放弃机器学习框架,如何用Python做物体检测?
Posted Python编程开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了放弃机器学习框架,如何用Python做物体检测?相关的知识,希望对你有一定的参考价值。
(给Python编程开发加星标,提升编程技能)
来源:CSDN
每当我们听说“物体检测”时,就会想到机器学习和各种不同的框架。但实际上,我们可以在不使用机器学习或任何其他框架的情况下进行物体检测。在本文中,我将向你展示如何仅使用Python进行操作。
首先,我们定义一个模板图像(或者叫模板物体),然后程序将在源图像中查找与我们选择的模板匹配的所有其他物体。举例来说明一下。下面有两张图片,上面是飞机的源图像,下面是模板照片,其中的物体为飞机。

下面我们来编写python代码,圈出源图像中所有匹配模板图像的区域。
首先,我们来检测一个物体。然后再调整代码实现多个物体的检测。
检测一个物体:最准确的那个物体
我们需要一个源图像和一个模板图像。模板图像在源图像上滑动(像2D卷积有一样),然后程序将尝试找到最准确的匹配项。
下面我们开始写代码。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img_rgb = cv2.imread('SourceIMG.jpeg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('TemplateIMG.jpeg', 0)在上述代码中,我们使用OpenCV读取SourceIMG.jpeg和TemplateIMG.jpeg。
height, width = template.shape[::]模板图像会在整个源图像上滑动,对整个区域进行搜索(将左上角作为参考框)。模板图像与源图像匹配后,我们记下左上角的位置,然后在实际匹配的区域周围绘制一个框。为此,我们需要知道此模板图像的高度和宽度。下面我们来绘制矩形。
res = cv2.matchTemplate(img_gray, template, cv2.TM_SQDIFF)模板匹配是OpenCV提供的功能,它利用源图像和模板图像的灰度图像,计算我们需要的统计指标。这里我使用的是最小平方差(TM_SQDIFF),因为我们寻找的是模板图像和源图像之间的最小差。
plt.imshow(res, cmap='gray')如果将到目前为止的结果绘制成图,就会得到一个概率图。从下图可以看到,这些小点是模板实际匹配的位置。

min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)我们可以使用上面的代码从概率图中找出小点的位置。然后使用minMaxLoc(res)提取最小值、最大值、最小值的位置和最大值的位置。
top_left = min_loc
bottom_right = (top_left[0] + width, top_left[1] + height)
cv2.rectangle(img_rgb, top_left, bottom_right, (255, 0, 0), 2)为了在模板图像匹配的源图像上绘制一个蓝色矩形,我们需要获得最小值的位置min_loc(该位置为匹配开始的位置)作为左上角。同样,我们可以通过top_left[0] + width和top_left [1] + height获得右下角。通过这些尺寸,我们可以使用cv2.rectangle绘制蓝色矩形。
一切准备就绪,下面我们进行可视化。
cv2.imshow("Matched image", img_rgb)
cv2.waitKey()
cv2.destroyAllWindows()
完整的代码:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img_rgb = cv2.imread('SourceIMG.jpeg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('TemplateIMG.jpeg', 0)
height, width = template.shape[::]
res = cv2.matchTemplate(img_gray, template, cv2.TM_SQDIFF)
plt.imshow(res, cmap='gray')
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
top_left = min_loc #Change to max_loc for all except for TM_SQDIFF
bottom_right = (top_left[0] + width, top_left[1] + height)
cv2.rectangle(img_rgb, top_left, bottom_right, (255, 0, 0), 2)
cv2.imshow("Matched image", img_rgb)
cv2.waitKey()
cv2.destroyAllWindows()
检测多个物体:在给定阈值下进行检测
上述我们已经完成了单个物体的检测,即选择源图像和模板图像之差的最小值。通过定义阈值的方法,我们可以检测所有与模板图像相似的物体。
为此,我将使用与上例相同的源图像和模板图像,并设置阈值为概率大于0.5(你可以查看res数组来确定阈值)。我们只需要更改几行代码即可检测多个物体。
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)在这里,我使用TM_CCOEFF_NORMED,因为我们需要获取最大值,而不是最小值。这意味着我们需要寻找多个物体而不是一个。
threshold = 0.5 #For TM_CCOEFF_NORMED, larger values means good fit
loc = np.where( res >= threshold)我们要查找所有大于阈值的位置值。loc接收2个输出数组,并将这些数组组合在一起,这样就可以获得x,y坐标。
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + width, pt[1] + height), (255, 0, 0), 1)
这里有多个位置。因此,我们需要针对所有位置绘制蓝色矩形。下面我们来进行可视化。
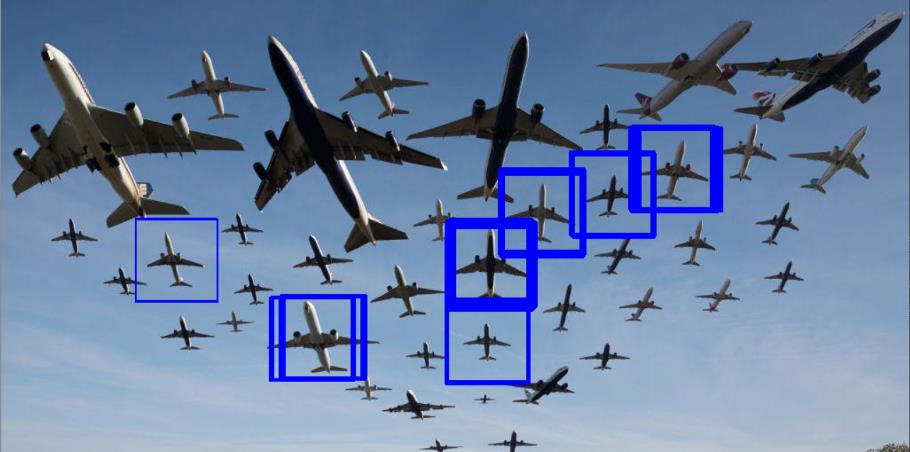
完整的代码:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img_rgb = cv2.imread('SourceIMG.jpeg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('TemplateIMG.jpeg', 0)
height, width = template.shape[::]
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
plt.imshow(res, cmap='gray')
threshold = 0.5 #For TM_CCOEFF_NORMED, larger values = good fit.
loc = np.where( res >= threshold)
for pt in zip(loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + width, pt[1] + height), (255, 0, 0), 1)
cv2.imshow("Matched image", img_rgb)
cv2.waitKey()
cv2.destroyAllWindows()
看起来很简单吧?但是如果我们使用机器学习或框架,则可以达到更高的准确性。
感谢您的阅读,希望本文对您有所帮助。
原文:https://towardsdatascience.com/object-detection-on-python-using-template-matching-ab4243a0ca62
- End -
以上是关于放弃机器学习框架,如何用Python做物体检测?的主要内容,如果未能解决你的问题,请参考以下文章
物体检测学习笔记-三种深度学习框架;PyTorchTensorflowCaffe