无监督学习K-means聚类算法原理介绍,以及代码实现
Posted Python爱好者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无监督学习K-means聚类算法原理介绍,以及代码实现相关的知识,希望对你有一定的参考价值。

博客:http://blog.csdn.net/zzz_cming
作者好文推荐:
前言:粗略研究完神经网络基础——BP、CNN、RNN、LSTM网络后自己算是松懈了很多,好长的时间都没有坚持再更新博客了。“腐败”生活了这么久,还是要找到自己一点乐趣吧,于是想了一想,决定把《机器学习》的算法研究过得都重新梳理一遍,于是就从无监督学习——聚类开始了
什么是无监督学习?
无监督学习也是相对于有监督学习来说的,因为现实中遇到的大部分数据都是未标记的样本,要想通过有监督的学习就需要事先人为标注好样本标签,这个成本消耗、过程用时都很巨大,所以无监督学习就是使用无标签的样本找寻数据规律的一种方法
聚类算法就归属于机器学习领域下的无监督学习方法。
无监督学习的目的是什么呢?
可以从庞大的样本集合中选出一些具有代表性的样本子集加以标注,再用于有监督学习
可以从无类别信息情况下,寻找表达样本集具有的特征
分类和聚类的区别是什么呢?
对于分类来说,在给定一个数据集,我们是事先已知这个数据集是有多少个种类的。比如一个班级要进行性别分类,我们就下意识清楚分为“男生”、“女生”两个类;该班又转入一个同学A,“男ta”就被分入“男生”类;
而对于聚类来说,给定一个数据集,我们初始并不知道这个数据集包含多少类,我们需要做的就是将该数据集依照某个“指标”,将相似指标的数据归纳在一起,形成不同的类;
分类是一个后续的过程,已知标签数据,再将测试样本分入同标签数据集中;聚类是不知道标签,将“相似指标”的数据强行“撸”在一起,形成各个类。
聚类算法主要包含:K-means、DBSCAN(未完善)
一、K-means聚类算法
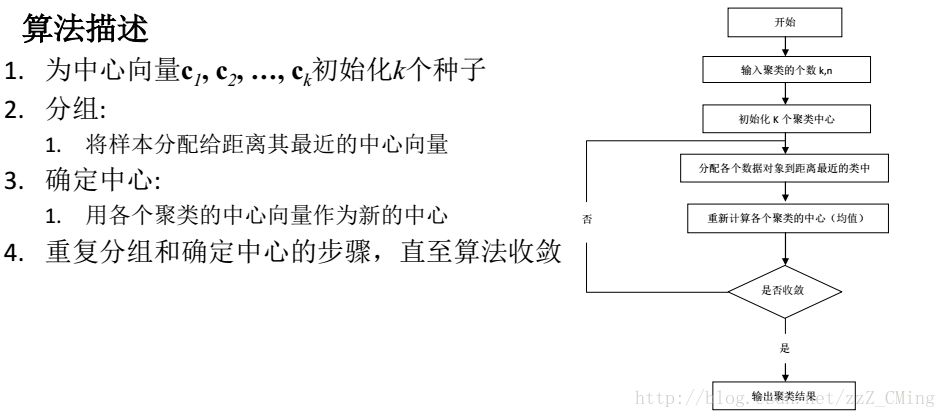
1.1、K-means 算法思想、算法描述
K——指我们最后聚成的有K个类;means——平均,指我们在做聚类时选用类间平均距离进行计算
K-means 的算法思想:是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个类做到——类内紧凑,类间独立。
K-means 的算法描述如下图:
1.2、K-means 算法运行图示
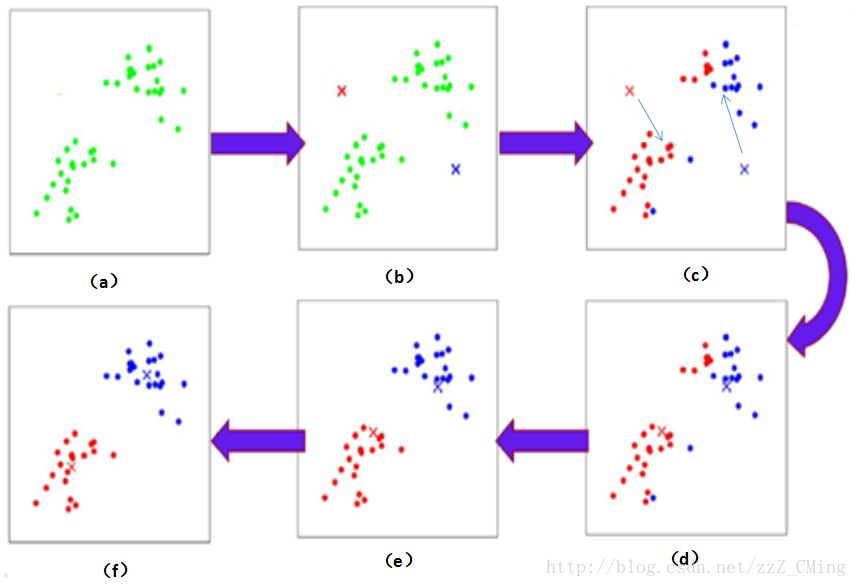
(a)图:展示出样本集空间中各个数据点的分布情况;
(b)图:给定了两个中心点:红叉叉点、蓝叉叉点;
(c)图:样本集中的数据点,离哪个中心点近,就把数据点分属到哪个类别中;
(d)图:在分属好的类别中依照类内距离的平均值,得到新的中心点——原有中心点就从(c)图中的位置转移到新的中心点位置;
(e)图:在得到新的中心点后,再依据离哪个中心点近,就把数据点分属到哪个类别中的方法,重新划分聚类;直到成(f)图,中心点不再变化,聚类结束。
1.3、举实例使用K-means算法进行聚类
举个栗子:我们有五个样本点a(0,2)、b(0,0)、c(1.5,0)、d(5,0)、e(5,2),选取前两个样本点a(0,2)、b(0,0)作为初始聚类中心点A、B,开始聚类:
对于点c(1.5,0),到a点的(欧式)距离为2.5,到b点距离为1.5,所以c点分配给B类;
同例,d点分入B类、e点分入A类;于是更新后得到的新簇:A类={a,e},B类={b,c,d}
每迭代一次都计算一次平均误差:平均误差是等于新簇内的点到原有中心点距离的平方和,例如
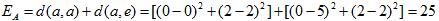
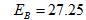
再得到总体的平均误差E=25+27.25=52.25重新计算新的簇内中心点:A=((0+5)/2,(2+2)/2)=(2.5,2)、B=((0+1.5+5)/3,(0+0+0)/3)=(2.17,0),重复1、2、3步骤,再得到新的平均误差E=25.62,误差显著减小。由于经过两次迭代后,中心点不再变化,所以停止迭代,聚类结束。
1.4、K-means 算法优缺点
优点:如果样本集是团簇密集状的,K-means聚类方法效果较好
缺点:
对于条状、环形状等非团簇状的样本集,聚类效果一般;
对于事先给定的K值、初始点敏感,不同K值、初始点可能导致聚类得到结果差异较大;
也可能因为初始点分属同一类,导致最后结果陷入局部最小值,无法达到全局最优解。
1.5、K值的选取原则——肘部法则
由于K-means 算法对初选的K值是敏感的,计算平均误差就是为了K值的选取,请看下图: 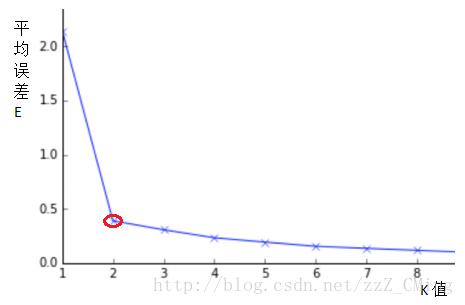
平均误差会随K值的选取而改变,随着K值增大,平均误差会逐渐降低;极限情况下是每个样本点是都是一个类,这时的平均误差E=0,当然这种聚类没有研究的价值。
那么哪个K值是最佳选取的值呢——肘部法则,就是选取斜率变化较大的拐点处定为K值点,这只是一种简单的选取规则,方便简单而且实用。
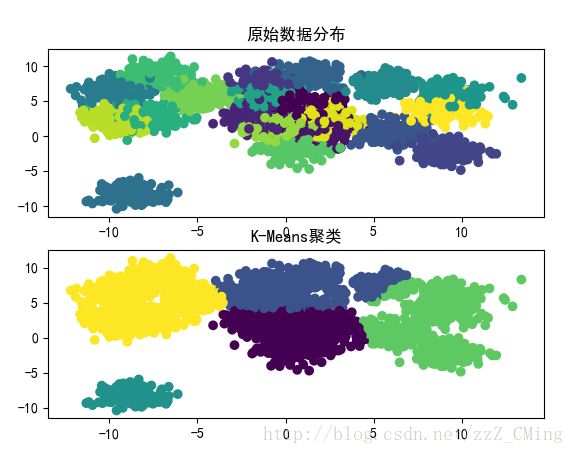
1.6、K-means聚类程序展示
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing
# -*- 2018/04/10;14:44
# -*- python3.5
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as ds
import matplotlib.colors
from sklearn.cluster import KMeans
# 随机生成数据
points_number = 3000
centers = 20
data,laber=ds.make_blobs(points_number,centers=centers,random_state=0)
# 创建Figure
fig = plt.figure()
# 用来正常显示中文标签
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
# 用来正常显示负号
matplotlib.rcParams['axes.unicode_minus'] = False
# 原始点的分布
ax1 = fig.add_subplot(211)
plt.scatter(data[:,0],data[:,1],c=laber)
plt.title(u'原始数据分布')
plt.sca(ax1)
# K-means聚类后
N = 5
model = KMeans(n_clusters = N,init = 'k-means++')
y_pre = model.fit_predict(data)
ax2 = fig.add_subplot(212)
plt.scatter(data[:,0],data[:,1],c=y_pre)
plt.title(u'K-Means聚类')
plt.sca(ax2)
plt.show()
效果展示:
赞赏作者


Python爱好者社区历史文章大合集:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战免费学习视频。
以上是关于无监督学习K-means聚类算法原理介绍,以及代码实现的主要内容,如果未能解决你的问题,请参考以下文章