如何用Python教机器学会牛顿第二定律?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Python教机器学会牛顿第二定律?相关的知识,希望对你有一定的参考价值。
牛顿第二定律的常见表述如下:
物体加速度的大小跟作用力成正比,跟物体的质量成反比,且与物体质量的倒数成正比。
结合我们所学过的牛顿第二定律,我们知道物体的加速度a和作用力F之间的关系应该是线性关系,于是我们提出假设 a=w∗F,并进行5次实验,统计到不同的作用力下木块加速度如下表所示:

我们很快就能得出w为2,通过大量实验数据的训练,我们便可以确定参数w是物体质量的倒数(1/m)
这是人的思维,换作机器,我们改怎么才能让机器确定模型的参数w就是物体质量的倒数呢?
机器如一个机械的学生一样,只能通过尝试答对(最小化损失)大量的习题(已知样本)来学习知识(模型参数w),期望用学习到的知识w组成完整的模型H(θ,X),使模型能回答不知道答案的考试题(未知样本)
在牛顿第二定律的案例中,基于对数据的观测,我们提出的是线性假设,即作用力和加速度是线性关系,用线性方程表示。
因此,在教机器学习牛顿第二定律之前,我们先要创建牛顿第二定律的实验数据:
def creat_npy():
arr = []
for i in range(1,1001):
arr.append(i)
arr.append(2 * i)
arr = np.array(arr)
# print(arr)
np.save(arr.npy, arr)
creat_npy()

我们先用列表的形式创建实验数据,每条数据包括2项,分别是加速度与作用力,第0-1项是第一条数据,第2-3项是第二条数据,…
这样的数据肯定是不能直接用的,我们需要对数据进行处理:
def load_data():
data = np.load(arr.npy)
feature_names = [ F, a ]
feature_num = len(feature_names)
# print(data.shape[0])
data = data.reshape([data.shape[0] // feature_num, feature_num])
ratio = 0.8
offset = int(data.shape[0] * ratio)
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
这里取了80%的数据作为训练集,20%的数据作为样本集
接下来,我们开始定义神经网络,神经网络能干什么?
简单来说,向网络中输入一个值(x),乘以权重,结果就是网络的输出值。对于牛顿第二定律,可以理解为,输入加速度a,乘以权重w,输出作用力F。
那么我们怎么样获取权重呢?
一般来说,我们会把权重设置为一个随机数,而权重可以随着网络的训练进行更新,从而找到最佳的值,这样网络就能尝试匹配输出值与目标值。
我们怎么更新权重才能使它变成我们的期望值?
讲到这里,我们就要进行分析了,这里我们用机器实际生成的权重举例:
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)

可以看到,机器刚开始的权重w是1.77,那么加速度a乘以权重w会得到作用力F为1.77,因为第一个加速度的值为1,可我们期望得到的作用力Fa为2,这里有-0.23的差距:

这里的error肯定是越趋近于0越好,因此我们要想办法使作用力F尽可能地趋近于期望作用力Fa,要想改变作用力F,就必须改变权重,而碰巧的是,现在的权重减去error不就是我们期望的权重吗?
这样想确实没错,像这种比较简单的线性关系里一步到位很简单,可在很多情况下,比如密码学里的函数是十分复杂的,因此我们必须一步一步来,即梯度下降,慢慢地接近正确答案。
这里就要讲到学习率,人的学习是循序渐进的,机器也一样,这里我们设置学习率为0.01:

我们用excel就可以表示出来这其中的关系:

下面来看看如何用代码去实现它:
def update(self, x, y, eta):
z = self.forward(x)
gradient_w = z - y
self.w = self.w - eta * gradient_w
print("权重w:",self.w)
个人认为这是最关键的一步,建议在草稿纸上自己试一下,原理搞明白了再回来看代码:
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
def forward(self, x):
z = np.dot(x, self.w)
# print("作用力F:",z)
return z
def loss(self, z, y):
error = z - y
print("error:",error)
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
print("cost:",cost)
return cost
def update(self, x, y, eta):
z = self.forward(x)
gradient_w = z - y
self.w = self.w - eta * gradient_w
print("权重w:",self.w)
def train(self, x, y, eta):
z = self.forward(x)
print("作用力F:",z)
L = self.loss(z, y)
self.update(x, y, eta)
return L
明白原理后,代码就好写了,下面是训练的代码:
# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(1)
# 启动训练
losses = []
for i in range(len(x)):
print("加速度a:",x[i])
print("实际作用力Fa:",y[i])
loss = net.train(x[i],y[i], eta=0.01)
if loss == 0:
break
losses.append(loss)
print(losses)
下面是训练的结果:


可以看到,权重在慢慢趋近于2,到达2以后便不再增长:

最后画个图来看一下:
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()

下面是全部代码,可能有写得不好的地方,欢迎大家批评指正!
import numpy as np
import matplotlib.pyplot as plt
def creat_npy():
arr = []
for i in range(1,1001):
arr.append(i)
arr.append(2 * i)
print(arr)
arr = np.array(arr)
print(arr)
np.save(arr.npy, arr)
creat_npy()
def load_data():
data = np.load(arr.npy)
feature_names = [ F, a ]
feature_num = len(feature_names)
# print(data.shape[0])
data = data.reshape([data.shape[0] // feature_num, feature_num])
ratio = 0.8
offset = int(data.shape[0] * ratio)
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
def forward(self, x):
z = np.dot(x, self.w)
# print("作用力F:",z)
return z
def loss(self, z, y):
error = z - y
print("error:",error)
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
print("cost:",cost)
return cost
def update(self, x, y, eta):
z = self.forward(x)
gradient_w = z - y
self.w = self.w - eta * gradient_w
print("权重w:",self.w)
def train(self, x, y, eta):
z = self.forward(x)
print("作用力F:",z)
L = self.loss(z, y)
self.update(x, y, eta)
return L
# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(1)
# 启动训练
losses = []
for i in range(len(x)):
print("加速度a:",x[i])
print("实际作用力Fa:",y[i])
loss = net.train(x[i],y[i], eta=0.01)
if loss == 0:
break
losses.append(loss)
print(50*"-")
print(losses)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
如何用两个晚上教女生学会Python
文章目录
事情的起因是这样的,知乎上有个妹纸加我,说要相亲。尽管我欣喜若狂,但恰巧在外出差,根本走不开。妹纸于是说要不教她编程吧,为了在相亲之前留个好印象,我使出了浑身解数,希望在短时间内让一个毫无编程经验的萌妹纸,掌握Python的基本用法。
安装、需求引导和开发模型
古人云,授人以鱼不如授人以渔,但对于卖课程的人来说,他若真的把“渔”授人了,那他自己的“鱼”也就卖不出去了。这个“渔”,就是快速学习一门编程语言的方法。
而这个方法的核心,就是用需求引导取代知识灌输
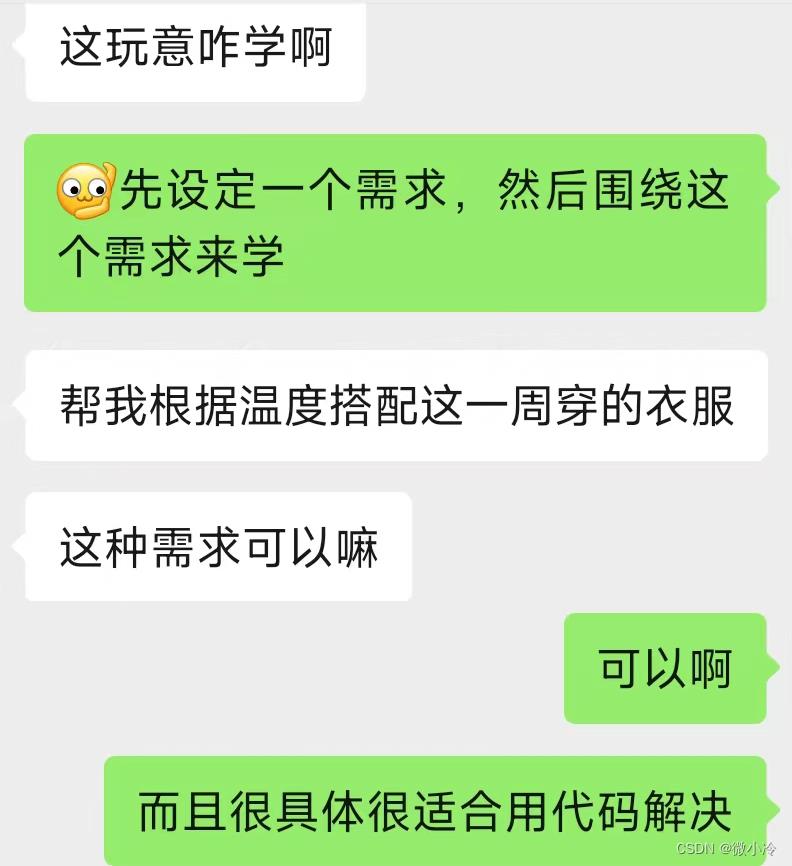
一旦建立起项目观念,同时项目进度和学习进度同步推进,那么二者前进的过程,也会变得无比丝滑。
所以接下来,就是要完成这个基本的需求:如何做一个可以挑选衣服的功能。
这个功能可简单、可复杂,对于新手而言,却可以成梯次地拆分成不同的任务需求,每个需求对应一个知识点,随着知识点的增多,需求也不断增多,一定程度上就相当于是瀑布模型的简化版了。
而万事开头难,在确定学习目标后,第一步就是安装Anaconda。在此前,我一向认为这步相对来说比较复杂,故而更推荐在线的IDE,例如这个:在线Jupyter编辑工具。
但在一对一指导的情况下,推荐在线工具过于敷衍,故而一步到位,直接建议安装Anaconda,清华源按照时间排序,拉到最下方,下载2022.05-Windows-x86_64版本。安装过程意外地顺利,基本上出去走一圈就装好了。

命令行计算器
装好Anaconda之后,就可以愉快地使用命令行了。按下Win+r,输入cmd,然后回车,就可以进入命令行。
在命令行中输入python,就可以进入Python的交互环境,然后就可以按照直觉,进行四则混合运算了
x = 100
y = 50
z = 2.5
print(x + y * z) # 在python中,用#注释,注释就是不会被执行的文字
print(x - y / z) # print,将括号中的结果打印到屏幕上
print(x * y**2) # **表示乘方
就是说,就算只是当作计算器,使用Python也是不亏的。
对于一些复杂的计算,可以自行定义函数,比如
def GouGu(x,y):
return (x**2+y**2)**(1/2)
其中,def是函数的关键字,这个函数表示输入x,y,输出一个(x**2+y**2)*(1/2),就是勾股定理,相当于
z = x 2 + y 2 z=\\sqrtx^2+y^2 z=x2+y2
需要注意,Python中,通过缩进组织代码,在GouGu这个函数中的所有内容,必须保持相同的缩进,否则就相当于是跳到了函数之外。
在定义好函数之后,就可以在命令行中调用
>>> GouGu(3,4)
5
用温度指导穿衣
在开启Python,稍微尝试一下计算功能后,就要开始带来第一波刺激,实现根据温度筛选衣物。
t = 15
if t > 20 :
print('天气较热,穿薄一点')
elif t < 0:
print("天气较冷,穿厚一点")
else:
print("天气适宜,随便穿")
这就是所谓的条件语句,根据温度不同,实现了一个最基本的穿衣建议。非常神奇的是,这段代码我貌似并没有给她讲解,但她明白是什么意思。
但需要再次注意,Python中通过缩进来组织代码,在if, elif, else这三个关键字冒号的后面,必须进行相同的缩进,Python才能正常工作。
总之,在后续的编程学习中,缩进这两个字出现的频率相当之高。
这里面涉及到的另一个知识点就是字符串,在python中,单引号或者双引号内部的字符,将被识别为字符串,字符串和数值是两种截然不同的东西,这种不同可以从python内置的运算符重载看出端倪
1+1 # 显然等于2
'1'+'1' # 结果为'11'
如果仅仅是做一个if...elif...else语句,那么只能判断一次温度,这个太蠢了,为了随时调用,可以将这个逻辑压入一个函数中
def howToDress(t):
if t > 20 :
print('天气较热,穿薄一点')
elif t < 0:
print("天气较冷,穿厚一点")
else:
print("天气适宜,随便穿")
结合函数的知识,可以进一步理解缩进,即if, elif, else是相对于def进行的缩进;而那三个print则是相当于条件语句的缩进。
这样,就可以更加方便地进行穿衣指导了
>>> haoToDress(15)
天气适宜,随便穿
VS Code 和女孩子的衣柜
在本节之前,一直通过命令行交互地进行Python练习,这没毛病,但显然无法做一个项目,因为命令行不会把敲过的命令留存下来。
Anaconda提供了Python的IDE,Spider;也提供了交互式记事本Jupyter,但均非长久之计。考虑到她无比顺畅地完成了Anaconda的安装,那么关于编辑器的选择,自然也要一步到位,上VS Code。
VS Code的安装过程也非常顺利,第一次打开会提示安装中文语言包,安装即可。
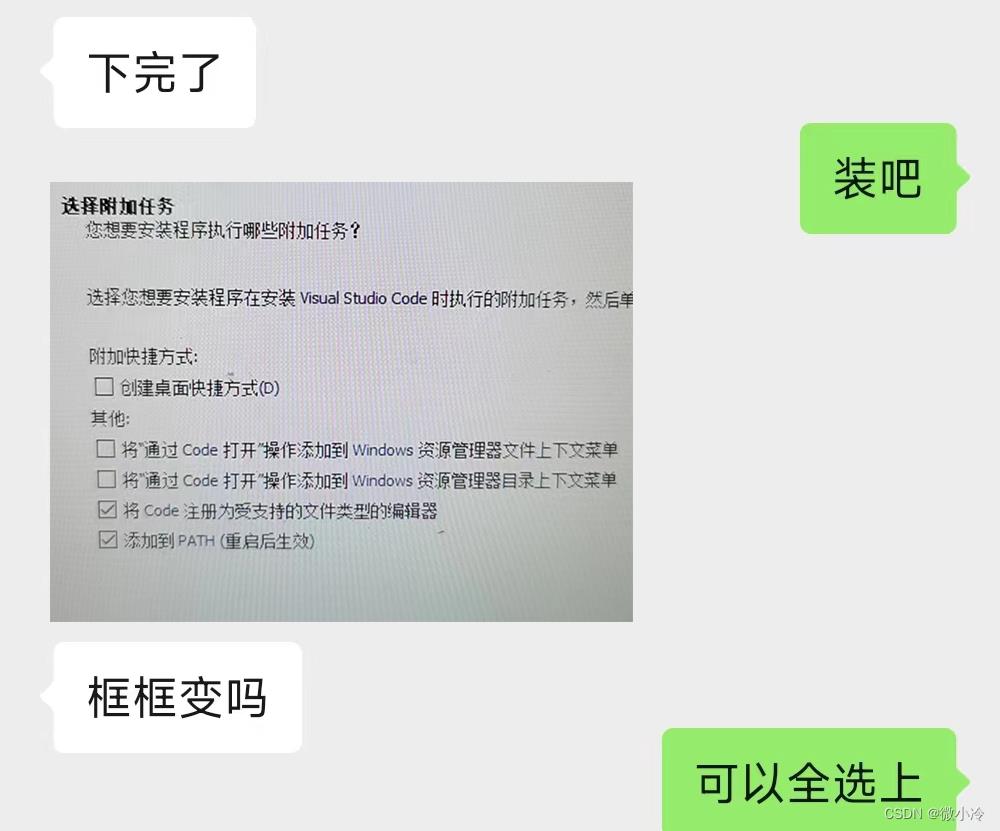
接下来,新建一个文件夹,以后所有的代码都存放在这个文件夹里,然后用VS Code打开这个文件夹,右键这个文件夹,并新建一个.py文件。VS Code会自动检测到py文件,按照提示,安装Python扩展。由于她只给了我这个截图,说明后续的过程都是顺利的。
接下来,如本节标题所说,要把女孩子的衣柜写入这个.py文件中。
而衣柜的前提是有一件衣服,那么如何在Python中描述一件衣服呢?
答案是字典,或者说键值对列表,通过键和值的一一对应,在描述客观事物属性的同时,也实现了对属性值的快速索引。
dress =
"name":"羊羔绒外套",
"color":"白色",
"style":"外套"
"low_temp":-5,
"high_temp":8,
首先,这是一个名为字典的变量,里面包含了各种属性,比如"name", “color"等,每个属性都对应一个值,这个值可以是字符串,比如"color"是"白色”,也可以是数值,比如"low_temp"为-5,表示温度高于-5°时可以穿。
如想单独提出dress的某个属性,可用方括号索引
print(dress['color']) #"白色"
如想运行.py文件,只需在命令行中输入python XXX.py,便可以运行python脚本。VS Code中是自带命令行的,只需按下Ctrl+~就可以出现。关于这个我忘了说,以至于她一直在那个“黑黑的”命令行中操作。
所谓“衣柜”,就是一个装着各种衣服的列表,所谓列表,就是用[]罗列着的内容,如果用字典来理解列表,就相当于是以自然数为键的字典。
而后她十分兴奋,说这不得写几个小时,吓得我大惊失色,说先稍微列出几个做测试就行,等以后学了面向对象,直接就用类来做了,最后得到了一个衣柜的demo,如下。

与字典的键值索引类似,列表采取自然数索引,例如
print(clothes[0]) # 将输出羊羔绒外套这个字典
用遍历来挑选衣物
有了衣柜,有了选衣服的逻辑,就可以实现一个最基础的选择衣服的函数。这个需求也来一步一步做,还是先完善通过温度选择衣物的方法
def whichDress(t):
selected = []
for cloth in clothes:
if cloth['low_temp'] < t < cloth['high_temp']:
selected.append(cloth)
return selected
其中,cloth['low_temp'] < t < cloth['high_temp']这种写法是在我没有做任何说明的情况下,她自己写的。这一方面说明她是个挺有天赋的妹纸,同时也说明Python是一款非常甜的语言(指语法糖超多)。
但她对append是干啥的不理解,所以我让她做如下测试
a = []
a.append("b")
print(a) # ["b"]
a.append("c")
print(a) # ["b", "c"]
整段函数的逻辑就是,输入一个温度,然后遍历clothes字典,挑选出所有符合温度要求的衣服,最后输出。
for...in语句非常直观,以for cloth in clothes为例,就是将clothes列表中所有的内容,按次赋给cloth,这就是所谓的遍历。
当然,for...in最常用的方法应该是结合range,实现对自然数的遍历,上面的那个遍历过程也可以写为
for i in range(len(chothes)):
print(clothes[i])
其中,len可以得到clothes的元素个数,至于range是什么,可以用下面的表达式试一下
for i in range(5):
print(i)
交互
能够做到这个程度,妹纸就已经非常兴奋了,毕竟能够用温度来选择衣物,也就意味着能够用其他特征来筛选衣物。接下来要完成的,就是另一个重要的内容:交互。
我们常见的程序都是通过图形界面来完成交互,但对于新人程序媛来说,这显然不太现实,所以这种交互,也是建立在命令行之上的。
在python中,通过print将字符串打印到命令行,反过来,通过input来从命令行请求值,例如
>>> t = input("请输入温度")
请输入温度15
>>> print(t)
15
有了这个,就可以做到交互式的衣物择取,但这里有一个知识点,即通过input得到的值,是一个字符串,尽管看上去15是个数字,但只是伪装成数字的字符串罢了,如果想进行计算或者比较,必须通过int或者float使之变成整数或者小数。
>>> t + 1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
>>> int(t)+1
16
>>> float(t)+1
16.0
查看报错信息,也是编程学习过程中不可或缺的任务,Python的报错信息已经非常人性化了,TypeError为数据类型错误,后面说只能把字符串(str)和字符串拼接起来,而不能是int。换句话说,在t+1这样的一个表达式中,+根据t的数据类型,自动表现为字符串拼接的意思,但因为数据类型不同,而无法实现。
有了这个功能,就可以实现手动输入温度,并给出可选衣物。如果将这样的一个逻辑写入一个死循环中,就可以选择多种温度下的情况
while True:
t = input("请输入温度")
dress = whichDress(int(t))
print(dress)
在这步操作时,如果忘了写input,而恰好前面某个地方又给t赋了值的话,就会导致命令行疯狂地不间断地输出,这时不必慌张,更不用关掉命令行,只需按下Ctrl+C就可以了
课后作业
最后,留下一个妹纸在调试过程中出现的小问题,如果您阅读并实现了本文的操作,看看能不能找出问题的所在
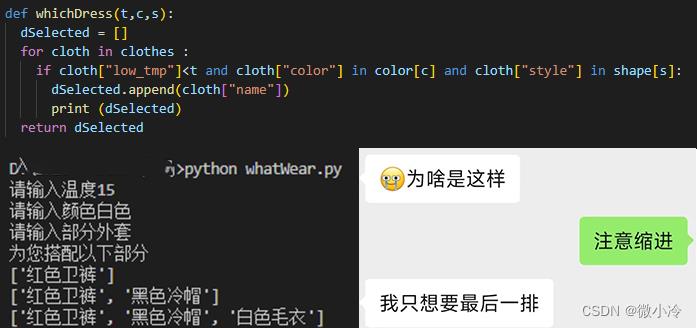
至此,妹纸已经基本学会了Python,所以最近的一个多月都没怎么回我消息了,她一定是在准备相亲吧,我们以后的孩子是学Python还是学C++呢?

以上是关于如何用Python教机器学会牛顿第二定律?的主要内容,如果未能解决你的问题,请参考以下文章