无监督学习 聚类算法代码+原理+对比分析
Posted DeepAI 视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无监督学习 聚类算法代码+原理+对比分析相关的知识,希望对你有一定的参考价值。
1:经典的K means
纵使簇类需要专家系统与先验知识定义,K means 也依旧在当前的机器学习与深度学习使用,例如各种数据分析以及深度学习全连接以后的输出层网络连接,它与他的衍生算法,例如K means ++ ,在聚类算法中一直是老大地位,因为他的速度是极快的,相比其他算法在计算簇间相似度与簇内相似度中的速度较慢;所以就出现了很多算法,是来优化K means 家族的,例如在簇的寻找上,使用DBACAN等层次聚类算法用来给K means ++ 寻找最合适的簇个数,在此基础上,DBACAN + K means ++ 算法成为21世纪学界较常使用的多算法融合。
K-means与K-means++:原始K-means算法最开始随机选取数据集中K个点作为聚类中心,而K-means++按照如下的思想选取K个聚类中心:假设已经选取了n个初始聚类中心(0<n<K),则在选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心。在选取第一个聚类中心(n=1)时同样通过随机的方法。可以说这也符合我们的直觉:聚类中心当然是互相离得越远越好。这个改进虽然直观简单,但是却非常得有效。
算法优缺点
优点:对于大型数据集也是简单高效、时间复杂度、空间复杂度低。
缺点:最重要是数据集大时结果容易局部最优;需要预先设定K值,对最先的K个点选取很敏感;对噪声和离群值非常敏感;只用于numerical类型数据;不能解决非凸(non-convex)数据。
常见的算法及改进
k-means对初始值的设置很敏感,所以有了k-means++、intelligent k-means、genetic k-means。
k-means对噪声和离群值非常敏感,所以有了k-medoids和k-medians。
k-means只用于numerical类型数据,不适用于categorical类型数据,所以k-modes。
k-means不能解决非凸(non-convex)数据,所以有了kernel k-means。
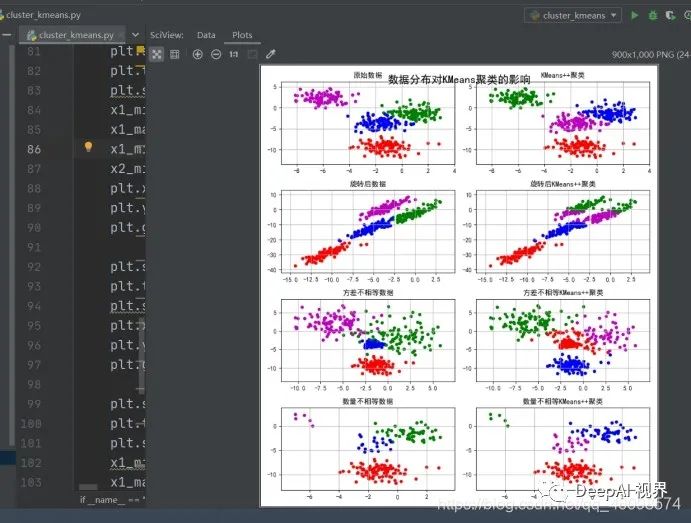
另外,很多教程都告诉我们Partition-based
methods聚类多适用于中等体量的数据集,但我们也不知道“中等”到底有多“中”,所以不妨理解成,数据集越大,越有可能陷入局部最小。下图显示的就是面对非凸,k-means和kernel
k-means的不同效果。

Clion 编译器:
//// Created by zxx on 2020/10/19.////#include "stdafx.h"using namespace std;typedef struct {double x[NUM];}PATTERN;PATTERN p[NN] = {{0, 0}, {1, 0}, {0, 1},{1, 1}, {2,1 }, {1, 2}, {2, 2}, {3, 2},{6, 6}, {7, 6}, {8, 6}, {6, 7},{7, 7}, {8, 7},{9, 7},{7, 8}, {8, 8}, {9, 8}, {8, 9},{9, 9}};PATTERN z[cnum], oldz[cnum];int nj[cnum];int cindex[cnum][NN];double Eucliden(PATTERN x, PATTERN y){int i;double d;d = 0.0;for (i = 0; i<NUM; i++){d +=(x.x[i]-y.x[i]) * (x.x[i]-y.x[i]);}d = sqrt(d);return d;}bool zequal(PATTERN z1[], PATTERN z2[]){int j;double d;d = 0.0;for (j = 0; j <cnum; j++ ){d +=Eucliden(z1[j], z2[j]);}if(d < 0.00001) return true;else return false;}void C_mean(){int i, j, l;double d, dmin;for (j = 0; j < cnum; j++){z[j] = p[j];}do {for (j = 0; j < cnum; j++) {nj[j] = 0;oldz[j] = z[j];}for (i = 0; i < NN; i++) {for (j = 0; j < cnum; j++) {d = Eucliden(z[j], p[i]);if (j == 0) {dmin = d;l = 0;}else {if (d < dmin) {dmin = d;l = j;}}}cindex[l][nj[l]] = i;nj[l]++;}for (j = 0; j < cnum; j++) {if (nj[j] == 0) continue;for (i = 0; i < NUM; i++) {d = 0.0;for (l = 0; l < nj[j]; l++) {d += p[cindex[j][l]].x[i];}d /= nj[j];z[j].x[i] = d;}}}while (!zequal(z, oldz));}void Out_result(){int i, j;std::cout << "Result:" << endl;for (j = 0; j < cnum; j ++){std::cout <<" nj[" << j <<"] = "<< nj[j] << " "<<endl;for (i = 0; i <nj[j]; i++){std::cout<<" " << cindex[j][i];}}}int main(int argc, char * argv[]){C_mean();Out_result();return 0;}
编译结果与结果演示

# !/usr/bin/python# -*- coding:utf-8 -*-import numpy as npimport matplotlib.pyplot as pltimport sklearn.datasets as dsimport matplotlib.colorsfrom sklearn.cluster import KMeansfrom sklearn.cluster import MiniBatchKMeansdef expand(a, b):d = (b - a) * 0.1return a-d, b+dif __name__ == "__main__":N = 400centers = 4# (方差,数据一样) 产生聚类方法 x1,x2两个维度 Kdata, y = ds.make_blobs(N, n_features=2, centers=centers, random_state=2)# (方差不一样) 方差data2, y2 = ds.make_blobs(N, n_features=2, centers=centers, cluster_std=(1, 2.5, 0.5, 2), random_state=2)data3 = np.vstack((data[y == 0][:], data[y == 1][:50], data[y == 2][:20], data[y == 3][:5]))y3 = np.array([0] * 100 + [1] * 50 + [2] * 20 + [3] * 5)cls = KMeans(n_clusters=4, init='k-means++')y_hat = cls.fit_predict(data)y2_hat = cls.fit_predict(data2)y3_hat = cls.fit_predict(data3)#数据旋转m = np.array(((1, 1), (1, 3)))data_r = data.dot(m)y_r_hat = cls.fit_predict(data_r)# 设置rc参数显示中文标题# 设置字体为SimHei显示中文# 设置正常显示字符matplotlib.rcParams['font.sans-serif'] = [u'SimHei']matplotlib.rcParams['axes.unicode_minus'] = Falsecm = matplotlib.colors.ListedColormap(list('rgbm'))plt.figure(figsize=(9, 10), facecolor='w')plt.subplot(421)plt.title(u'原始数据')# 散点图plt.scatter(data[:, 0], data[:, 1], c=y, s=30, cmap=cm, edgecolors='none')x1_min, x2_min = np.min(data, axis=0)x1_max, x2_max = np.max(data, axis=0)x1_min, x1_max = expand(x1_min, x1_max)x2_min, x2_max = expand(x2_min, x2_max)plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.subplot(422)plt.title(u'KMeans++聚类')plt.scatter(data[:, 0], data[:, 1], c=y_hat, s=30, cmap=cm, edgecolors='none')plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.subplot(423)plt.title(u'旋转后数据')plt.scatter(data_r[:, 0], data_r[:, 1], c=y, s=30, cmap=cm, edgecolors='none')x1_min, x2_min = np.min(data_r, axis=0)x1_max, x2_max = np.max(data_r, axis=0)x1_min, x1_max = expand(x1_min, x1_max)x2_min, x2_max = expand(x2_min, x2_max)plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.subplot(424)plt.title(u'旋转后KMeans++聚类')plt.scatter(data_r[:, 0], data_r[:, 1], c=y_r_hat, s=30, cmap=cm, edgecolors='none')plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.subplot(425)plt.title(u'方差不相等数据')plt.scatter(data2[:, 0], data2[:, 1], c=y2, s=30, cmap=cm, edgecolors='none')x1_min, x2_min = np.min(data2, axis=0)x1_max, x2_max = np.max(data2, axis=0)x1_min, x1_max = expand(x1_min, x1_max)x2_min, x2_max = expand(x2_min, x2_max)plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.subplot(426)plt.title(u'方差不相等KMeans++聚类')plt.scatter(data2[:, 0], data2[:, 1], c=y2_hat, s=30, cmap=cm, edgecolors='none')plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.subplot(427)plt.title(u'数量不相等数据')plt.scatter(data3[:, 0], data3[:, 1], s=30, c=y3, cmap=cm, edgecolors='none')x1_min, x2_min = np.min(data3, axis=0)x1_max, x2_max = np.max(data3, axis=0)x1_min, x1_max = expand(x1_min, x1_max)x2_min, x2_max = expand(x2_min, x2_max)plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.subplot(428)plt.title(u'数量不相等KMeans++聚类')plt.scatter(data3[:, 0], data3[:, 1], c=y3_hat, s=30, cmap=cm, edgecolors='none')plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.tight_layout(2, rect=(0, 0, 1, 0.97))plt.suptitle(u'数据分布对KMeans聚类的影响', fontsize=18)plt.show()# plt.savefig('cluster_kmeans')
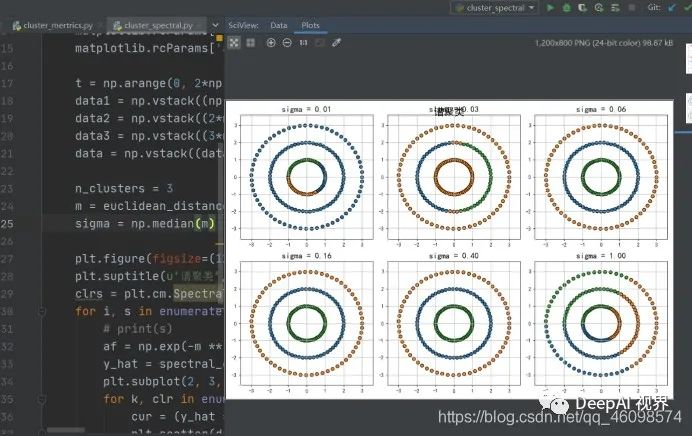
首先根据给定的样本数据集定义一个描述成对数据点相似度的亲合矩阵,并计算矩阵的特征值和特征向量,然后选择合适的特征向量聚类不同的数据点。谱聚类算法最初用于计算机视觉、VLSI设计等领域,最近才开始用于机器学习中,并迅速成为国际上机器学习领域的研究热点。
谱聚类算法建立在图论中的谱图理论基础上,其本质是将聚类问题转化为图的最优划分问题,是一种点对聚类算法。
谱聚类,我的python实现
import numpy as npimport matplotlib.pyplot as pltimport matplotlib.colorsfrom sklearn.cluster import spectral_clusteringfrom sklearn.metrics import euclidean_distancesdef expand(a, b):d = (b - a) * 0.1return a-d, b+dif __name__ == "__main__":matplotlib.rcParams['font.sans-serif'] = [u'SimHei']matplotlib.rcParams['axes.unicode_minus'] = Falset = np.arange(0, 2*np.pi, 0.1)data1 = np.vstack((np.cos(t), np.sin(t))).Tdata2 = np.vstack((2*np.cos(t), 2*np.sin(t))).Tdata3 = np.vstack((3*np.cos(t), 3*np.sin(t))).Tdata = np.vstack((data1, data2, data3))n_clusters = 3m = euclidean_distances(data, squared=True)sigma = np.median(m)plt.figure(figsize=(12, 8), facecolor='w')plt.suptitle(u'谱聚类', fontsize=20)clrs = plt.cm.Spectral(np.linspace(0, 0.8, n_clusters))for i, s in enumerate(np.logspace(-2, 0, 6)):# print(s)af = np.exp(-m ** 2 / (s ** 2)) + 1e-6y_hat = spectral_clustering(af, n_clusters=n_clusters, assign_labels='kmeans', random_state=41)plt.subplot(2, 3, i+1)for k, clr in enumerate(clrs):cur = (y_hat == k)plt.scatter(data[cur, 0], data[cur, 1], s=40, c=None, edgecolors='k')x1_min, x2_min = np.min(data, axis=0)x1_max, x2_max = np.max(data, axis=0)x1_min, x1_max = expand(x1_min, x1_max)x2_min, x2_max = expand(x2_min, x2_max)plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.title(u'sigma = %.2f' % s, fontsize=16)plt.tight_layout()plt.subplots_adjust(top=0.9)plt.show()
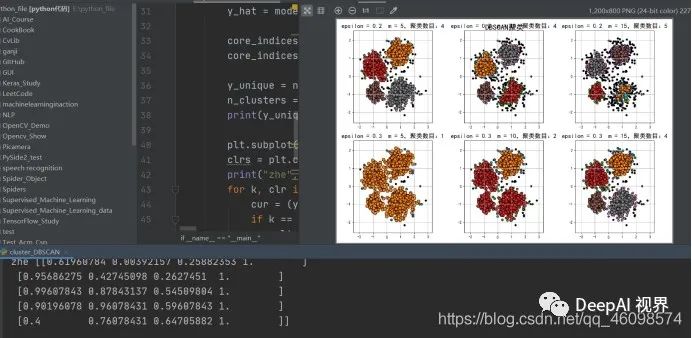
DBSCAN
DBSCAN流程
从任一对象点p开始;
寻找并合并核心p对象直接密度可达(eps)的对象;
如果p是一个核心点,则找到了一个聚类,如果p是一个边界点(即从p没有密度可达的点)则寻找下一个对象点;
重复2、3,直到所有点都被处理
算法优缺点
优点:对噪声不敏感;能发现任意形状的聚类。
缺点:聚类的结果与参数有很大的关系;DBSCAN用固定参数识别聚类,但当聚类的稀疏程度不同时,相同的判定标准可能会破坏聚类的自然结构,即较稀的聚类会被划分为多个类或密度较大且离得较近的类会被合并成一个聚类。
常见的算法及改进
DBSCAN对这两个参数的设置非常敏感。DBSCAN的扩展叫OPTICS(Ordering Points To Identify Clustering Structure)通过优先对高密度(high density)进行搜索,然后根据高密度的特点设置参数,改善了DBSCAN的不足。下图就是表现了DBSCAN对参数设置的敏感,你们可以感受下。


DBACAN ,我的python实现
import numpy as npimport matplotlib.pyplot as pltimport sklearn.datasets as dsimport matplotlib.colorsfrom sklearn.cluster import DBSCANfrom sklearn.preprocessing import StandardScalerdef expand(a, b):d = (b - a) * 0.1return a-d, b+dif __name__ == "__main__":N = 1000centers = [[1, 2], [-1, -1], [1, -1], [-1, 1]]data, y = ds.make_blobs(N, n_features=2, centers=centers, cluster_std=[0.5, 0.25, 0.7, 0.5], random_state=0)data = StandardScaler().fit_transform(data)# 数据的参数:(epsilon, min_sample)params = ((0.2, 5), (0.2, 10), (0.2, 15), (0.3, 5), (0.3, 10), (0.3, 15))matplotlib.rcParams['font.sans-serif'] = [u'SimHei']matplotlib.rcParams['axes.unicode_minus'] = Falseplt.figure(figsize=(12, 8), facecolor='w')plt.suptitle(u'DBSCAN聚类', fontsize=20)for i in range(6):eps, min_samples = params[i]model = DBSCAN(eps=eps, min_samples=min_samples)model.fit(data)y_hat = model.labels_core_indices = np.zeros_like(y_hat, dtype=bool)core_indices[model.core_sample_indices_] = Truey_unique = np.unique(y_hat)n_clusters = y_unique.size - (1 if -1 in y_hat else 0)print(y_unique, '聚类簇的个数为:', n_clusters)plt.subplot(2, 3, i+1)clrs = plt.cm.Spectral(np.linspace(0, 0.8, y_unique.size))print("zhe",clrs)for k, clr in zip(y_unique, clrs):cur = (y_hat == k)if k == -1:plt.scatter(data[cur, 0], data[cur, 1], s=20, c='k')continueplt.scatter(data[cur, 0], data[cur, 1], s=30, edgecolors='k')plt.scatter(data[cur & core_indices][:, 0], data[cur & core_indices][:, 1], s=60, marker='o', edgecolors='k')x1_min, x2_min = np.min(data, axis=0)x1_max, x2_max = np.max(data, axis=0)x1_min, x1_max = expand(x1_min, x1_max)x2_min, x2_max = expand(x2_min, x2_max)plt.xlim((x1_min, x1_max))plt.ylim((x2_min, x2_max))plt.grid(True)plt.title(u'epsilon = %.1f m = %d,聚类数目:%d' % (eps, min_samples, n_clusters), fontsize=16)plt.tight_layout()plt.subplots_adjust(top=0.9)plt.show()
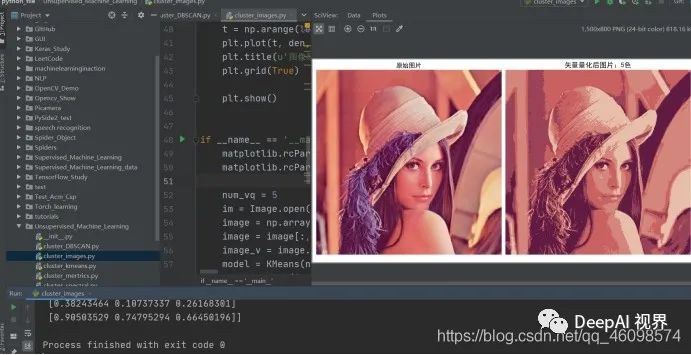
基于聚类的图片降维实现
#使用聚类进行降维from PIL import Imageimport numpy as npfrom sklearn.cluster import KMeansimport matplotlibimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Ddef restore_image(cb, cluster, shape):row, col, dummy = shapeimage = np.empty((row, col, 3))index = 0for r in range(row):for c in range(col):image[r, c] = cb[cluster[index]]index += 1return imagedef show_scatter(a):N = 10print('原始数据: ', a)density, edges = np.histogramdd(a, bins=[N,N,N], range=[(0,1), (0,1), (0,1)])density /= density.max()print(density)x = y = z = np.arange(N)d = np.meshgrid(x, y, z)fig = plt.figure(1, facecolor='w')ax = fig.add_subplot(111, projection='3d')ax.scatter(d[1], d[0], d[2], c='r', s=100*density, marker='o', depthshade=True)ax.set_xlabel(u'红色分量')ax.set_ylabel(u'绿色分量')ax.set_zlabel(u'蓝色分量')plt.title(u'图像颜色三维频数分布', fontsize=20)plt.figure(2, facecolor='w')den = density[density > 0]den = np.sort(den)[::-1]t = np.arange(len(den))plt.plot(t, den, 'r-', t, den, 'go', lw=2)plt.title(u'图像颜色频数分布', fontsize=18)plt.grid(True)plt.show()if __name__ == '__main__':matplotlib.rcParams['font.sans-serif'] = [u'SimHei']matplotlib.rcParams['axes.unicode_minus'] = Falsenum_vq = 5im = Image.open('../Unsupervised_Machine_Learning_data/Lena.png') # flower2.png(200)/lena.png(50)image = np.array(im).astype(np.float) / 255 #把图片中的数值转成浮点数组image = image[:, :, :3]#取三维:RGB(不要alpha:特征度)image_v = image.reshape((-1, 3))model = KMeans(num_vq)# Kshow_scatter(image_v)N = image_v.shape[0] # 图像像素总数# 选择足够多的样本(如1000个),计算聚类中心idx = np.random.randint(0, N, size=1000)image_sample = image_v[idx]model.fit(image_sample)c = model.predict(image_v) # 聚类结果print('聚类结果: ', c)print('聚类中心: ', model.cluster_centers_)plt.figure(figsize=(15, 8), facecolor='w')plt.subplot(121)plt.axis('off')plt.title(u'原始图片', fontsize=18)plt.imshow(image)# plt.savefig('1.png')plt.subplot(122)vq_image = restore_image(model.cluster_centers_, c, image.shape)plt.axis('off')plt.title(u'矢量量化后图片:%d色' % num_vq, fontsize=20)plt.imshow(vq_image)# plt.savefig('2.png')plt.tight_layout(1.2)plt.show()
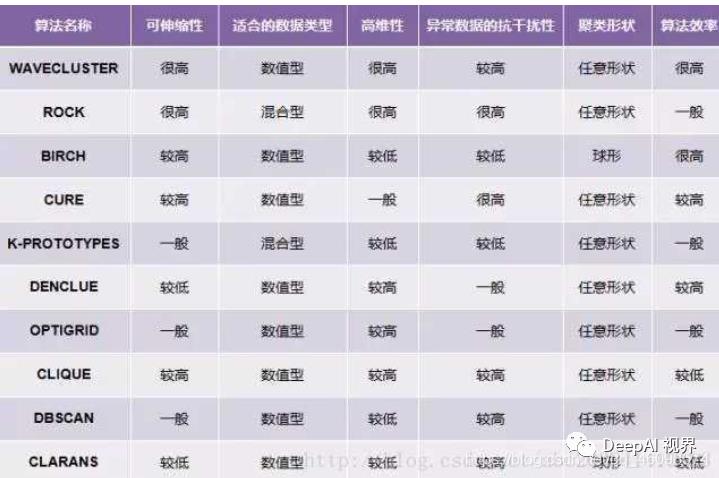
参考:Reference
【https://blog.csdn.net/u013185349/article/details/82386113】
Openvino 中文社区
合作网站:【www.xinzikong.com】
DeepAI 视界
以上是关于无监督学习 聚类算法代码+原理+对比分析的主要内容,如果未能解决你的问题,请参考以下文章