[机器学习与scikit-learn-22]:算法-聚类-无监督学习与聚类基本原理
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习与scikit-learn-22]:算法-聚类-无监督学习与聚类基本原理相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123451266
目录
第1章 什么无监督学习
1.1 概述
决策树,随机森林,逻辑回归,他们虽然有着不同的功能,但却都属于“有监督学习”的一部分,即是说,模型在训练的时候,即需要特征矩阵X,也需要真实标签y。
机器学习当中,还有相当一部分算法属于“无监督学习”,无监督的算法在训练的时候只需要特征矩阵X,不需要标签。你可能会好奇,没有标签,机器怎么学习呢?
1.2 应用场景
现实生活中常常会有这样的问题:
(1)缺乏足够的先验知识,因此难以人工标注类别;
(2)进行人工类别标注的成本太高。
很自然地,我们希望计算机能代我们(部分)完成这些工作,或至少提供一些帮助。
常见的应用背景包括:
(1)一从庞大的样本集合中选出一些具有代表性的加以标注用于分类器的训练。
(2)先将所有样本自动分为不同的类别,再由人类对这些类别进行标注。
(3)在无类别信息情况下,寻找好的特征。
即先让机器按照指定的要求,自己发现样本数据集内在特征隐藏的规律。
1.3 常见算法
常用的无监督学习算法主要有主成分分析方法PCA等,等距映射方法、局部线性嵌入方法、拉普拉斯特征映射方法、黑塞局部线性嵌入方法和局部切空间排列方法等。 [2]
从原理上来说PCA等数据降维算法同样适用于深度学习,但是这些数据降维方法复杂度较高,并且其算法的目标太明确,使得抽象后的低维数据中没有次要信息,而这些次要信息可能在更高层看来是区分数据的主要因素。所以现在深度学习中采用的无监督学习方法通常采用较为简单的算法和直观的评价标准。
PCA降维算法就是无监督学习中的一种,聚类算法,也是无监督学习的代表算法之一。
第2章 什么是聚类
2.1 概述
无监督学习里典型例子是聚类。
聚类的目的在于把特征相似的东西聚在一起,而我们并不关心这一类是什么。
因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。比如在商业中,如果我们手头有大量的当前和潜在客户的信息,我们可以使用聚类将客户划分为若干组,以便进一步分析和开展营销活动,最有名的客户价值判断模型RFM,就常常和聚类分析共同使用。再比如,聚类可以用于降维和矢量量化(vector quantization),可以将高维特征压缩到一列当中,常常用于图像,声音,视频等非结构化数据,可以大幅度压缩数据量。
2.2 聚类与分类的区别
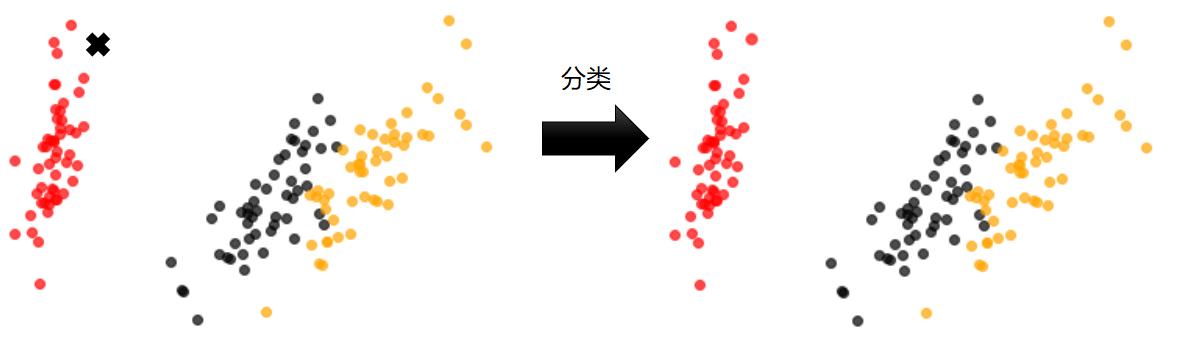
分类预先知道数据样本的类别,比如红色、黑色、黄色。

聚类预先并不知道数据样本中样本的类型,机器自己发现数据集中有三种不同的特征数据,但这三类数据到底代表什么,机器并不知道,程序员也没有告诉机器。这就是聚类。
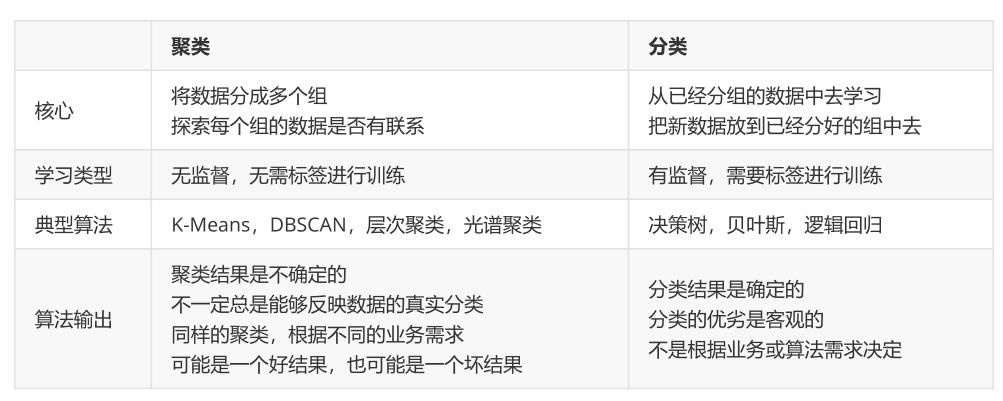
2.3 常见的聚类与分类算法比较
2.4 scikit-learn
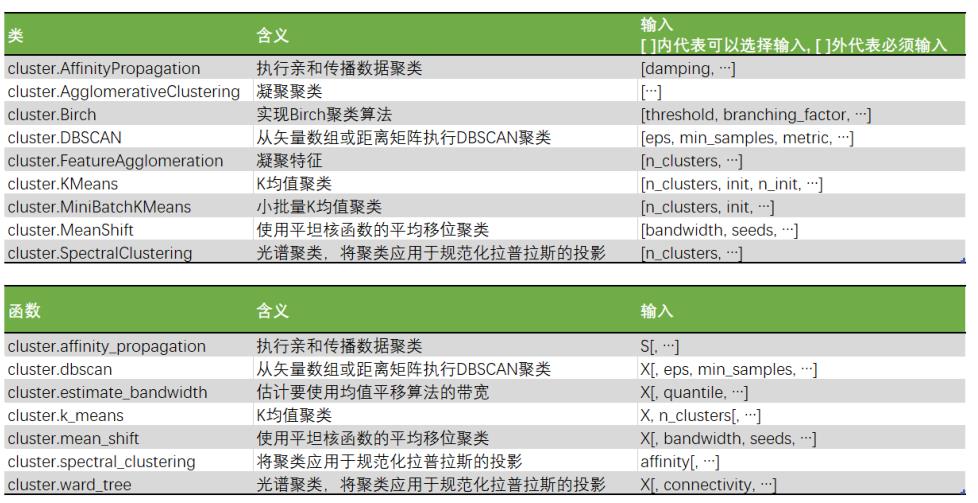
聚类算法在sklearn中有两种表现形式(与scikit-learn其他算法一样)
一种是类(和我们目前为止学过的分类算法以及数据预处理方法们都一样),需要实例化,训练并使用接口和属性来调用结果。
另一种是函数(function),只需要输入特征矩阵和超参数,即可返回聚类的结果和各种指标。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123451266
以上是关于[机器学习与scikit-learn-22]:算法-聚类-无监督学习与聚类基本原理的主要内容,如果未能解决你的问题,请参考以下文章