机器学习工作流程第一步:如何用Python做数据准备?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习工作流程第一步:如何用Python做数据准备?相关的知识,希望对你有一定的参考价值。
这篇的内容是一系列针对在Python中从零开始运用机器学习能力工作流的辅导第一部分,覆盖了从小组开始的算法编程和其他相关工具。最终会成为一套手工制成的机器语言工作包。这次的内容会首先从数据准备开始。
—— 来自Matthew Mayo, KDnuggets
似乎大家对机器学习能力的认知总是简单到把一系列论据传送到越来越多的数据库和应用程序界面中,接着就期待能有一些神奇的结果出现。可能你对在这些数据库里究竟发生了什么有自己很好的理解—— 从数据准备到建模到结果演示呈现等等,但不得不说你依然需要依赖于这些纷繁的工具去完成自己的工作。

这其实很正常。我们用被准确检验证明过能运行的工具来完成一些日常的任务是无可厚非的。重新发明使用那些不能有效滚动的轮子不是最好的办法。这样会有很多局限,也会浪费很多的不必要的时间。无论你是使用开放源代码还是被授权的工具来完成你工作,这些代码工具已经被很多人反复试用升级以确保当你上手使用的时候能够以最好的质量完成你的工作。
然而,有些苦活累活你自己做也是有价值的,即便是作为一种教育性的努力。我不是要推荐你们从零开始通过自己深度学习练习写出一个程序框架,至少不能一直这样,但哪怕只有一次通过不断的试验和失败,从头开始写出和自己的算实现它们的支持工具也是非常好的。我可能说的不对,但我认为如今在学习机器学习能力、数据科学、人工智能等方面的大多数人都没有在这么做。
所以让我们从头开始,来学习在Python里建立一些机器学习能力的相关知识。
“From Scratch” 究竟是什么意思?
首先,我先申明:当我提到“From Scratch”,我的意思是尽可能少的借助外界的帮助。当然这也是相对的,但是为了达成我们的目标,我会划定界限,当我们在写自己的矩阵模型、数据框或者构建自己的数据库时,我们会分别使用Python中的numpy、panda和matplotlib库。在某些情况下,我们甚至不会使用这些库的全部功能。我们稍后会讨论,让我们先暂时放一放它们的名字以便大家更好的理解。在Python自带的库中自带的功能原则上都是可以使用的,但除此之外,我们就要自己来写了。
我们需要从一个点入手,那就让我们从一些简单的数据准备任务开始吧。开始的时候我们会慢一点,但当我们对(要学习的东西)有了一点感觉以后,我们会逐渐加快速度。除了数据准备,我们还需要数据转换、结果演示和呈现工具——更不必说机器学习能力算法了——来达成我们我们即将要完成的目标。
我们的想法是手动拼接任何我们需要的重大功能,以便完成我们的机器学习能力任务。当序列展开的时候,我们可以添加新的工具和算法,同时我们也能重新思考我们以前的假设(是否正确),使整个过程尽可能重复迭代,就像它会渐近一样。慢慢的,我们会集中精力在我们的目标上,制定策略来完成目标,把它们运用到Python里,再检验它们是否能够运行。
最终的结果,就想我们现在预期的一样,会是有序排列在我们自己的简易的机器学习数据库中的一系列简单的Python模型。对于初学者,我相信这是理解机器学习过程、工作流和算法如何运行的非常宝贵的经验。
工作流(workflow)究竟是什么意思?
工作流对不同的人意味着不同的意思,但是我们这里说的工作流指的是机器学习项目中的一部分。我们有很多过程框架来帮助我们追踪我的工作进程,但现在让我们简化到一下的这些:
-
获取数据
-
处理/准备数据
-
建立模型
-
解释呈现结果
在我们真正做的时候我们可以拓展,但是这是我们现在自己设计的简单的机器学习的过程框架。同时,“输送管(小箭头)”暗含了把工作流中各功能聚集在一起的能力,所以让我们把这些记住然后继续向前。
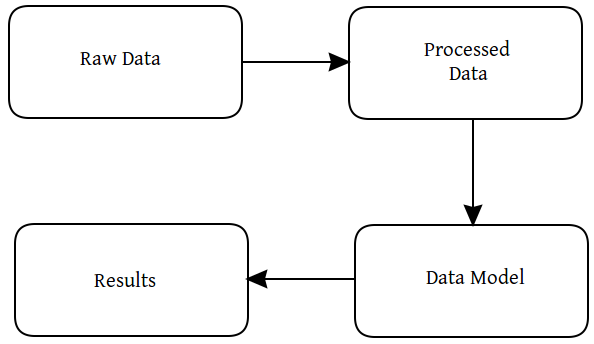
获得数据
在我们建立自己的模型之前,我们需要一些数据,还需要确认这些数据与我们合理的期望相符合。为了检测的目的(而不是训练或测试,但只是测试我们自己的设备),我们会使用虹膜数据集,你可以从这里下载。尽管我们可以在网上找到很多版本的数据集,但我建议我们都使用相同的原始数据,以确保我们的准备工作正常运行。
让我们来看一看:

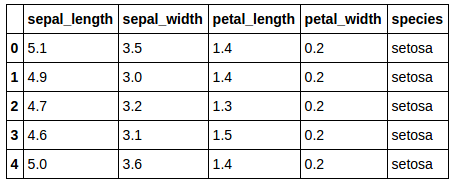
既然我们已经知道了这个简单的数据集和它对应的文件,我们先来想一想我们需要做什么使原始数据演变成我们想要的结果:
-
数据需要储存成CSV格式的文件
-
实例大部分由有数字属性的值组成
-
组别是经过分组的内容http://www.wmyl15.com/
到目前为止,以上没有一种是对所有的数据集都适用的,但是也没有任何一个是只能适用于某一种数据集的。这使得我们能够有机会编写我们可以以后重复使用的代码。好的编程练习会让我们集中于重复利用性和模块性。
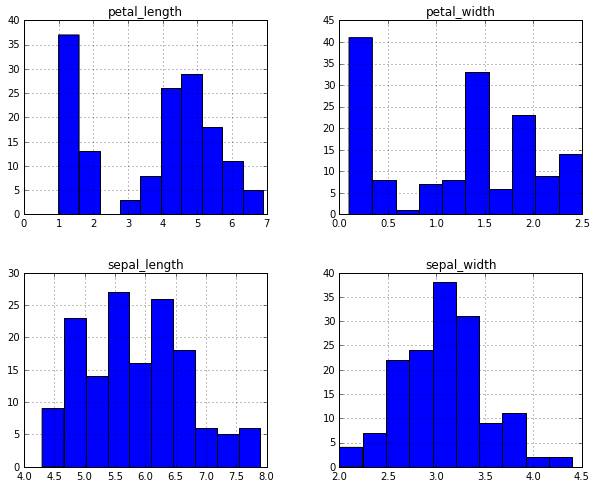
一些简单的探索性数据分析被罗列如下:
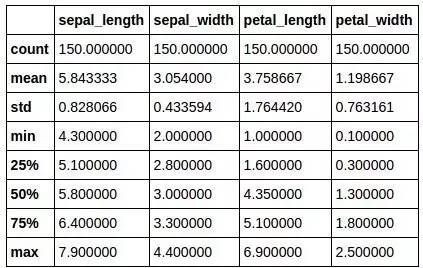
(上图为具体数值,下图为图像化数据)
准备数据
虽然数据准备在我们现在这个特定的情境中需要的很少,但是有时还是会需要。尤其是我们需要确认我们解释了标题行,去除了任何pandas呈现出来的参数,并且把我们的每一次组的值从名字型的转化成数值型的。因为在我们使用模型时已经没有名字性数值了,所以到此为止至少就没有更复杂的转化了。
最终,我们也需要一个对我们自己的算法的更好的数据呈现,所以我们在继续向前进行之前会确保我们最终呈现的是一个矩阵——或者numpy nadarry。我们的数据准备工作流接下来会做一下的表格:
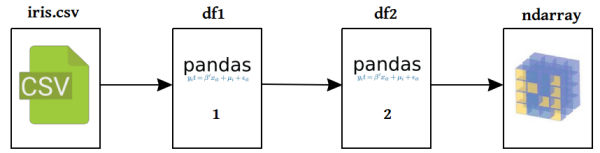
同时,我们需要主要我们没有理由相信所有有趣的数据都会被储存在被逗号分开的文件里。我们可能希望能够从一个SQL数据库里或者直接从网上获取数据,从这两个地方找到的数据我们以后还能返回去回看。
首先,让我们写一个简单的函数,把一个CSV文件上传到DataFrame。当然,这在内网做很容易,但是再往前想一步我们可能想再加一些额外的步骤到我们自己的数据集里以便我们以后上载函数。

这个编码是相当直接的。一行一行的读数据文件就完成了一些额外的预先加工,比如忽略了那些内容非数据的行(我们认为在数据文件中评价是由井号键开始的,尽管这很荒谬。)我们可以详细说明这个数据集文件是否包括标题,我们也可以接受csv和tsv文件,csv文件是默认的设置。
有一些错误检查存在,但它还并不是很健全,所以我们或许可以晚一点再回来说这个话题。此外,逐条读文件再逐条决定要对这些行做什么,比直接用内置功能把处理干净的一致的cs一文件直接读到DataFrame中要慢,但权衡之后我们发现允许更多的灵活性,在这一阶段是值得的(但读大的文件可能会发花费很久的时间)。不要忘了,如果一部分内置操作不是最好的方法,我们可以晚一些再做调整。
在我们尝试运行自己的编码之前,我们需要来写一个函数,把名字类数值转化成数字类数值。为了推广函数,我们需要使它能够用于数据集中的任何属性的数值,不仅仅是运用于不同的类别。我们还应该跟踪属性名称最终是否成为了整数。有了之前把csv或ts me的数据文件上传pandas的DataFrame的步骤经验,这个函数应该同时接受一个pandas DataFrames以及被转化为数字的属性名称。
我们还要注意,我们回避了关于使用单热编码的话题,这涉及到分类的非分类属性,但我认为我们以后还会回到这个话题。

上述的函数又是一个简单的,但是能帮助我们完成目标函数。我们可以用很多不同的方式来完成这个任务,包括使用pandas内置的功能,但是让你从一些会让你有些累的苦差事开始做就是这个函数的意义。
现在我们可以从文件中加载一个数据集,然后把分类属性值转换成数字属性值(我们也可以保留这些映像在字典中供以后使用)。就像之前提到的,我们希望我们的数据集最终是以numpy ndarry的形式存在,这样我们可以在自己的算法中很简单的使用。同样的,这是一个简单的任务,但写一个函数会让我们在以后需要的时候还可以以此为准。
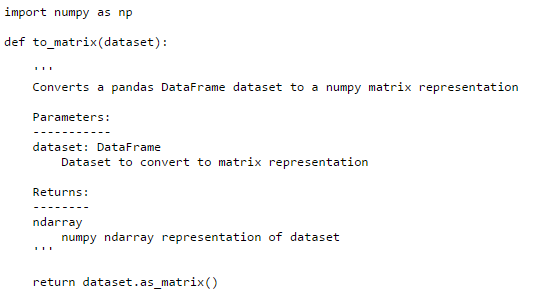
即使以前任何的功能都没有过度的杀伤力,但这个功能有可能有。但请忍耐我,我们遵守非常全面的编程准则--如果过于谨慎的话。在我们继续往下讲的过程中会有很好的机会让我们对已有的功能做改变或添加。这些变化如果能在一个地方实施并且记录在案,从长远来看非常有意义。
测试数据准备的工作流
我们的工作流迄今为止可能仍然是构建板块的形式,但让我们给自己的编码一个测试。


我们的代码正在按我们希望的方式工作,让我们做一些简单的房屋清理工作。一旦开始滚动,我们将为我们的编码提供一个更全面的组织结构,但是现在我们需要把所有这些功能加到一个单独的文件中,并保存成为dataset.py的格式。这会让我们以后的使用更方便,下次我们会学到。
未来计划
之后我们会学习简单的分类算法,k最近邻算法。我们会学习如何在简单的工作流中构建分类和聚类模型。毫无疑问,这需要编写一些限额外的工具来帮助我们完成项目,并且我确定我们还将对已经做完的部分进行修改。
练习机器学习就是理解机器学习的最好方法。运用我们的工作流中需要的算法和支持工具最终会被证明是有用的。
以上是关于机器学习工作流程第一步:如何用Python做数据准备?的主要内容,如果未能解决你的问题,请参考以下文章