数据结构-树和二叉树(Golang)
Posted 这厢有理啦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构-树和二叉树(Golang)相关的知识,希望对你有一定的参考价值。
这几天将树与二叉树知识梳理了一遍,这部分内容细小知识点非常非常多,时间有限诸如线索二叉树的内容等暂时就不总结了,但这些知识点是要好好学的。

知识框架
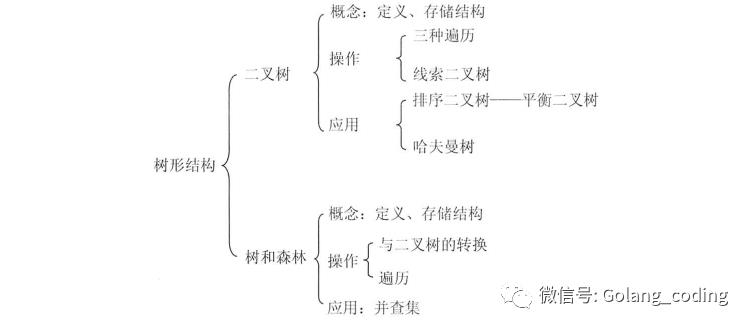
树的基本概念
【树的定义】
树是N(N>=0)各节点的有限集合,当N=0时,我们称其为空树。在任意一棵非空树中应满足:
有且仅有一个特定的称为根的结点。
当N>1时,其余的结点又可分为互不相交的有限集合,其中每个集合又是一棵树,我们称其为根结点的子树。
树的根结点没有前驱结点,除了根结点外所有的结点有且只有一个前驱结点。
树中所有结点可以有零个或多个后继结点。
树是一种递归的数据结构,也是一种分层结构
【一些术语】
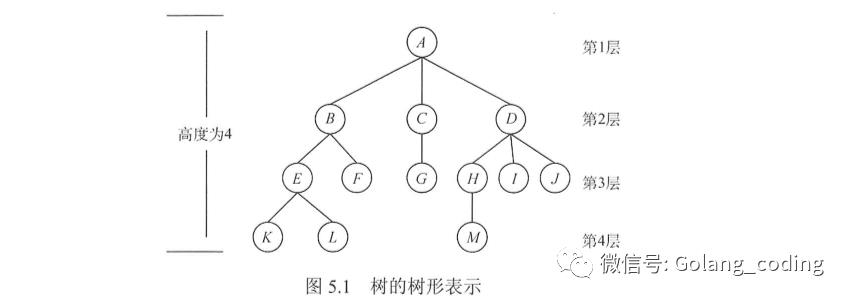
结点类:
祖先结点、双亲结点、孩子结点、子孙结点、兄弟结点、分支节点、叶子结点
度:
结点的度、树的度
结点的深度、高度、层次
有序树、无序树
路径和路径长度
森林
这些基本术语我就在这里不一一列出了,大家稍微花些时间浏览一遍自己的资料就明白了,里面考察选择题非常多,是需要花时间训练掌握的


【树的性质(不全)】

二叉树的基本概念
【二叉树的定义】
二叉树是另一种树形结构,其特点是每个结点至多只有两棵子树(即二叉树中不存在度大于2的结点),并且二叉树的子树有左右之分,其次序不能任意颠倒。
二叉树是有序树,即使树中结点只有一棵子树,也要区分它是左子树还是右子树。因此二叉树有5中基本形态。
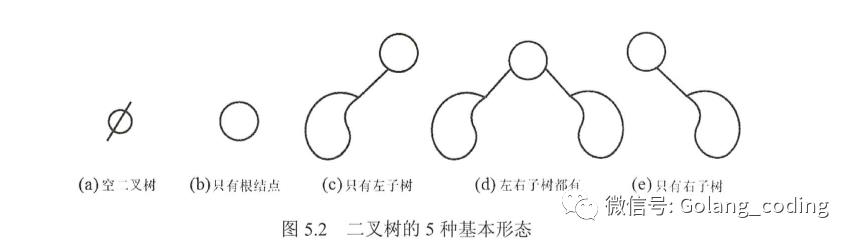
二叉树与度为2的有序树的区别
1.度为2的树至少有3个结点,而二叉树可以为空
2.度为2的有序树的孩子结点的左右次序是相对于结点而言的,如果某个结点只有一个孩子结点,这个孩子结点就无须区分其左右次序,而二叉树无论其孩子数是否为2,均需确定其左右次序,也就是说二叉树的结点次序不是相对于另一结点而言,而是确定的。
【几个特殊的二叉树】
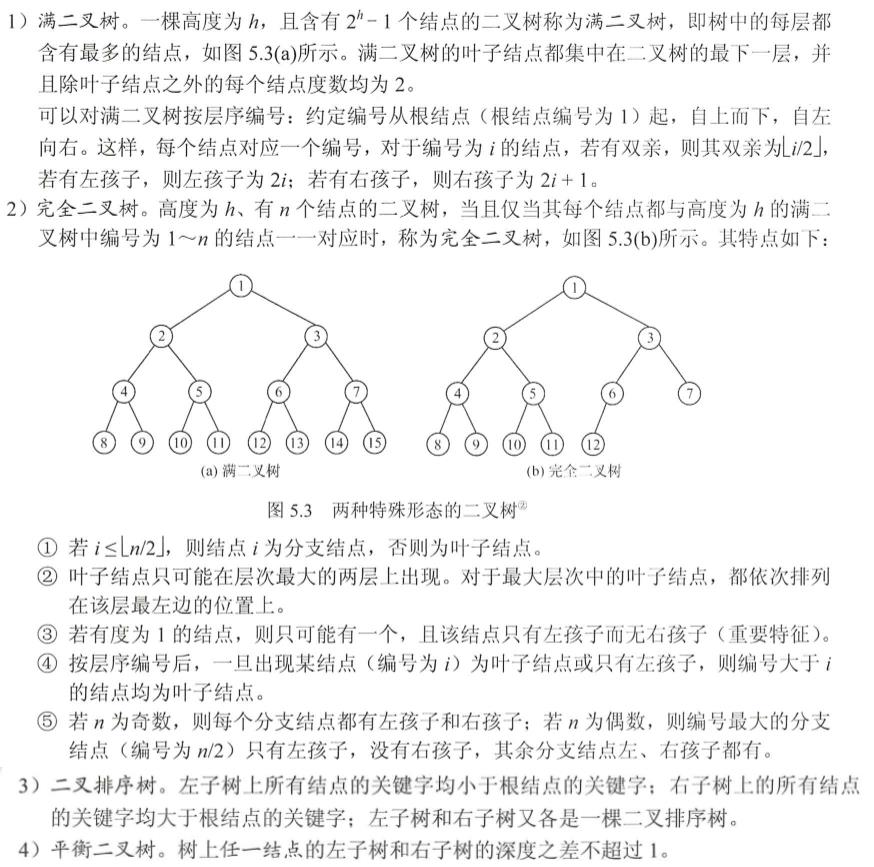
【二叉树的性质】对考研党非非常重要

从这些性质中可以衍生出很多很多题目,是需要多多训练并总结的,考虑到第一遍回顾,题目我暂时就不总结了。
二叉树的存储结构
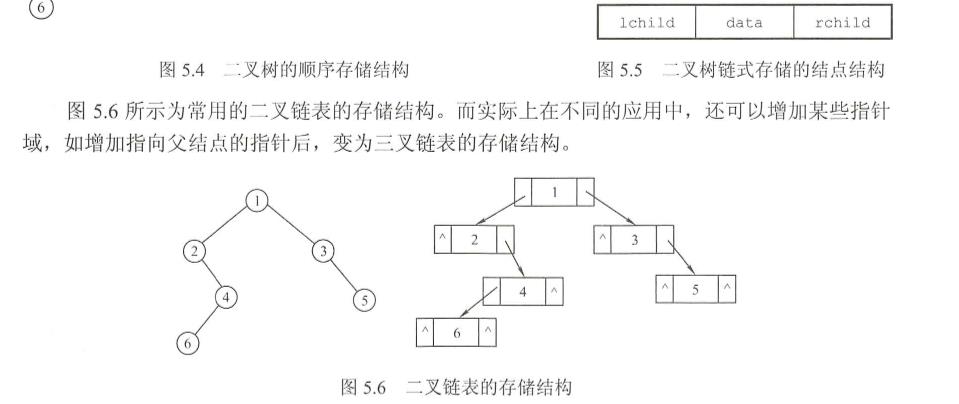
用链表结点来存储二叉树中的每个结点。在二叉树中,结点结构通常包括若干数据域和若干指针域,二叉链表至少包含3个域:数据域data、左指针域lchild和右指针域rchild,如图5.5所示。
//golang描述type BTnode struct{Data string //存储数据Left *BTnode //指向左子树的结点Right *BTnode //指向右子树的结点}
二叉树的递归遍历
所谓的二叉树遍历,是指按某条搜索路径访问树中每个结点,使得每个结点均被访问一次,而且仅被访问一次。由于二叉树是一种非线性结构,每个结点都可能有两棵子树,因而需要寻找一种规律,以便使二叉树上的结点能排列在一个线性队列上,进而便于遍历。
由二叉树的递归定义可知,遍历一棵二叉树便要决定对根结点N、左子树L和右子树R的访问顺序。按照先遍历左子树再遍历右子树的原则,常见的遍历次序有先序(NLR)、中序(LNR)和后序(LRN)三种遍历算法,其中“序”指的是根结点在何时被访问。
先序遍历(PreOrder)
先序遍历的操作过程为:
如果二叉树为空,什么也不做。否则:
访问根结点
先序遍历左子树
先序遍历右子树
对应的算法如下:
//PreTraverse method//先序遍历-递归算法func (root *BTnode)PreTraverse(){if root == nil{return}fmt.Print(root.Data+" ")root.Left.PreTraverse()root.Right.PreTraverse()}
中序遍历(InOrder)
先序遍历的操作过程为:
如果二叉树为空,什么也不做。否则:
中序遍历左子树
访问根结点
中序遍历右子树
对应算法如下:
//InorderTraverse method//中序遍历递归算法func (root *BTnode) InorderTraverse(){if root == nil{return}root.Left.InorderTraverse()fmt.Print(root.Data+" ")root.Right.InorderTraverse()}
后序遍历(PostOrder)
后序遍历的操作过程为:
如果二叉树为空,什么也不做,否则:
后序遍历左子树
后序遍历右子树
访问根结点
对应算法如下:
//PostTraverse method//后序遍历递归算法func (root *BTnode) PostTraverse(){if root ==nil{return}root.Left.PostTraverse()root.Right.PostTraverse()fmt.Print(root.Data+" ")}

三种遍历算法中递归遍历左、右子树的顺序都是固定的,只是访问根的顺序不同。不管是哪种遍历算法,每个结点都访问一次且仅访问一次,故时间复杂度都是O(n),在递归遍历中,递归工作栈的栈深恰好为树的深度,所以在最坏的情况下,二叉树是有n个结点且深度为n的单支树,遍历算法的空间复杂度为O(n)。
package BTreeimport ("fmt"//"laborlearn/datastructure/Queue")type BTnode struct{Data string //存储数据Left *BTnode //指向左子树的结点Right *BTnode //指向右子树的结点}//NewBtree function//添加结点构造树func NewBtree(data string) *BTnode{return &BTnode{Data: data}}//PreTraverse method//先序遍历-递归算法func (root *BTnode)PreTraverse(){if root == nil{return}fmt.Print(root.Data+" ")root.Left.PreTraverse()root.Right.PreTraverse()}//InorderTraverse method//中序遍历递归算法func (root *BTnode) InorderTraverse(){if root == nil{return}root.Left.InorderTraverse()fmt.Print(root.Data+" ")root.Right.InorderTraverse()}//PostTraverse method//后序遍历递归算法func (root *BTnode) PostTraverse(){if root ==nil{return}root.Left.PostTraverse()root.Right.PostTraverse()fmt.Print(root.Data+" ")}// func main(){// root:=&BTnode{// Data: "A",// left: nil,// right: nil,// }// root.left = new(BTnode)// root.left.Data="B"// root.right = new(BTnode)// root.right.Data="C"// root.left.left = new(BTnode)// root.left.left.Data="D"// root.left.right = new(BTnode)// root.left.right.Data="F"// root.left.right.left = new(BTnode)// root.left.right.left.Data="E"// root.right.left = new(BTnode)// root.right.left.Data="G"// root.right.right = new(BTnode)// root.right.right.Data="I"// root.right.left.right = new(BTnode)// root.right.left.right.Data="H"// root.PreTraverse()// }
若是将主程序和main函数分开,main包里main()方法如下:
package mainimport ("fmt""laborlearn/datastructure/BTree")func main() {var root BTree.BTnode //首字母大写才可被使用//按顺序(二叉树结点顺序)添加结点root = *BTree.NewBtree("m") //使用Btree.go中的NewBtree()方法添加结点//root = BTree.BTnode{Data: "a"} //这也是一种添加结点方法root.Left = &BTree.BTnode{Data: "b"}root.Right = &BTree.BTnode{Data: "c"}root.Left.Left = &BTree.BTnode{Data: "d"}root.Left.Right = &BTree.BTnode{Data: "f"}root.Left.Right.Left = &BTree.BTnode{Data: "e"}root.Right.Left = &BTree.BTnode{Data: "g"}root.Right.Right = &BTree.BTnode{Data: "i"}root.Right.Left.Right = &BTree.BTnode{Data: "h"}root.PreTraverse()fmt.Println()root.InorderTraverse()fmt.Println()root.PostTraverse()}
二叉树的非递归遍历
可以借助栈,将二叉树的递归遍历转换为非递归算法,这部分内容暂时由于自己某些点还没有弄懂,所以暂时没有代码重写。我就借助教材上的C语言版本,简述下算法过程。以中序遍历为例。
先扫描(并非访问)根结点的所有左结点并将它们一一进栈。然后出栈一个结点*p(显然结点*p没有左孩子结点或者左孩子结点均已访问过),则访问它。然后扫描该结点的右孩子结点,将其进栈,再扫描该右孩子结点的所有左结点并一一进栈,如此继续,直到栈空为止。
我们以一个树遍历流程来走一遍遍历过程。
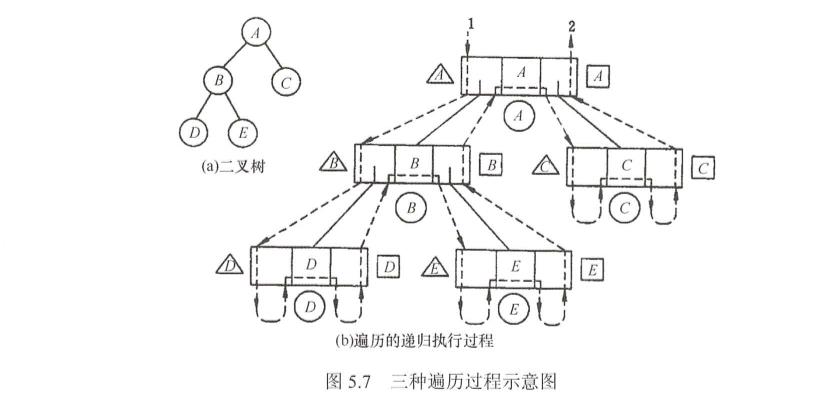



后序遍历非递归算法是最复杂的,因为在后序遍历中,要保证左孩子和右孩子都己被访问并且左孩子在右孩子前访问才能防问根结点,在流程的控制中就会有难题需要解决。
后序非递归遍历算法的思路分析:从根结点开始,将其入栈,然后沿其左子树一直往下搜索,直到搜索到没有左孩子的结点,但是此时不能出战并访问,因为如果其有右子树,还需按相同的规则对其右子树进行处理。直至上述操作进行不下去,若栈顶元素想要出栈被访问,要么右子树为空,要么右子树刚被访问完(此时左子树早已访问完),这样就保证了正确的访问顺序。
二叉树的层次遍历
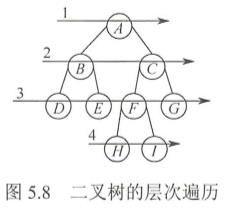
图5.8所示为二叉树的层次遍历,即按照、箭头所指方向,按照1,2,3,4的层次顺序,对二叉树中的各个结点进行访问。要进行层次遍历,需要借助一个队列。先将二叉树根结点入队,然后出队,访问出队结点,若它有左子树,则将左子树根结点入队;若它有右子树,则将右子树根结点入队。然后出队,访问出队结点......如此反复,直至队列为空。
void LevelOrder(BiTree T) {InitQueue(Q); //初始化辅助队列BiTree p;EnQueue(Q,T); //将根结点入队while (!IsEmpty(Q)){ //队列不空则循环DeQueue(Q,p); //队头结点出队visit (p); //访问出队结点if(p->lchild!=NULL)EnQueue(Q,p->lchild); //左子树不空,则左子树根结点入队if(p->rchild!=NULL)EnQueue(Q,p->rchild); //右子树不空,则右子树根结点入队}}
二叉树的遍历算法是我们必须要掌握的,我们可以把它们当作模板来记

根据序列构造二叉树(必会)
几个结论:
先序序列和中序序列可以唯一的确定一棵二叉树
后序序列和中序序列可以唯一的确定一棵二叉树
层次序列和中序序列可以唯一的确定一棵二叉树
先序序列和后序序列无法唯一确定一棵二叉树.
关于这个地方,如果有不会的或者是模棱两可的,推荐大家可以去看下王卓老师的数据结构算法课,这个地方讲的非常详细。
线索二叉树(暂略)
树和森林
【树的存储结构】
树的存储方式有多种,可采用顺序存储结构,也可以采取链式存储结构,采取何种存储方式都要求唯一的反映树中各节点之间的逻辑关系。
双亲表示法
这种方法采取一组连续空间来存储每个结点,同时在每个结点中增设一个伪指针,指示其双亲结点在数组中的位置。
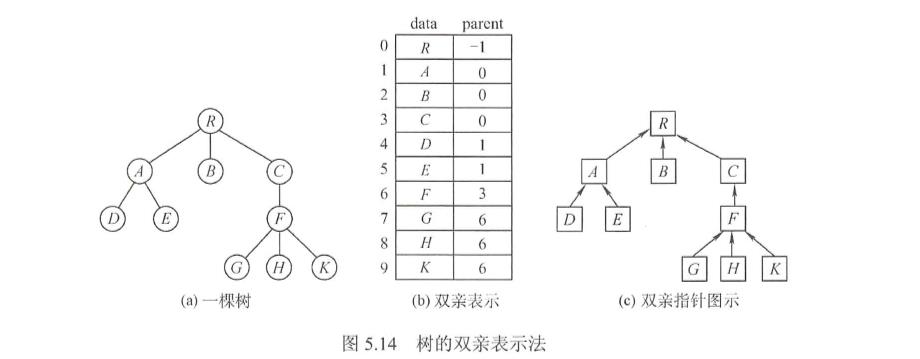
双亲表示法算法描述:
#define MAX_TREE_SIZE 100 //树中最多结点数typedef struct{ //树的结点定义ElemType data; //数据元素int parent; //双亲位置域}PTnode;typedef struct{ //树的类型定义PTnode nodes[MAX_TREE_SIZE]; //双亲表示int n; //结点数}PTree;

2.孩子表示法
孩子表示法是将每个结点的孩子结点都用单链表链接起来形成一个线性结构,此时n个结点就有n个孩子链表(叶子结点的孩子链表为空表)
3.孩子兄弟表示法
孩子兄弟表示法又称二又树表示法,即以二叉链表作为树的存储结构。孩子兄弟表示法使每个结点包括三部分内容:结点值、指向结点第一个孩子结点的指针,及指向结点下一个兄弟结点的指针(沿此域可以找到结点的所有兄弟结点)
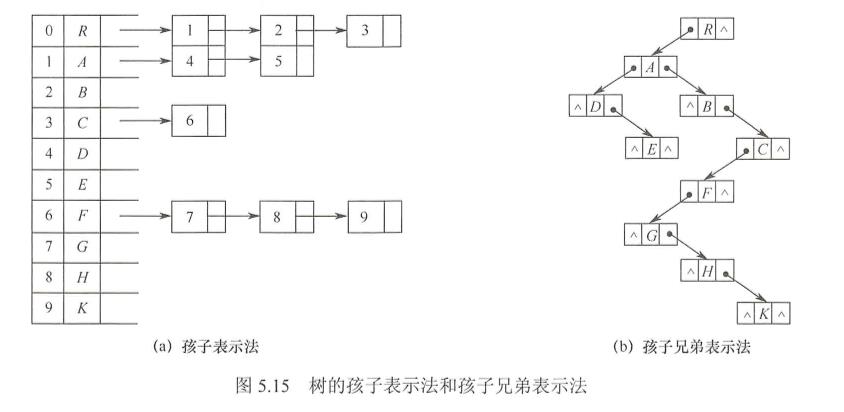
typedef struct CSNode{ElemType data; //指针域struct CSNode *firstchild, *nextsibling; //第一个孩子和右兄弟指针}CSNode, *CSTree;
树、森林、二叉树的转换
转换过程有几个口诀,大家可以参考王卓老师的讲解,演练一下就没问题的。这里我就不详细说明了。
树和森林的遍历
树的遍历是指用某种方式访问树中的每个结点,且仅访问一次。主要有先根遍历和后根遍历。其中先根遍历其序列与这棵树相对应二叉树的先序序列相同,后根遍历其序列与这棵树对应二叉树的中序序列相同。
森林的遍历方法有:
【树和森林的遍历与二叉树遍历的对应关系】
| 树 |
森林 |
二叉树 |
| 先根遍历 |
先序遍历 |
先序遍历 |
| 后根遍历 |
中序遍历 |
中序遍历 |
END
这两天的总结大致就是这么多,内容是真的很多,还有些知识点没有总结到位,后期继续学习过程中会重新补充学习。
写一点感受吧,这章学习中,我再次遇到了Go语言包管理给我带来的困难,将自定义的包和main包分开后,由于自己的代码目录管理问题,一直出现无法再GOROOT下查找到包的问题,最终在自己的捯饬下,终于发现了问题,main.go程序的存放位置有问题,我们需要把main.go放在一个main文件下,而且使用了go mod 那么就不能在GOPATH下管理代码。
不足之处是,在这章遇到了挺多问题的,非递归算法遍历程序配合栈和队列还是有一点点困难,但我会继续补上这些代码,这是必经之路。继续加油!
参考资料:
王道考研数据结构与算法
https://www.bilibili.com/read/cv2306631青岛大学-王卓-数据结构与算法
以上是关于数据结构-树和二叉树(Golang)的主要内容,如果未能解决你的问题,请参考以下文章