t;start_t= clock();for(size_t i = 0; i < N; ++i){vecss::value_type val(orderVec[i], 0);std::pair<vecss::iterator, vecss::iterator> res =std::equal_range(vals.begin(), vals.end(), val, firstPairComp());acc += res.first->second;}end_t= clock();std::cout << "vector find cost time: "<< ((end_t- start_t) * 1000000) << " ns"<< std::endl;}void insert_in_map(const std::vector<size_t>& orderVec){mapss vals;doublestart_t, end_t;start_t= clock();for(size_t i = 0; i < N; ++i){mapss::value_type val(orderVec[i], rand());vals.insert(val);}end_t= clock();std::cout << "map insert cost time: "<< ((end_t- start_t) * 1000000) << " ns"<< std::endl;}void find_in_map(const std::vector<size_t>& orderVec){mapss vals;for(size_t i = 0; i < N; ++i){mapss::value_type val(orderVec[i], rand());vals.insert(val);}doublestart_t, end_t;start_t= clock();for(size_t i = 0; i < N; ++i){mapss::iterator it = vals.find(orderVec[i]);acc += it->second;}end_t= clock();std::cout << "map insert cost time: "<< ((end_t- start_t) * 1000000) << " ns"<< std::endl;}void iter_vec(){vecss vals;vals.reserve(N);for(size_t i = 0; i < N; ++i)vals.push_back(vecss::value_type(i, rand()));vecss::value_type *begin= &vals[0];doublestart_t, end_t;start_t= clock();for(size_t i = 0; i < N; ++i)acc += begin[i].second;end_t= clock();std::cout << "vector iterator cost time: "<< ((end_t- start_t) * 1000000) << " ns"<< std::endl;}void iter_map(){mapss vals;for(size_t i = 0; i < N; ++i)vals.insert(mapss::value_type(i, rand()));doublestart_t, end_t;start_t= clock();mapss::const_iterator end= vals.end();for(mapss::const_iterator it = vals.begin(); it != end; ++it)acc += it->second;end_t= clock();std::cout << "map iterator cost time: "<< ((end_t- start_t) * 1000000) << " ns"<< std::endl;}int main(){std::vector<size_t> orderVec(N);for(size_t i = 0; i < N; i++){orderVec[i] = i + 1;}insert_in_vec(orderVec);insert_in_map(orderVec);find_in_vec(orderVec);find_in_map(orderVec);iter_vec();iter_map();system("pause");return0;}
测试结果在下面的表格(注意:这里的vector是有序的),单位是纳秒(ns):
| Size | Insert Comparison | Find Comparison | Iterator Comparison | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Vector | Map | Map/Vector | Vector | Map | Map/Vector | Vector | Map | Map/Vector | |
| 10000 | 1e+06 | 2e+06 | 2 | 1e+06 | 1e+06 | 1 | 0 | 0 | null |
| 50000 | 4e+06 | 7e+06 | 1.75 | 3e+06 | 3e+06 | 1 | 0 | 1e+06 | null |
| 100000 | 8e+06 | 1.5e+07 | 1.875 | 7e+06 | 7e+06 | 1 | 0 | 2e+06 | null |
| 1000000 | 9.6e+07 | 1.74e+08 | 1.813 | 7.2e+07 | 7.2e+07 | 1 | 2e+06 | 2.1e+07 | 10.5 |
| 10000000 | 1.097e+09 | 1.908e+09 | 1.74 | 8.23e+08 | 7.9e+08 | 0.96 | 1.5e+07 | 2.2e+08 | 14.67 |
| 100000000 | 1.3488e+10 | 2.3679e+10 | 1.76 | 7.83e+09 | 8.888e+09 | 1.13 | 1.84e+08 | 2.117e+09 | 11.51 |
•对于关联数据结构的插入、擦除和查找操作,哈希几乎总是优于树。•对于相当小的工作集,排序数组具有无与伦比的迭代速度,但代价昂贵的插入和擦除。
因此,如果您关心迭代速度或插入、删除和查找的性能,就不要使用基于树的数据结构。同样,可能会发现少数场景下需要考虑稳定性。
3. 总结
避免使用链表,除非:
•你需要参考稳定性;•你正在实现一个软件MRU/LRU缓存。
使用数组来代替。std::vector生成一个良好的堆分配数组,而std::array生成一个适合堆栈的固定大小的良好数组。
避免使用树结构,除非:
•需要参考稳定性;•操作的成本并不依赖于树中的元素数量(如trie)。
对于小的N值,使用排序数组(boost::container::flat_map构造了一个良好排序的数组,就像一个有序的std::vector一样)。
flat_map is similar to std::map but it's implemented by as an ordered sequence container. The underlying sequence container is by default vector but it can also work user-provided vector-like SequenceContainers (like static_vector or small_vector).
对于大的N值,使用哈希表(std::unordered_map和std::unordered_set)。
声明:本文为 脚本之家专栏作者 投稿,未经允许请勿转载。
- END -

● ![]()
● ![]()
●
●
●
以上是关于链表和有序二叉树插入元素时真的比数组快吗?的主要内容,如果未能解决你的问题,请参考以下文章